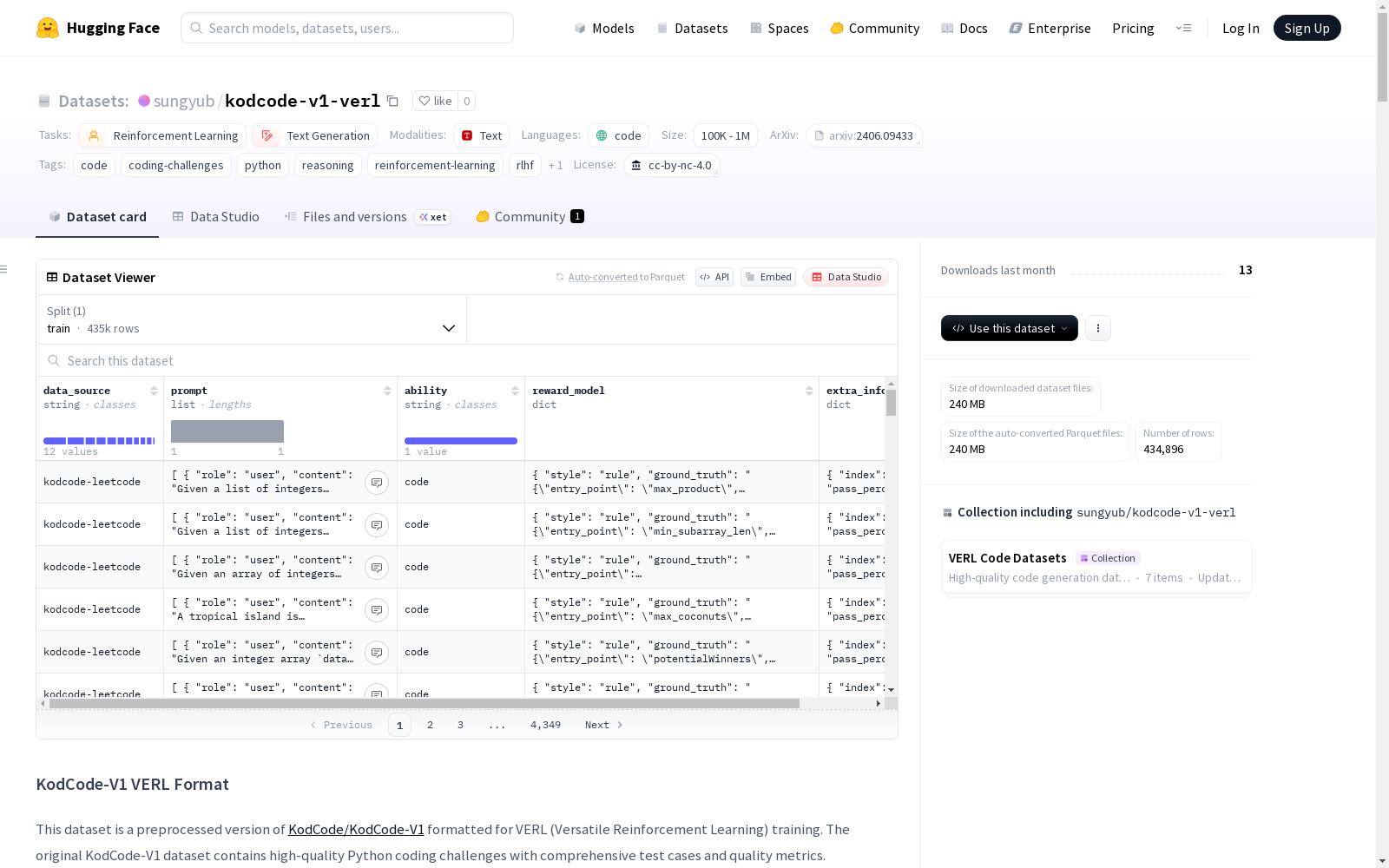
kodcode-v1-verl
收藏KodCode-V1 VERL Format 数据集概述
数据集基本信息
- 名称: KodCode-V1 VERL Format
- 来源: https://huggingface.co/datasets/KodCode/KodCode-V1
- 原始论文: https://arxiv.org/abs/2406.09433
- 格式: VERL兼容模式,适用于强化学习训练
- 许可证: CC-BY-NC-4.0(仅限非商业用途)
- 语言: 代码(Python)
- 规模: 434,896个训练样本
- 保留率: 89.8%(从原始484,097个样本中保留)
数据结构
核心字段
data_source: 数据源标识符(字符串)prompt: 提示信息列表(仅用户角色)ability: 任务类型(始终为"code")reward_model: 奖励模型信息extra_info: 额外信息
详细结构
python prompt: [ { role: user, content: 编码挑战/问题描述 } ] reward_model: { style: rule, ground_truth: 包含测试用例的JSON字符串 } extra_info: { index: 示例索引, pass_percentage: GPT-4通过率, test_coverage: 测试覆盖率, pass_trial_num: 通过试验次数, original_difficulty: 难度等级, original_subset: 源子集, question_id: 原始问题标识符, test_parsed: 测试用例解析状态 }
数据来源分布
- Leetcode: 竞争性编程挑战
- HumanEval: 标准代码生成基准
- Docs: Python库文档示例
- TACO: 额外编码挑战
质量指标
- 通过百分比: GPT-4在问题上的成功率(0.0-1.0)
- 通过试验次数: 成功的GPT-4试验计数
- 测试覆盖率: 选定解决方案试验的代码覆盖率
- 难度等级: 简单、中等或困难(GPT-4评估)
数据准备流程
处理步骤
- 从KodCode/KodCode-V1流式加载源数据
- 将pytest断言转换为LeetCode风格的检查函数
- 映射到VERL格式并强制执行键排序
- 保留原始质量指标
- 通过PyArrow模式转换确保结构一致性
测试用例生成
- 从原始测试代码解析pytest断言
- 转换为
check(candidate)函数格式 - 将函数名称替换为
candidate参数 - 在
ground_truth字段中编码为JSON
使用方式
加载数据集
python from datasets import load_dataset dataset = load_dataset("sungyub/kodcode-v1-verl", split="train")
流式加载(内存高效)
python dataset = load_dataset("sungyub/kodcode-v1-verl", split="train", streaming=True)
过滤和子集
按难度过滤
python easy_examples = dataset.filter( lambda x: x[extra_info][original_difficulty] == easy )
按质量过滤
python high_quality = dataset.filter( lambda x: x[extra_info][pass_percentage] > 0.5 )
按来源过滤
python leetcode_only = dataset.filter( lambda x: x[extra_info][original_subset] == Leetcode )
技术特性
字典键排序
- 使用PyArrow模式转换强制执行一致的字典键排序
prompt消息键顺序:[role, content]reward_model键顺序:[style, ground_truth]
测试用例验证
- 测试用例从pytest格式解析但未预先验证
- 训练期间通过沙箱执行进行验证
排除标准
- 无法从测试元数据中提取函数名称
- 测试用例解析失败
- 必需字段缺失
保留统计
- 总保留:434,896 / 484,097(89.8%)
- 成功解析测试用例:394,336(81.5%)
- 因缺少函数名称排除:49,201(10.2%)
- 解析失败:40,560(8.4%)
相关数据集
- https://huggingface.co/datasets/sungyub/skywork-or1-code-verl
- https://huggingface.co/datasets/sungyub/eurus-2-code-verl
- https://huggingface.co/datasets/KodCode/KodCode-V1
版本信息
- 版本: 1.0
- 发布日期: 2025-11-03
- 特点: 初始发布,模式统一,测试用例转换,质量指标保留