alia_intellectual_property
收藏ALIA_INTELLECTUAL_PROPERTY 数据集概述
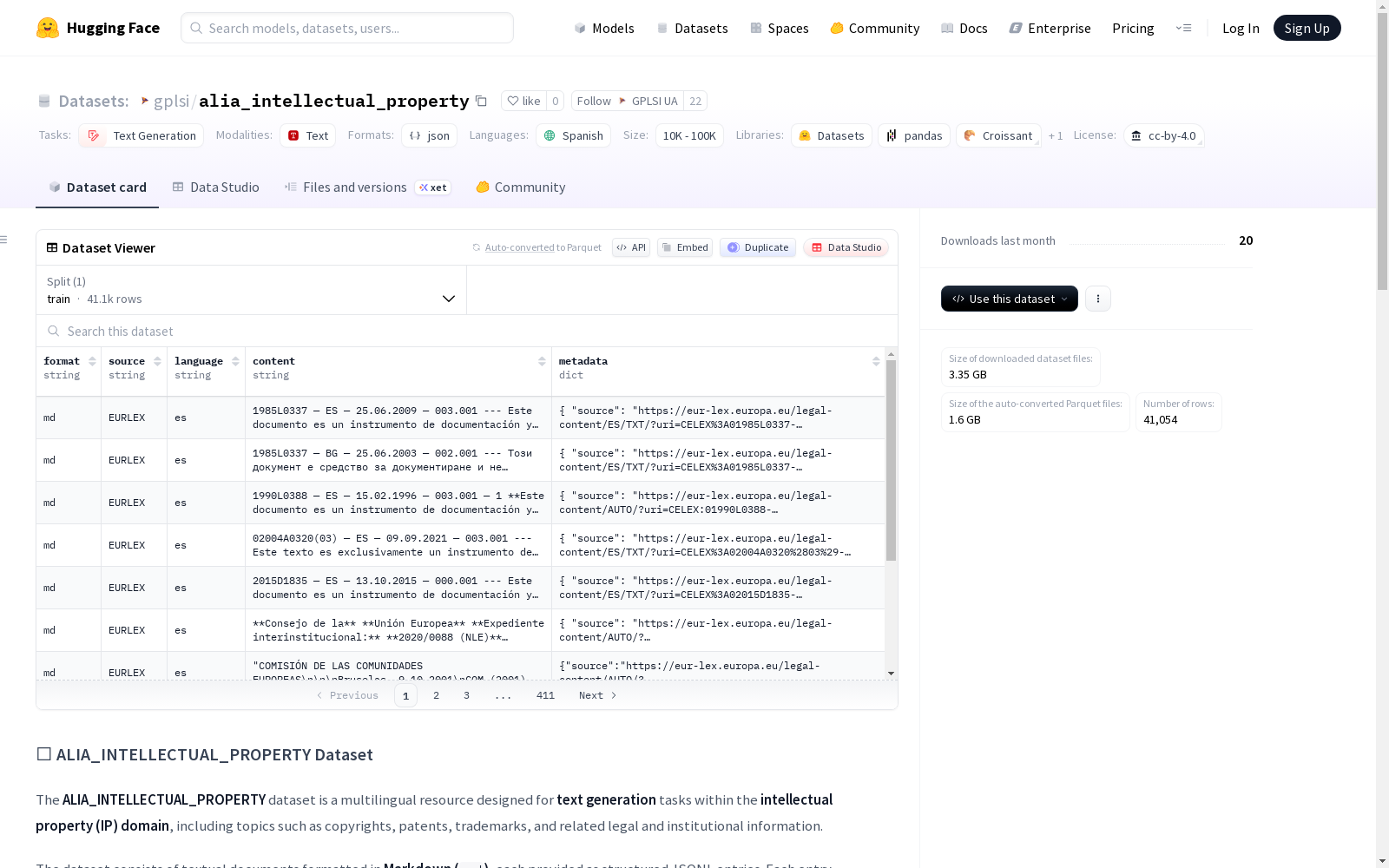
基本信息
- 数据集名称: ALIA_INTELLECTUAL_PROPERTY
- 任务类别: 文本生成
- 主要语言: 西班牙语 (es)
- 数据规模: 10K<n<100K
- 许可证: Creative Commons Attribution 4.0 International (CC BY 4.0)
数据集描述
ALIA_INTELLECTUAL_PROPERTY 数据集是一个多语言资源,专为知识产权(IP)领域的文本生成任务而设计,涵盖版权、专利、商标及相关法律和机构信息等主题。
数据格式与结构
- 数据格式: JSON Lines (
.jsonl) - 文本格式: Markdown (
.md) - 每条记录包含字段:
format: 文本格式,所有条目均为"md"(Markdown)。source: 文档来源(机构、网站或项目)。language: 内容语言,为"es"(西班牙语)。text: Markdown 格式的主要文本内容。metadata: 补充信息的对象。
数据构成
- 语言: 西班牙语
- 领域: 知识产权(版权、专利、商标及相关法律框架)
- 内容: 每个项目代表一个独立的知识产权相关文本。
数据来源
eurlex-es-md.jsonl: 使用关键词 "intellectual property" 从 EUR-Lex (Spanish) 过滤出的内容。
重要说明
- 该数据集是从知识产权相关来源自动整理的。
- 不同条目的元数据覆盖范围可能有所不同。
- 内容可能包含用于结构的 Markdown 格式(例如标题、列表、强调)。
资助信息
本工作由 Ministerio para la Transformación Digital y de la Función Pública 资助,并由 EU – NextGenerationEU 共同出资,属于 Desarrollo de Modelos ALIA 项目框架。
引用格式
@misc{alia2025intellectualproperty, author = {Espinosa Zaragoza, Sergio and Maestre, Mar{i}a Mir{o} and Mu{~n}oz Guillena, Rafael and Consuegra-Ayala, Juan Pablo}, title = {ALIA_INTELLECTUAL_PROPERTY Dataset}, year = {2025}, institution = {Language and Information Systems Group (GPLSI) and Centro de Inteligencia Digital (CENID), University of Alicante (UA)}, howpublished = {url{https://huggingface.co/datasets/gplsi/alia_intellectual_property}} }
免责声明
请注意,数据可能包含偏见或其他非预期的失真。当第三方基于此数据部署系统或提供服务,或自行使用该数据时,他们需承担减轻任何相关风险并确保遵守适用法规(包括管理人工智能使用的法规)的责任。阿利坎特大学作为数据集的拥有者和创建者,不对第三方使用所产生的任何后果承担责任。
许可证
本作品采用 Creative Commons Attribution 4.0 International (CC BY 4.0) 许可证。