WildScore
收藏arXiv2025-09-05 更新2025-09-09 收录
下载链接:
https://huggingface.co/datasets/GM77/WildScore
下载链接
链接失效反馈官方服务:
资源简介:
WildScore是一个基于真实音乐乐谱的多模态符号音乐推理与分析基准数据集,旨在评估多模态大型语言模型(MLLMs)在解读现实世界音乐乐谱和回答复杂音乐学问题方面的能力。每个WildScore实例都是从真实的音乐作品中获取的,并伴随着来自公共论坛的真实用户生成的问题和讨论,捕捉了实际音乐分析的复杂性。为了促进系统的评估,我们提出了一个系统的分类法,包括高级和细粒度的音乐学本体论。此外,我们将复杂的音乐推理框架为多项选择题回答,使MLLMs的符号音乐理解能够进行可控和可扩展的评估。
WildScore is a multimodal symbolic music reasoning and analysis benchmark dataset grounded in real musical scores, designed to evaluate the capabilities of multimodal large language models (MLLMs) in interpreting real-world musical scores and answering complex musicological questions. Each WildScore instance is derived from authentic musical works, paired with real user-generated questions and discussions from public forums, which captures the complexity of practical music analysis. To facilitate systematic evaluation, we propose a systematic taxonomy encompassing high-level and fine-grained musicological ontologies. Furthermore, we frame complex music reasoning as multiple-choice question answering, enabling controllable and scalable evaluation of symbolic music understanding for MLLMs.
提供机构:
加利福尼亚大学圣地亚哥分校
创建时间:
2025-09-05
原始信息汇总
WildScore数据集概述
基本信息
- 名称:WildScore
- 许可证:CC-BY-4.0
- 支持语言:英语(en)
- 标签:音乐(music)
- 数据规模:小于1K(n<1K)
配置信息
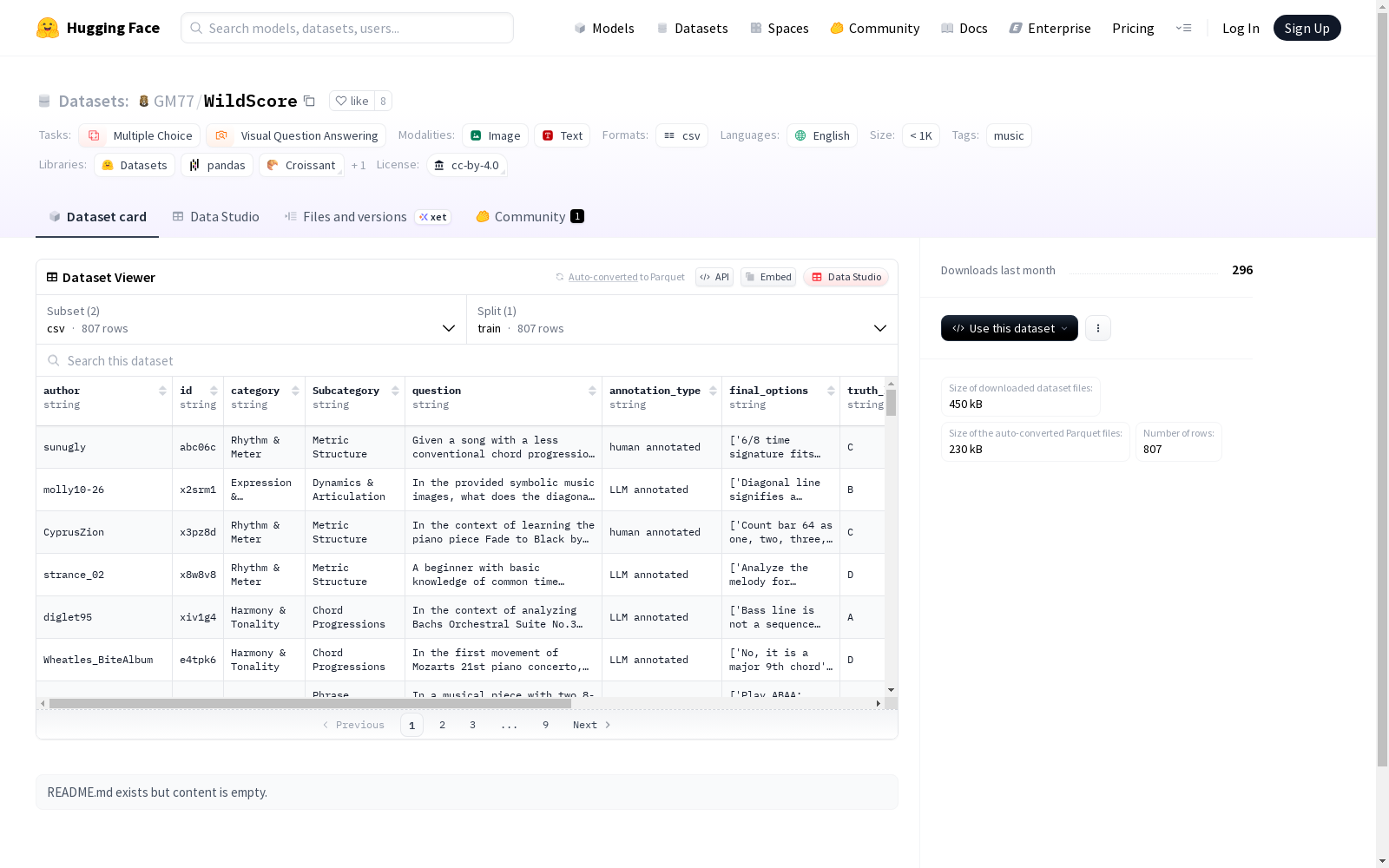
- 配置1:csv
- 数据文件:data.csv
- 配置2:imagefolder
- 数据目录:images
任务类别
- 多项选择(multiple-choice)
- 视觉问答(visual-question-answering)
搜集汇总
数据集介绍
构建方式
WildScore数据集构建过程分为数据采集与多模态过滤两个阶段。数据源自2012至2022年间r/musictheory子论坛的真实用户讨论,通过Reddit官方API提取包含乐谱图像的帖子及其一级评论。采用基于YOLO架构的符号音乐检测器对4000张候选图像进行筛选,并结合内容长度限制(≤200词)及互动门槛(≥3条评论)进行质量过滤,最终获得807个高质量多模态样本。每个样本通过GPT-4.1-mini将原始问题重构为多项选择题,并依据Reddit投票机制与语言模型协同确定标准答案。
使用方法
WildScore支持多模态(图像+文本)与纯文本两种评估模式,以多项选择准确率作为核心指标。研究者可将乐谱图像与对应问题输入多模态大语言模型,要求模型从候选答案中选择正确答案。评估时需区分视觉上下文依赖型问题与纯理论推理问题,以量化模型在符号感知与音乐推理方面的独立能力。数据集提供标准化评估脚本及基于音乐类别的分层分析工具,支持跨模型性能对比与错误归因分析,尤其适用于检验模型对复杂音乐结构的跨模态推理能力。
背景与挑战
背景概述
WildScore由加州大学圣地亚哥分校的研究团队于2025年提出,是首个针对多模态大语言模型在真实场景下符号音乐推理能力的基准数据集。该数据集源自Reddit论坛r/musictheory版块2012至2022年间的用户讨论,包含807个真实乐谱图像与对应的音乐学问题,覆盖和声、节奏、织体、表现力及曲式五大核心领域。其创新性在于将社区驱动的音乐分析转化为结构化多选问答任务,为评估模型在复杂音乐符号理解与上下文推理能力提供了标准化框架,填补了多模态音乐推理领域的空白。
当前挑战
WildScore需解决符号音乐多模态推理的双重挑战:领域层面,模型需同步解析乐谱视觉符号与音乐理论语义,例如从复杂节奏型中推断拍号结构或从和声进行中识别调性转换;构建层面,需克服真实用户问题的模糊性与主观性,通过Reddit投票机制与语言模型协同标注确保答案可靠性,同时设计符合音乐学逻辑的干扰项以维持评估严谨性。
常用场景
经典使用场景
在音乐信息检索与多模态推理研究中,WildScore数据集被广泛用于评估多模态大语言模型对真实世界乐谱图像的理解能力。研究者通过该数据集构建的多选题问答任务,系统检验模型在和谐与调性、节奏与节拍、织体、表现与演奏、曲式等核心音乐理论范畴上的推理表现,尤其关注模型从复杂乐谱视觉符号中提取语义信息并完成多步逻辑推理的能力。
解决学术问题
WildScore解决了多模态音乐推理领域缺乏标准化评估基准的学术问题,填补了传统符号音乐数据集(如MusicNet、MAESTRO)仅关注音频对齐或转录任务的局限性。它首次将真实社区讨论中的音乐学问题转化为结构化评估任务,为量化模型在音乐符号感知、跨模态对齐和领域特异性推理等方面的能力提供了可靠框架,推动了音乐人工智能的可解释性研究。
实际应用
该数据集的实际应用涵盖智能音乐教育、自动化乐谱分析工具和交互式音乐学习系统。例如,可集成于在线音乐教育平台,通过解析用户上传的乐谱图像并生成针对性的音乐理论问题,提供即时反馈;在专业音乐制作中,辅助音乐学家快速分析复杂乐片段的和谐进程或节奏结构,提升音乐文献研究的效率。
数据集最近研究
最新研究方向
在符号音乐理解领域,WildScore数据集的推出标志着多模态大语言模型(MLLMs)在真实世界音乐推理任务中的评估迈入新阶段。该数据集源自Reddit社区的真实音乐讨论,涵盖和声、节奏、织体、表现力及曲式五大核心音乐理论范畴,通过多选问答形式系统检验模型对乐谱图像与自然语言问题的协同解析能力。当前前沿研究聚焦于提升MLLMs对复杂音乐符号的视觉感知与高层语义推理的融合,尤其在节奏计量、对位织体等需多步推理的子任务中,现有模型仍面临显著挑战。这一方向不仅推动了音乐信息检索与计算音乐学的发展,更为跨模态推理技术在艺术领域的应用提供了关键基准。
相关研究论文
- 1WildScore: Benchmarking MLLMs in-the-Wild Symbolic Music Reasoning加利福尼亚大学圣地亚哥分校 · 2025年
以上内容由遇见数据集搜集并总结生成


