Code-170k-bemba
收藏Hugging Face2025-10-23 更新2025-10-24 收录
下载链接:
https://huggingface.co/datasets/michsethowusu/Code-170k-bemba
下载链接
链接失效反馈官方服务:
资源简介:
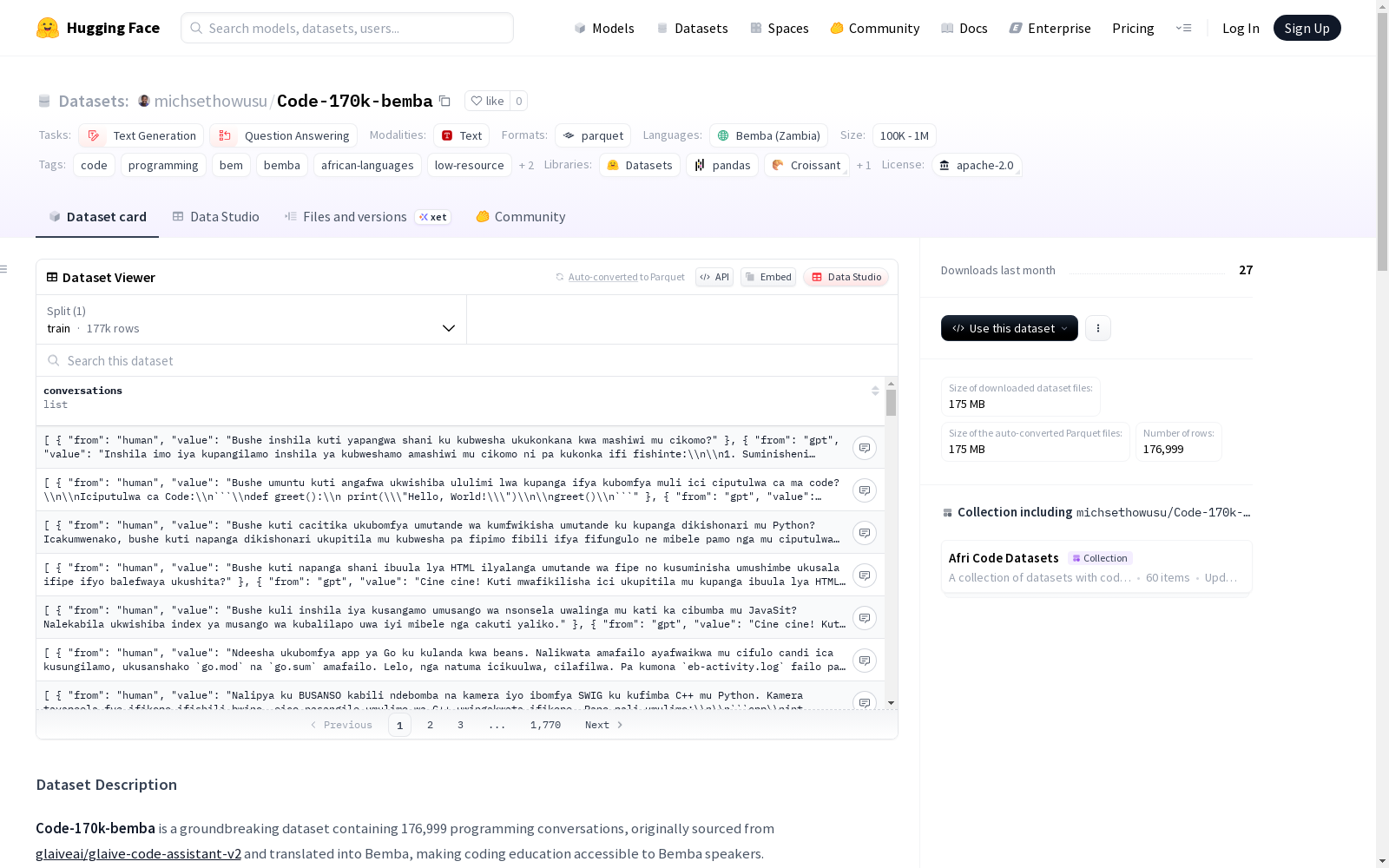
Code-170k-bemba是一个包含176,999个编程对话的数据集,这些对话最初来源于glaiveai/glaive-code-assistant-v2,并翻译成奔巴语,使得编程教育对奔巴语使用者变得触手可及。该数据集包含了关于编程和编码的高质量对话,全部使用奔巴语,涵盖多轮对话,涉及各种编程概念,话题包括算法、数据结构、调试、最佳实践等,并且适用于大型语言模型的指令调整。
创建时间:
2025-10-19
原始信息汇总
Code-170k-bemba 数据集概述
基本信息
- 数据集名称: Code-170k-bemba
- 数据集地址: https://huggingface.co/datasets/michsethowusu/Code-170k-bemba
- 许可证: Apache 2.0
- 语言: 本巴语 (bem)
- 任务类别: 文本生成、问答
- 规模分类: 100K<n<1M
数据集规模
- 训练集样本数量: 176,999
- 训练集大小: 340,471,720 字节
- 下载大小: 170,235,860 字节
核心特征
- 数据来源: 基于glaiveai/glaive-code-assistant-v2数据集翻译
- 内容类型: 176,999个高质量编程对话
- 语言特性: 纯本巴语编程对话
- 对话结构: 多轮对话,涵盖各种编程概念
数据结构
数据字段
conversations: 对话轮次列表from: 说话者身份("human"或"gpt")value: 本巴语消息内容
数据示例
python { "conversations": [ { "from": "human", "value": "[本巴语问题]" }, { "from": "gpt", "value": "[本巴语回答]" } ] }
应用场景
- 训练本巴语编程助手
- 为本巴开发者构建教育工具
- 多语言代码生成研究
- 创建本巴语编程教程
- 支持低资源语言AI发展
主题范围
- 算法
- 数据结构
- 调试
- 最佳实践
- 其他编程概念
技术特性
- 适用于大型语言模型的指令调优
- 支持多语言编程教育
- 促进低资源语言的可访问性
搜集汇总
数据集介绍
构建方式
在低资源语言技术发展的背景下,Code-170k-bemba数据集通过精心设计的翻译流程构建而成。该数据集源自glaiveai/glaive-code-assistant-v2的原始编程对话,经过专业翻译转化为本巴语,涵盖了算法、数据结构及调试等多个编程主题。构建过程注重对话质量与语言准确性,最终形成包含176,999条多轮对话的标准化结构,为低资源语言社区提供了坚实的教育数据基础。
特点
本数据集在非洲语言技术资源稀缺的现状下展现出独特价值,其核心特点在于纯本巴语编程对话的全面覆盖。数据集包含高质量的多人交互对话,涉及编程概念与实践问题的广泛讨论。每条数据均以结构化对话形式呈现,明确标注提问与回答角色,支持多轮语义连贯性。这种设计不仅丰富了低资源语言的数字内容,更为本巴语开发者和学习者构建了完整的编程知识体系。
使用方法
针对多语言代码生成的研究需求,该数据集可通过Hugging Face生态系统直接加载使用。研究人员使用datasets库的load_dataset函数即可获取训练集,其中每个样本包含按说话者分类的对话序列。该数据适用于指令微调任务,能有效训练本巴语编程助手模型。在实际应用中,开发者可迭代访问对话轮次,构建面向教育场景的代码生成与问答系统,推动本土化编程教育工具的开发。
背景与挑战
背景概述
在人工智能与自然语言处理领域,低资源语言的技术支持长期面临资源匮乏的困境。Code-170k-bemba数据集于2025年由研究团队基于glaiveai/glaive-code-assistant-v2数据集构建,通过将17.7万条编程对话翻译为本巴语,致力于解决非洲本巴语使用者在编程教育中面临的语言障碍。该数据集聚焦于代码生成与问答任务,通过多轮对话覆盖算法、数据结构及调试等核心编程概念,为低资源语言地区的技术教育平等化提供了关键数据支撑,显著推动了多语言人工智能在编程教育领域的应用发展。
当前挑战
本数据集针对编程教育中的语言鸿沟问题,首要挑战在于如何克服低资源语言缺乏高质量技术语料库的局限,确保编程概念在本巴语中的准确表达与专业性。构建过程中面临双重困难:一方面需处理技术术语的跨语言对齐,保证翻译后代码逻辑的完整性;另一方面要维持对话数据的教育价值与语言自然度,避免因直译导致的语义失真。此外,大规模双语数据的质量控制与多轮对话结构的连贯性维护,亦是数据集构建中的核心难点。
常用场景
经典使用场景
在低资源语言技术发展领域,Code-170k-bemba数据集通过17万条本巴语编程对话,为构建本土化代码助手提供了核心训练素材。这些多轮对话涵盖算法设计、数据结构实现及调试技巧等编程核心概念,显著提升了本巴语开发者在自然语言交互中获取编程指导的体验。该资源特别适用于指导调优大语言模型,使模型能够以文化适配的方式响应技术问题。
实际应用
在实际教育场景中,本数据集已成为开发本巴语编程教学工具的核心组件。教育机构可基于此构建交互式编程教程,帮助母语者通过自然对话掌握编程逻辑。技术企业则利用这些数据训练本地化开发助手,为中部非洲地区培育数字人才,推动技术传播与产业创新的深度融合。
衍生相关工作
受该数据集启发,研究社区已衍生出多个本巴语技术项目,包括基于转换器的代码生成模型BembaCoder与跨语言编程教育平台UbuntuCode。这些工作通过融合传统语言学知识与现代深度学习技术,持续拓展非洲语言在智能教育系统、低资源机器翻译等方向的应用边界,形成良性技术生态。
以上内容由遇见数据集搜集并总结生成


