case-law
收藏Hugging Face2024-07-24 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/HFforLegal/case-law
下载链接
链接失效反馈官方服务:
资源简介:
Case-law 数据集是一个综合性的法律判决集合,来自不同国家,以统一格式集中存储。该数据集旨在通过提供一个标准化、易于访问的全球法律文件语料库,来改进法律AI模型的发展。数据集包括多个特征,如唯一标识符、标题、引用、案卷号、州、发行者、完整文档文本、用于验证的哈希值和时间戳。数据集按国家划分,使用ISO 3166-1 alpha-2代码,并包含用户应注意的伦理考虑。该数据集支持多项任务,包括问答、文本生成和表格问答。
创建时间:
2024-07-22
原始信息汇总
数据集概述
基本信息
- 语言: 法语, 英语
- 许可证: cc-by-4.0
- 任务类别: 问答, 文本生成, 表格问答
- 标签: 法律, 法律, 财政, 税收, 右, 法律, 法律
数据集结构
- 特征:
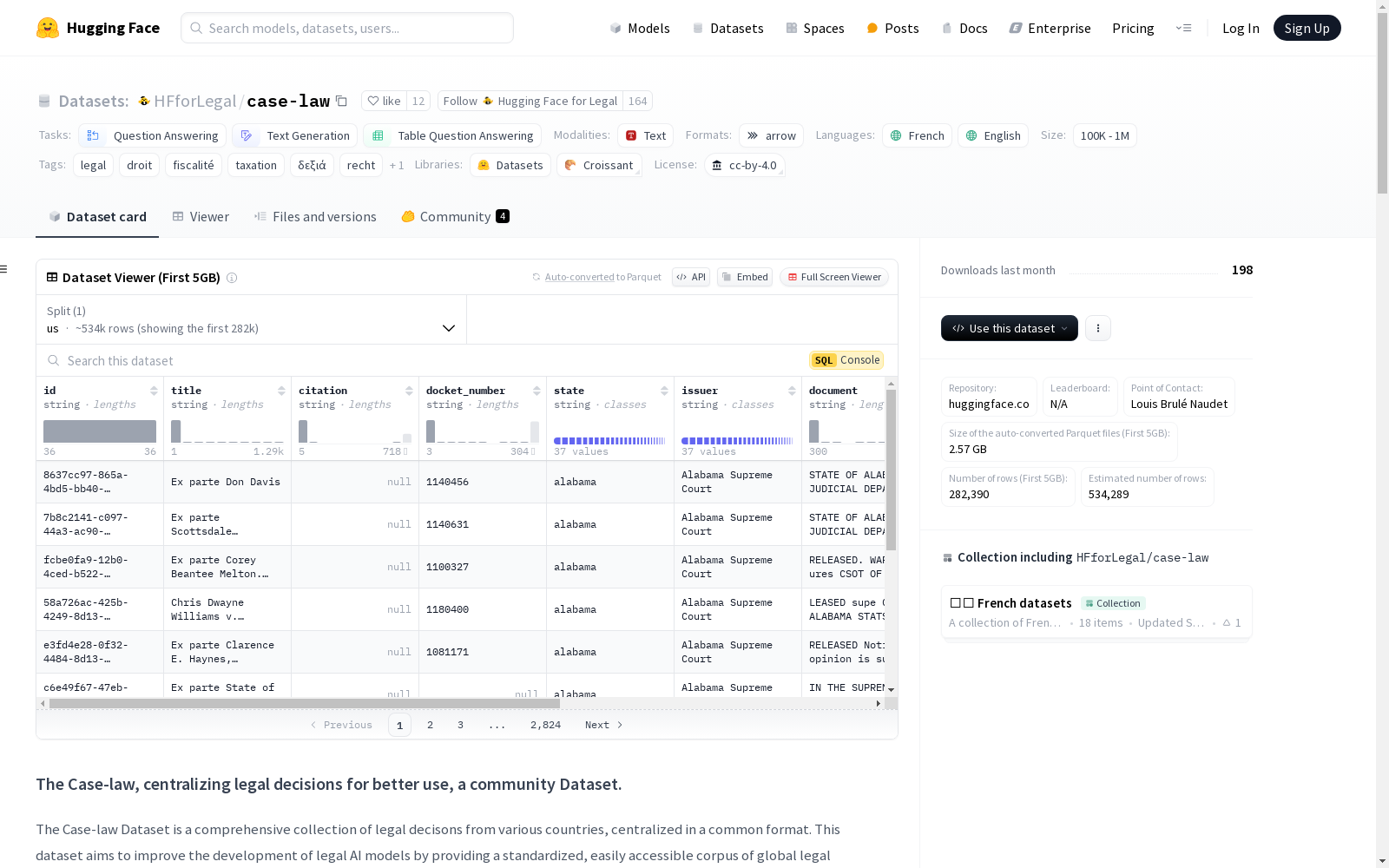
id: 字符串类型,文档的唯一标识符title: 字符串类型,法律文档的标题citation: 字符串类型,文档的引用信息docket_number: 字符串类型,法律案件或文档的案卷号state: 字符串类型,与文档相关的州或司法管辖区issuer: 字符串类型,发布文档的实体或权威机构document: 字符串类型,法律文档的完整文本内容hash: 字符串类型,文档的SHA-256哈希值,用于验证数据完整性timestamp: 字符串类型,指示文档创建、颁布或最后更新的时间戳
数据分割
- 分割:
us: 包含541371个样本,总字节数为9138869838
下载和数据集大小
- 下载大小: 4597435136字节
- 数据集大小: 9138869838字节
目标
- 主要目标: 集中世界各地的法律于通用格式,以促进:
- 比较法律研究
- 多语言法律AI模型的发展
- 跨司法管辖区的法律研究
- 改进法律技术工具
国家代码分割
- 国家代码: 使用ISO 3166-1 alpha-2代码来组织不同司法管辖区的法律文档。
伦理考虑
- 隐私: 确保所有个人信息已适当匿名化。
- 偏见: 注意源材料和所包含法律选择中可能存在的偏见。
- 时效性: 法律随时间变化,始终验证您正在使用最新版本的法律。
- 司法管辖区: 法律解释可能因司法管辖区而异,不应将基于此数据训练的AI模型用作专业法律建议的替代品。
引用
BibTeX @misc{HFforLegal2024, author = {Louis Brulé Naudet, Timothy Dolan}, title = {The case-law, centralizing legal decisions for better use}, year = {2024}, howpublished = {url{https://huggingface.co/datasets/HFforLegal/case-law}}, }
搜集汇总
数据集介绍
构建方式
Case-law数据集通过整合来自多个国家的法律判决,构建了一个标准化的全球法律文档语料库。数据集的构建过程包括从不同司法管辖区收集法律文件,并使用统一的格式进行整理。每个文档都包含唯一的标识符、标题、引用信息、案件编号、相关州或司法管辖区、发布机构、文档全文、SHA-256哈希值以及时间戳,以确保数据的完整性和可追溯性。数据集还通过ISO 3166-1 alpha-2国家代码进行分片,便于按国家访问特定法律文件。
使用方法
使用Case-law数据集时,用户可以通过Hugging Face的`datasets`库轻松加载数据。数据集支持按国家代码分片访问,用户只需指定相应的ISO 3166-1 alpha-2代码即可获取特定国家的法律文件。此外,数据集提供了详细的文档哈希验证功能,用户可以通过Python脚本对文档内容进行哈希计算,确保数据的完整性和一致性。数据集适用于法律AI模型的开发、跨法域法律研究以及法律技术工具的改进。
背景与挑战
背景概述
Case-law数据集由Louis Brulé Naudet和Timothy Dolan等人于2024年创建,旨在通过集中全球法律判决文本来推动法律人工智能的发展。该数据集涵盖了多个国家的法律文件,并以统一的格式呈现,便于进行跨国法律研究、多语言法律模型的开发以及法律技术工具的改进。其核心目标是通过标准化的法律文本数据,加速法律领域AI模型的开发,从而提升跨司法管辖区的法律分析能力。该数据集不仅为法律学者提供了丰富的研究资源,还为法律科技公司和技术开发者提供了重要的数据支持,推动了法律与人工智能的深度融合。
当前挑战
Case-law数据集在构建和应用过程中面临多重挑战。首先,法律文本的多样性和复杂性使得数据标准化和清洗成为一项艰巨任务,尤其是在跨司法管辖区和多语言环境下。其次,法律文件的时效性和更新频率要求数据集必须持续维护,以确保其内容的准确性和实用性。此外,隐私保护和数据匿名化也是构建过程中不可忽视的挑战,尤其是在涉及敏感信息的法律文件中。最后,法律领域的潜在偏见问题需要特别关注,以确保训练出的AI模型能够公正、客观地处理法律问题。这些挑战不仅影响了数据集的构建质量,也对后续的法律AI应用提出了更高的要求。
常用场景
经典使用场景
在法律领域,case-law数据集为研究人员和开发者提供了一个标准化的全球法律文本库,广泛应用于法律问答系统、文本生成和表格问答任务。通过整合多国法律判决,该数据集支持跨法域的法律比较研究,帮助开发多语言法律AI模型,提升法律技术工具的智能化水平。
解决学术问题
case-law数据集解决了法律研究中常见的跨法域比较难题,提供了统一的格式和标准化的法律文本,使得研究人员能够更便捷地进行多国法律文本的分析与对比。此外,该数据集还为法律AI模型的开发提供了丰富的训练数据,推动了法律文本生成、问答系统等技术的进步,显著提升了法律研究的效率和准确性。
实际应用
在实际应用中,case-law数据集为法律科技公司、律师事务所和司法机构提供了强大的支持。通过该数据集,企业可以开发智能法律助手,帮助用户快速检索相关法律条文和判例;律师事务所可以利用AI模型进行法律文书的自动生成和案例分析;司法机构则可以通过跨法域的法律文本分析,提升判决的公正性和一致性。
数据集最近研究
最新研究方向
近年来,随着人工智能技术在法律领域的广泛应用,case-law数据集成为推动法律AI模型发展的重要资源。该数据集通过集中全球多个国家的法律判决,为跨司法管辖区的法律研究提供了标准化、多语言的文本资源。当前的研究热点主要集中在利用该数据集开发多语言法律问答系统、法律文本生成模型以及跨司法管辖区的法律比较分析工具。这些研究方向不仅有助于提升法律AI模型的准确性和泛化能力,还为法律技术的创新提供了新的可能性。此外,随着全球法律体系的复杂性和多样性增加,case-law数据集在促进法律AI模型的伦理使用和公平性评估方面也具有重要意义。
以上内容由遇见数据集搜集并总结生成


