shibing624/AdvertiseGen
收藏Hugging Face2023-05-12 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/shibing624/AdvertiseGen
下载链接
链接失效反馈官方服务:
资源简介:
AdvertiseGen是电商广告文案生成数据集。该数据集以商品网页的标签与文案的信息对应关系为基础构造,是典型的开放式生成任务,在模型基于key-value输入生成开放式文案时,与输入信息的事实一致性需要得到重点关注。任务描述为给定商品信息的关键词和属性列表kv-list,生成适合该商品的广告文案adv。数据规模包括训练集114k,验证集1k,测试集3k,数据来源于清华大学CoAI小组。
AdvertiseGen是电商广告文案生成数据集。该数据集以商品网页的标签与文案的信息对应关系为基础构造,是典型的开放式生成任务,在模型基于key-value输入生成开放式文案时,与输入信息的事实一致性需要得到重点关注。任务描述为给定商品信息的关键词和属性列表kv-list,生成适合该商品的广告文案adv。数据规模包括训练集114k,验证集1k,测试集3k,数据来源于清华大学CoAI小组。
提供机构:
shibing624
原始信息汇总
数据集概述
数据集名称
AdvertiseGen
数据集描述
AdvertiseGen是一个电商广告文案生成数据集,基于商品网页的标签与文案的信息对应关系构造。该数据集关注模型在生成文案时与输入信息的事实一致性。
任务描述
给定商品信息的关键词和属性列表(kv-list),生成适合该商品的广告文案(adv)。
数据规模
- 训练集:114k
- 验证集:1k
- 测试集:3k
数据来源
清华大学CoAI小组
语言
数据集中的文本为中文。
数据集结构
数据实例
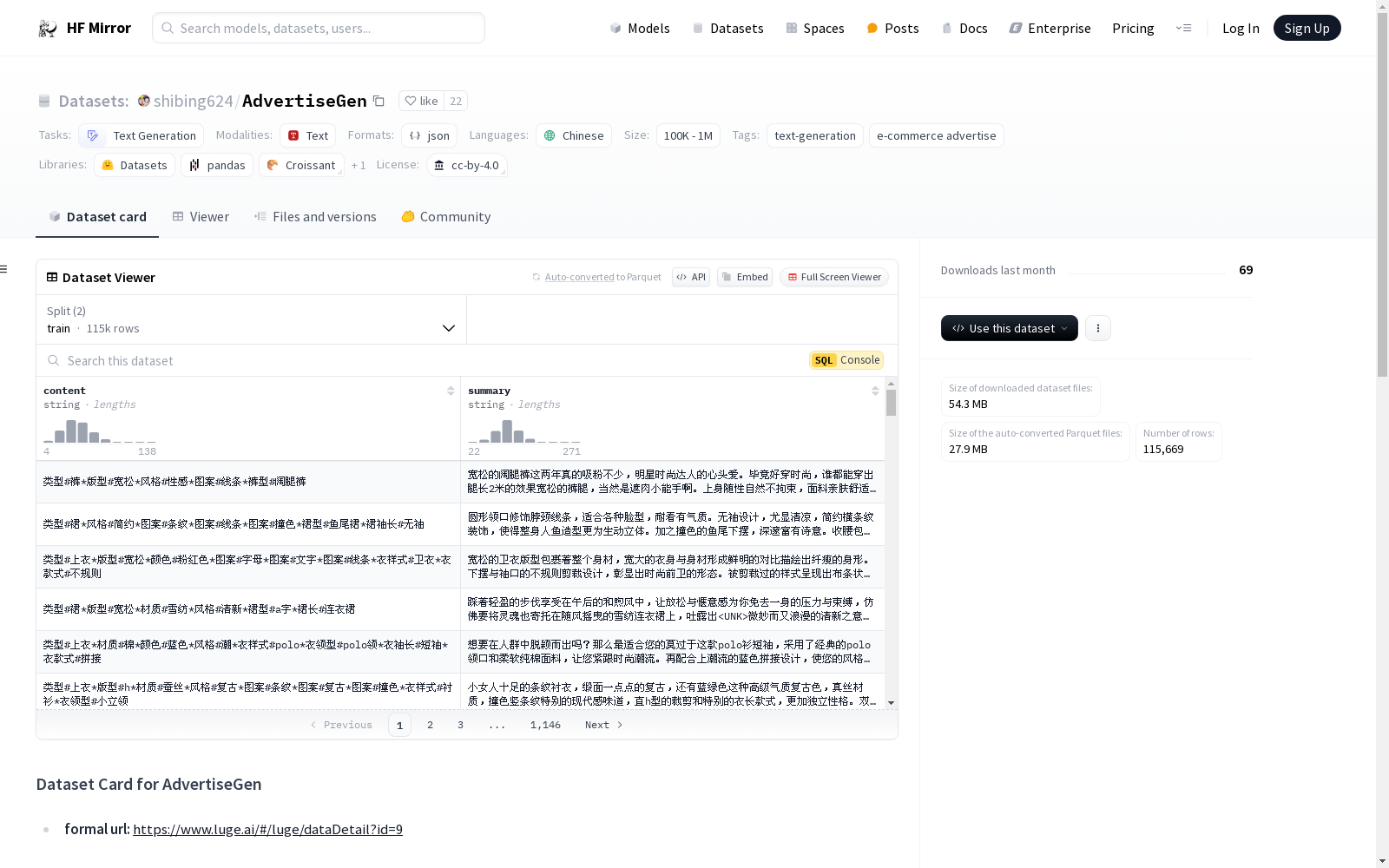
一个典型的训练数据实例如下: json { "content": "类型#上衣材质#牛仔布颜色#白色风格#简约图案#刺绣衣样式#外套衣款式#破洞", "summary": "简约而不简单的牛仔外套,白色的衣身十分百搭。衣身多处有做旧破洞设计,打破单调乏味,增加一丝造型看点。衣身后背处有趣味刺绣装饰,丰富层次感,彰显别样时尚。" }
引用信息
如在学术论文中使用本数据集,请引用以下文献:
Shao, Zhihong, et al. "Long and Diverse Text Generation with Planning-based Hierarchical Variational Model." Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 2019.
搜集汇总
数据集介绍
构建方式
AdvertiseGen数据集的构建基于电商平台商品网页的标签与文案信息,通过提取商品的关键词和属性列表(kv-list),生成与之对应的广告文案。该数据集由清华大学CoAI小组精心设计,旨在为开放式文本生成任务提供高质量的训练数据。数据集的构建过程注重信息的一致性和多样性,确保生成的广告文案能够准确反映商品特性。
特点
AdvertiseGen数据集的特点在于其专注于电商广告文案生成,数据规模庞大,包含114k条训练数据、1k条验证数据和3k条测试数据。每条数据均由商品的关键词和属性列表与对应的广告文案组成,文案风格多样,涵盖了从简约到复杂的多种表达方式。数据集的语言为中文,适用于中文文本生成任务,尤其是电商领域的广告文案生成。
使用方法
AdvertiseGen数据集的使用方法主要围绕电商广告文案生成任务展开。用户可以通过输入商品的关键词和属性列表,利用该数据集训练模型生成符合商品特性的广告文案。数据集提供了训练集、验证集和测试集,用户可以根据需求进行模型训练、验证和测试。此外,数据集还可用于评估生成文案与输入信息的一致性,帮助提升模型在开放式生成任务中的表现。
背景与挑战
背景概述
AdvertiseGen数据集由清华大学CoAI小组于2019年创建,旨在解决电商广告文案生成的核心问题。该数据集基于商品网页的标签与文案信息对应关系构建,专注于开放式生成任务,要求模型在给定商品关键词和属性列表的基础上,生成与之相符的广告文案。AdvertiseGen的推出为自然语言生成领域,特别是电商广告文案生成,提供了重要的研究资源,推动了相关技术的发展与应用。
当前挑战
AdvertiseGen数据集面临的挑战主要体现在两个方面。首先,在任务层面,模型需要在生成广告文案时确保与输入信息的事实一致性,这对生成内容的准确性和相关性提出了较高要求。其次,在数据构建过程中,如何从海量商品信息中提取有效的关键词和属性,并确保数据的高质量和多样性,是构建团队面临的主要难题。这些挑战不仅考验了数据处理能力,也对生成模型的性能提出了更高标准。
常用场景
经典使用场景
AdvertiseGen数据集在电商广告文案生成领域具有重要应用,特别是在基于商品属性生成创意广告文案的场景中。该数据集通过提供商品的关键词和属性列表,要求模型生成与之匹配的广告文案,这一任务不仅考验模型的文本生成能力,还要求生成内容与输入信息保持高度一致性。
实际应用
在实际应用中,AdvertiseGen数据集被广泛应用于电商平台的广告文案自动生成系统。通过利用该数据集训练的模型,电商平台能够快速生成与商品属性高度匹配的广告文案,提升广告的吸引力和转化率,从而优化用户体验并提高销售业绩。
衍生相关工作
AdvertiseGen数据集的发布催生了一系列相关研究工作,特别是在基于商品属性的广告文案生成领域。例如,Shao等人提出的基于层次变分模型的文本生成方法,利用该数据集进行了实验验证,展示了其在长文本生成和多样性控制方面的优势。这些研究进一步推动了电商广告文案生成技术的发展。
以上内容由遇见数据集搜集并总结生成


