ACPBench Hard
收藏arXiv2025-04-01 更新2025-04-03 收录
下载链接:
https://ibm.github.io/ACPBench
下载链接
链接失效反馈官方服务:
资源简介:
ACPBench Hard数据集是基于ACPBench构建的,由IBM Research创建。该数据集包含7种不同类型的推理任务,旨在将复杂的计划生成任务分解为独立的原子推理任务,以布尔问题或选择题的形式出现。ACPBench Hard是这些任务的生成版本,要求模型回答开放性问题。数据集适用于评估大型语言模型在自动规划器中作为组件的可靠性,涵盖多种规划领域,以帮助构建更高效的规划模型。
The ACPBench Hard dataset is built upon ACPBench and created by IBM Research. This dataset encompasses seven distinct types of reasoning tasks, which are designed to decompose complex plan generation tasks into independent atomic reasoning tasks, presented as either Boolean questions or multiple-choice questions. ACPBench Hard is the generative variant of these tasks, requiring models to answer open-ended questions. The dataset is intended to evaluate the reliability of Large Language Models (LLMs) as components in automated planners, covering multiple planning domains to help construct more efficient planning models.
提供机构:
IBM Research
创建时间:
2025-04-01
搜集汇总
数据集介绍
构建方式
ACPBench Hard数据集基于ACPBench构建,通过扩展原有7个任务并新增1个任务,采用开放生成式问题形式,以更精准地评估模型在规划任务中的推理能力。数据集基于13个规划领域定义语言(PDDL)领域,每个任务的问题均设计为生成式回答,要求模型直接输出符合规划需求的答案。为确保评估的准确性,每个问题均附带相应的PDDL规划任务描述,并针对不同任务设计了专门的验证算法,以高效验证模型输出的正确性。
特点
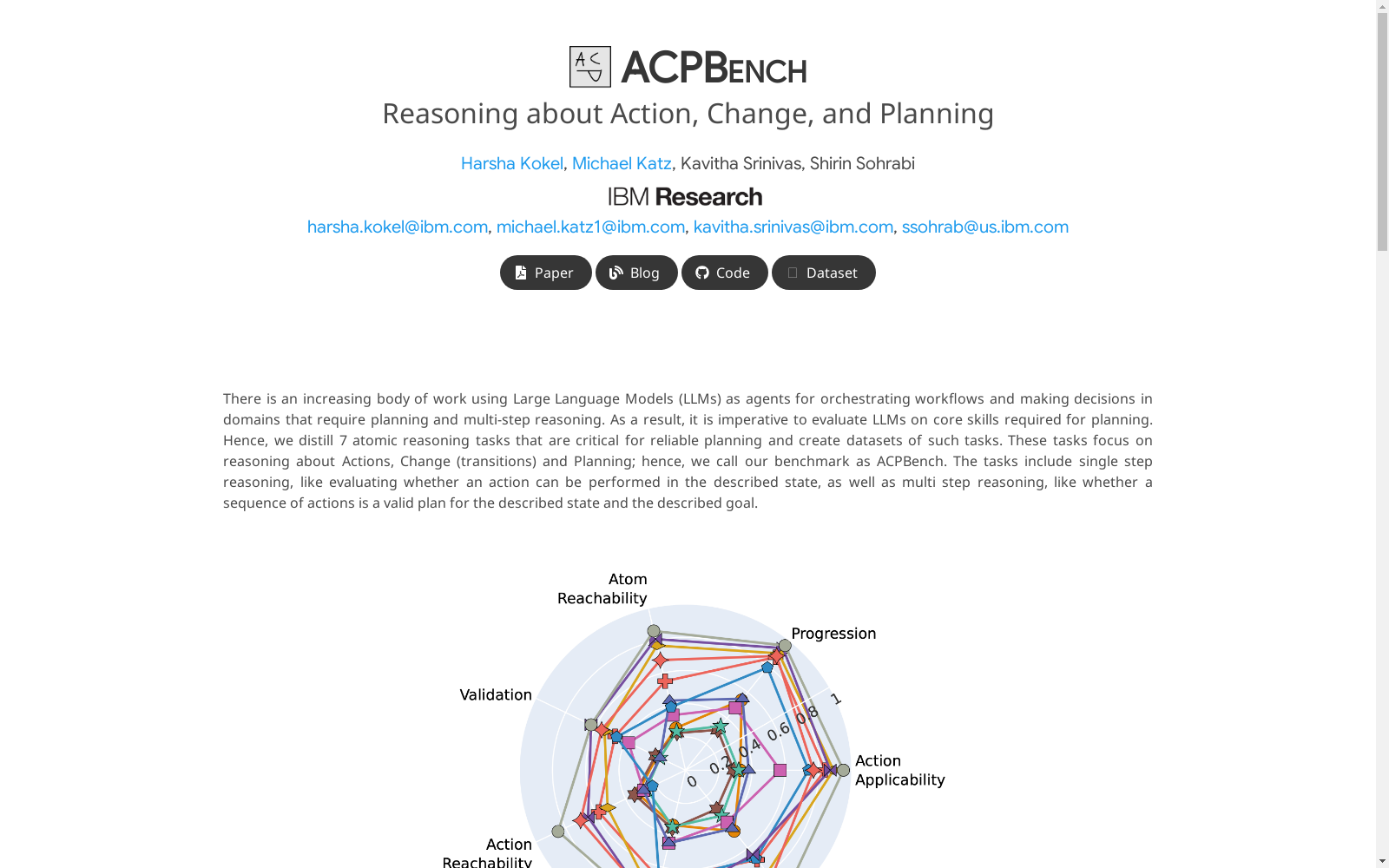
ACPBench Hard数据集的特点在于其任务设计的复杂性和开放性。数据集包含8个核心任务,涵盖动作适用性、状态演进、可达性、动作可达性、验证、合理性、地标以及新增的下一步动作预测任务。这些任务不仅要求模型具备多步推理能力,还需在开放生成式回答中准确输出符合规划逻辑的答案。数据集的难点在于其任务的计算复杂度较高,部分任务如动作可达性和地标识别属于PSPACE难问题,对模型的推理能力提出了严峻挑战。此外,数据集通过严格的验证算法确保评估的客观性,为模型性能提供了可靠的基准。
使用方法
使用ACPBench Hard数据集时,需针对每个任务设计相应的生成式回答机制。模型需根据提供的PDDL规划任务描述,直接生成符合任务要求的答案,例如输出所有适用动作、状态变化的正负效应或不可达的命题等。数据集的评估通过预定义的验证算法完成,验证过程可能涉及规划器的调用(如验证可达性任务时需生成规划)。为提高模型性能,可采用多示例提示(如2-shot prompting)引导模型遵循回答格式,同时需处理模型输出与预期格式的偏差。数据集的开放性和复杂性使其成为评估模型在规划任务中推理能力的理想基准。
背景与挑战
背景概述
ACPBench Hard是由IBM研究院的Harsha Kokel、Michael Katz、Kavitha Srinivas和Shirin Sohrabi于2025年提出的一个生成式问答数据集,旨在评估大型语言模型在动作、变化和规划(Action, Change, and Planning, ACP)领域的原子推理能力。该数据集基于早期的ACPBench,通过将复杂的规划任务分解为8项生成式原子推理任务(如动作适用性判断、状态推演、可达性分析等),填补了传统符号规划器与黑盒语言模型之间的能力评估空白。其创新性在于采用开放生成式问题设计,更贴近实际规划场景中无选项约束的决策需求。数据集覆盖13个PDDL规划领域,已成为测试语言模型逻辑推理与规划能力的基准工具,推动了可解释AI规划组件的研究。
当前挑战
ACPBench Hard面临双重挑战:在领域问题层面,其核心任务如动作可达性(PSPACE-hard)和地标识别需处理状态空间指数爆炸问题,而当前语言模型在开放生成式回答中的平均准确率不足40%;在构建层面,需解决生成问题与符号验证的鸿沟——例如设计多项式时间验证器来评估PSPACE-hard任务的生成答案,同时确保13个异构规划领域的问题平衡性。实验表明,即便是参数量达405B的Llama 3.1模型,在动作适用性判断任务中准确率仅14%,凸显了生成式规划推理的严峻技术壁垒。
常用场景
经典使用场景
ACPBench Hard数据集在人工智能规划领域被广泛应用于评估大型语言模型在开放式生成任务中的推理能力。该数据集通过将复杂的规划任务分解为原子推理任务,如动作适用性、状态演化和目标可达性等,为研究者提供了一个标准化的测试平台。其开放式问题设计模拟了真实规划场景中模型需要生成答案而非选择答案的挑战,使得评估更加贴近实际应用需求。
解决学术问题
ACPBench Hard解决了规划领域中对模型原子推理能力量化评估的难题。传统端到端规划评估无法精确定位模型失败原因,而该数据集通过分解规划过程,能够准确识别模型在动作适用性判断、状态转移预测等基础推理环节的薄弱点。尤其针对当前大型语言模型在生成式规划任务中表现不佳的问题,该数据集为改进模型推理能力提供了明确方向。
衍生相关工作
ACPBench Hard衍生出多个重要研究方向,包括基于该基准的模型微调方法、规划专用提示工程技术等。相关工作如TRAC和PlanBench在特定规划任务上进行了扩展,而AutoPlanBench则利用语言模型自动生成自然语言模板。这些工作共同推动了语言模型在规划领域的应用边界,形成了从原子推理到完整规划的系统性评估体系。
以上内容由遇见数据集搜集并总结生成


