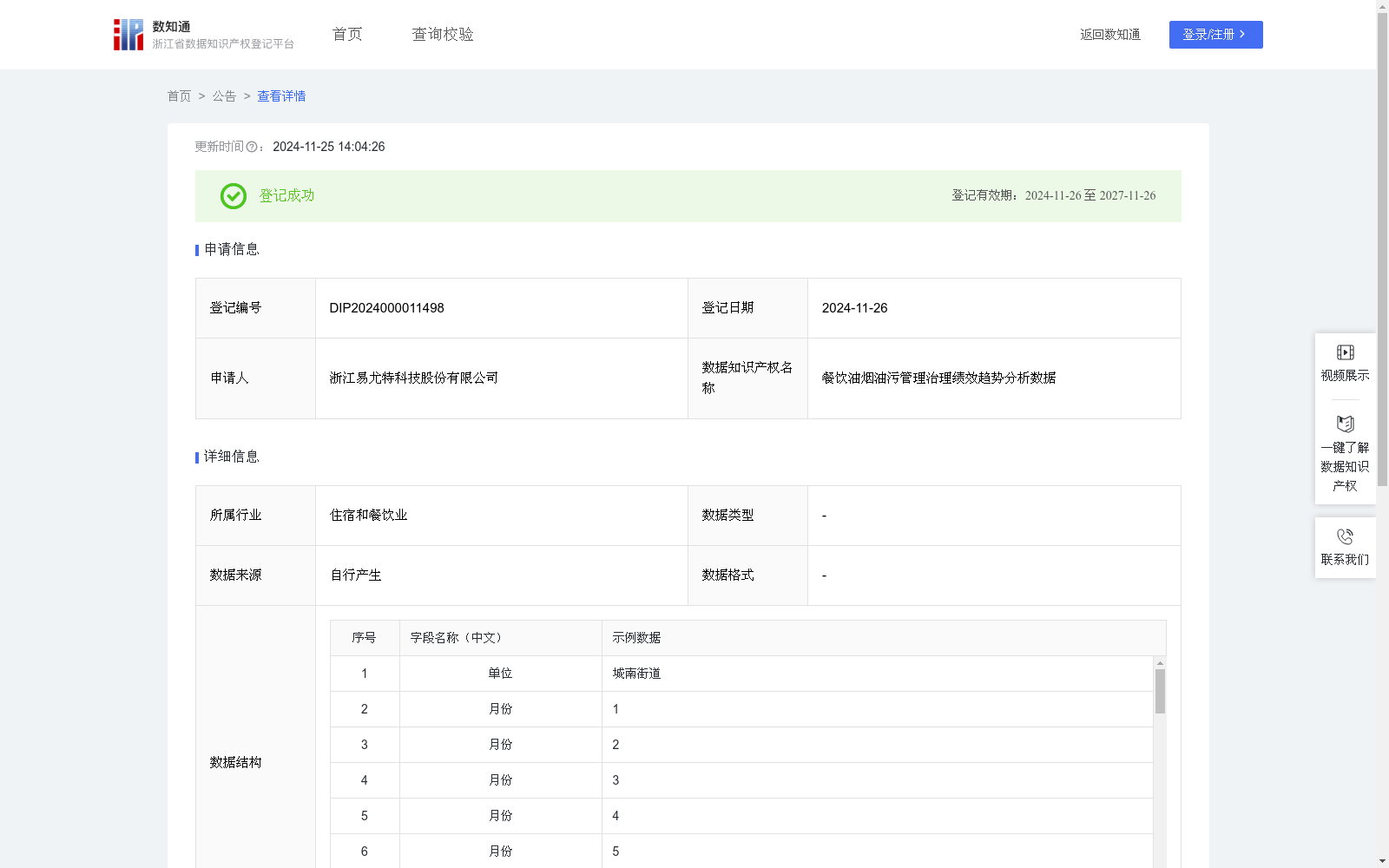
餐饮油烟油污管理治理绩效趋势分析数据
收藏浙江省数据知识产权登记平台2024-11-25 更新2024-11-26 收录
下载链接:
https://www.zjip.org.cn/home/announce/trends/88583
下载链接
链接失效反馈官方服务:
资源简介:
主要用于管理部门对餐饮行业的油烟油污管理情况进行阶段性趋势预测和基层餐饮油烟油污管理绩效分布情况的精准掌握,以单位(如街道)月度餐饮油烟油污管理综合评分为因变量,以时间(如月份)为自变量,以特定周期为数据采集范围(如年),采用线性回归分析方法,精准预测各单位下阶段(如下一年的第一个月)餐饮油烟油污管理走势。辅助有关部门能精准掌握各基层餐饮油烟油污管理趋势变化情况,有助于针对性指导管理绩效趋势不良的单位及时作出精准反应,辅助管理部门提升餐饮油烟油污管理智能化水平,为有关部门制定有效的宏观管理决策提供科学的量化依据。以单位餐饮油烟油污月度评估分值为因变量,以已有月份评估值的月份数值为自变量(如1-12月),采用回归分析方法预测下一阶段(如下一年1月即13月)餐饮油烟油污管理绩效趋势。
1.计算关系强度量(Sxx):Sxx=∑(xᵢ - x0)²,其中xᵢ是自变量月份数字值,x0是自变量月份数字值的平均值(月份数值求和不包含所要预测的月份数值)。
2.计算预测偏差度(Syx):Syx=∑(xᵢ - x0)*(yᵢ - y0),其中,yᵢ是单位的月份评估得分值即因变量实际观测值,y0是因变量观测值的平均值。如果为正,表示两个变量倾向于同时增加或同时减少;如果为负,表示一个变量增加时,另一个变量倾向于减少。
3.计算回归系数b:b = ∑(xᵢ - x0)*(yᵢ - y0)/∑(xᵢ - x0)²,其中,xᵢ和 yᵢ分别是自变量和因变量的各个观测值,x0和y0含义同上。
4.计算初始基准值(截距a):a =y0-b*x0,其中,x0、y0含义同上,b是回归系数。
5.通过回归方程预测第13个月单位的餐饮油烟油污管理评估分值:y =y0-b*x0+ bx,其中x=13,y0、x0、b含义同上。
This dataset is primarily developed to enable administrative departments to perform phased trend prediction of catering oil fume and grease management and accurately grasp the performance distribution of grass-roots catering oil fume and grease management. Taking the monthly comprehensive management score of catering oil fume and grease for each unit (e.g., sub-district) as the dependent variable, time (i.e., month) as the independent variable, and a specific cycle (e.g., one year) as the data collection scope, linear regression analysis is adopted to accurately predict the catering oil fume and grease management trend of each unit in the next stage (e.g., the first month of the following year). This tool assists relevant departments in accurately grasping the trend changes of grass-roots catering oil fume and grease management, enables units with poor management performance trends to make targeted and precise responses, helps management departments improve the intelligent level of catering oil fume and grease management, and provides scientific quantitative basis for relevant departments to formulate effective macro management decisions.
The specific implementation steps are as follows:
1. Calculate the relationship strength metric (Sxx): $S_{xx} = sum (x_i - ar{x})^2$, where $x_i$ is the numerical value of the independent variable (month number), and $ar{x}$ is the average value of the independent variable month numbers (the month number to be predicted is excluded from the summation of month values).
2. Calculate the prediction deviation index (S_yx): $S_{yx} = sum (x_i - ar{x})(y_i - ar{y})$, where $y_i$ is the actual observed value of the unit's monthly assessment score for catering oil fume and grease management (the dependent variable), and $ar{y}$ is the average value of the dependent variable observed values. A positive value indicates that the two variables tend to increase or decrease simultaneously; a negative value indicates that when one variable increases, the other tends to decrease.
3. Calculate the regression coefficient $b$: $b = frac{sum (x_i - ar{x})(y_i - ar{y})}{sum (x_i - ar{x})^2}$, where $x_i$ and $y_i$ are the respective observed values of the independent and dependent variables, and $ar{x}$, $ar{y}$ have the same meanings as above.
4. Calculate the initial baseline value (intercept $a$): $a = ar{y} - b cdot ar{x}$, where $ar{x}$, $ar{y}$ and $b$ have the same meanings as above.
5. Predict the assessment score of the unit's catering oil fume and grease management in the 13th month via the regression equation: $hat{y} = ar{y} - b cdot ar{x} + b cdot x$, where $x=13$, and $ar{y}$, $ar{x}$, $b$ have the same meanings as above.
提供机构:
浙江易尤特科技股份有限公司
创建时间:
2024-10-15
搜集汇总
数据集介绍
以上内容由遇见数据集搜集并总结生成


