RetarSet
收藏github2025-05-13 更新2025-05-14 收录
下载链接:
https://github.com/SEU-WSY/Image-Retargeting-A-Dataset
下载链接
链接失效反馈官方服务:
资源简介:
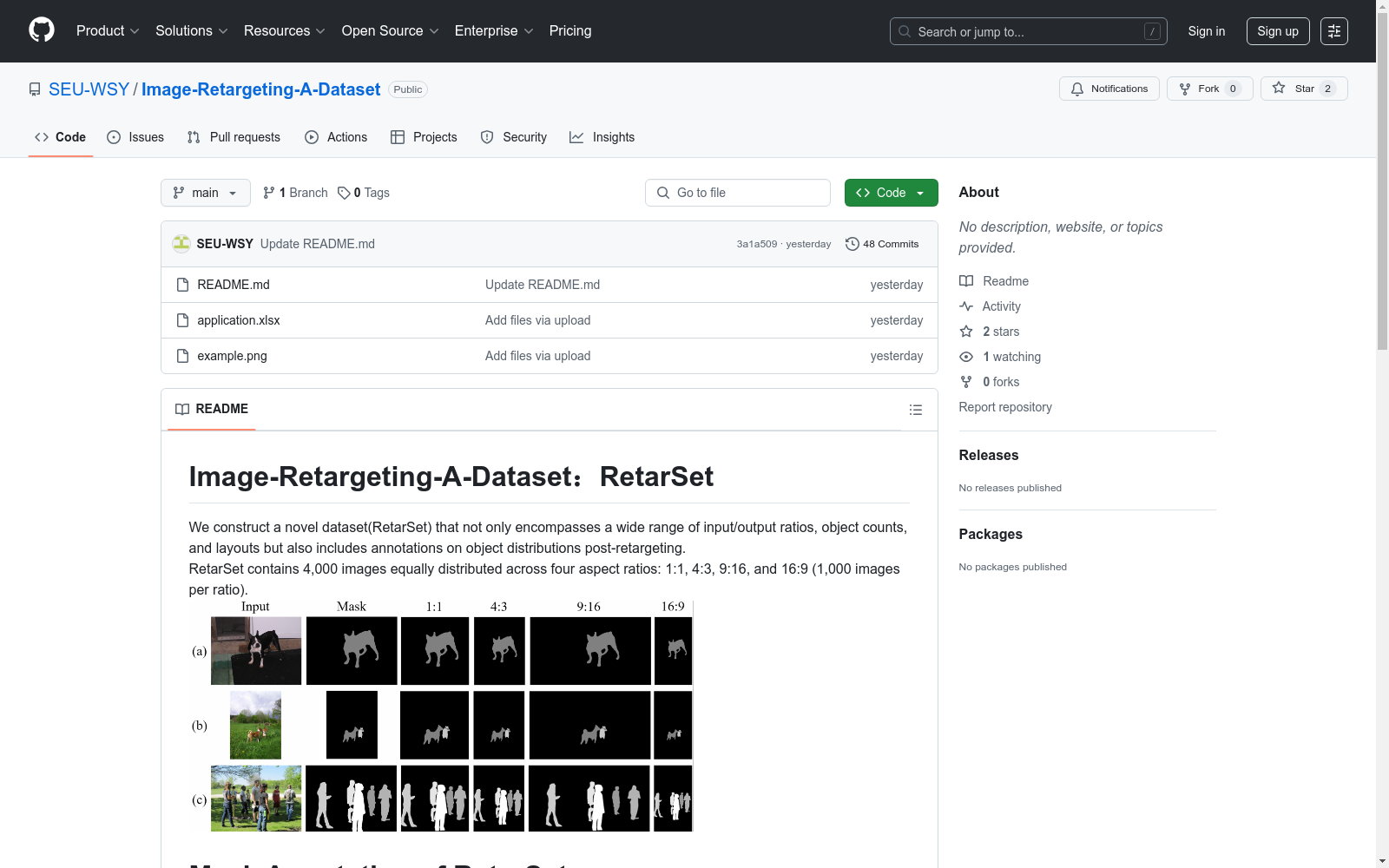
我们构建了一个新颖的数据集(RetarSet),不仅涵盖了广泛的输入/输出比例、对象数量和布局,还包括了重定向后对象分布的注释。RetarSet包含4,000张图像,均匀分布在四个宽高比中:1:1、4:3、9:16和16:9(每个比例1,000张图像)。
We have constructed a novel dataset, RetarSet, which not only encompasses a wide range of input/output ratios, object quantities, and layouts but also includes annotations for the distribution of objects after redirection. RetarSet contains 4,000 images, evenly distributed across four aspect ratios: 1:1, 4:3, 9:16, and 16:9 (1,000 images for each ratio).
创建时间:
2025-05-11
原始信息汇总
RetarSet数据集概述
数据集简介
- 名称:RetarSet
- 类型:图像重定向数据集
- 特点:
- 涵盖多种输入/输出比例、物体数量和布局
- 包含重定向后物体分布的标注
数据集规模
- 总图像数量:4,000张
- 比例分布:
- 1:1比例图像:1,000张
- 4:3比例图像:1,000张
- 9:16比例图像:1,000张
- 16:9比例图像:1,000张
标注信息
- 标注内容:重定向后前景实例的新空间布局
- 标注流程:
- 边界确定:提取前景实例并为每个显著掩模放置最小边界正方形
- 平移和修剪:通过Translate模块保持显著实例掩模的完整性
- 最终调整和扩展:对裁剪或部分遮挡的显著物体应用纠正措施
实例数量分布
| 实例数量 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|---|---|---|---|---|---|---|---|---|
| 图像数量 | 114 | 262 | 180 | 130 | 301 | 8 | 3 | 2 |
宽高比分布
| 宽高比 | 4:3 | 2:1 | 5:4 | 5:3 | 1:1 | 4:5 | 3:5 |
|---|---|---|---|---|---|---|---|
| 图像数量 | 754 | 28 | 32 | 44 | 17 | 47 | 78 |
数据获取
- 填写申请表
- 发送至cious449@gmail.com
引用要求
bibtex @misc{dataset2025, author = {SEU-WSY}, title = {Image Retargeting: A Dataset and Metrics}, year = {2025}, howpublished = {url{https://github.com/SEU-WSY/Image-Retargeting-A-Dataset}}, note = {Accessed: YYYY-MM-DD} }
搜集汇总
数据集介绍
构建方式
在图像重定向研究领域,RetarSet数据集的构建采用了系统化的标注流程。研究团队首先通过前景实例提取技术识别图像中的显著对象,并为每个对象生成最小外接正方形以定位其中心位置。随后运用自主研发的平移模块保持显著实例掩膜的完整性,最后通过精细化调整确保重定向过程中对象可见性不受影响。整个数据集包含4000张图像,均匀分布在1:1、4:3、9:16和16:9四种宽高比中,每类各1000张样本。
特点
该数据集在实例数量和宽高比分布上展现出显著优势。统计显示,RetarSet包含1至8个不等的实例数量配置,其中5实例场景占比最高达301例,为复杂场景分析提供了丰富素材。宽高比方面覆盖从4:3到3:5等七种常见比例,其中4:3规格图像多达754张,确保了数据分布的均衡性。每张图像均标注有重定向后的对象空间布局信息,这种细粒度的标注方式为评估重定向算法的几何保真度提供了可靠基准。
使用方法
研究人员可通过规范流程获取该数据集的使用权限。访问者需填写指定申请表格并发送至项目组邮箱,经审核通过后即可获取完整数据。数据集中包含的实例分布统计表与宽高比对照表,可辅助研究者进行数据采样与实验设计。引用该数据集时需按照提供的BibTeX格式标注来源,这既符合学术规范,也有助于追踪研究成果的影响力。数据集的多比例特性特别适合用于测试算法在不同显示场景下的适应性表现。
背景与挑战
背景概述
RetarSet数据集由东南大学WSY团队于2025年构建,专注于图像重定向领域的研究。该数据集包含4,000张图像,均匀分布在1:1、4:3、9:16和16:9四种宽高比中,每类1,000张图像。RetarSet不仅涵盖了多样化的输入输出比例、物体数量和布局,还提供了重定向后物体分布的空间标注,为图像重定向算法的评估和优化提供了重要基准。该数据集的发布填补了图像重定向领域缺乏标准化评估数据的空白,显著推动了计算机视觉和图像处理相关研究的发展。
当前挑战
RetarSet数据集面临的挑战主要体现在两个方面:在领域问题层面,图像重定向需要保持重要物体的视觉完整性和布局合理性,这对算法的语义理解和几何变换能力提出了极高要求;在构建过程中,标注重定向后物体的空间分布需要精确处理物体边界的平移、裁剪和调整,确保标注的准确性和一致性。此外,数据集的平衡性也是一大挑战,需要在不同宽高比和物体数量之间取得合理分布,以全面评估算法的鲁棒性。
常用场景
经典使用场景
在计算机视觉领域,图像重定向是一项关键技术,旨在调整图像尺寸以适应不同显示设备而不损失重要内容。RetarSet数据集凭借其丰富的图像样本和多样的宽高比分布,成为评估和比较图像重定向算法的理想基准。该数据集特别适用于研究如何在保持前景对象完整性的同时,实现图像的高效缩放和裁剪。
实际应用
在实际应用中,RetarSet数据集可广泛应用于响应式网页设计、移动设备适配和数字广告投放等领域。设计师和开发者可以利用该数据集训练和优化自动图像重定向系统,确保在各种屏幕尺寸上都能呈现最佳的视觉效果。数据集中的实例分布标注尤其有助于开发保护重要视觉元素的智能裁剪算法。
衍生相关工作
基于RetarSet数据集,研究者们已经开展了多项创新工作。其中包括开发新型的基于深度学习的图像重定向网络、提出客观的质量评估指标,以及探索多对象场景下的最优重定向策略。这些工作显著推动了图像自适应显示技术的发展,并为后续研究提供了重要参考。
以上内容由遇见数据集搜集并总结生成


