RoLegalGEC
收藏arXiv2026-04-23 更新2026-04-23 收录
下载链接:
https://huggingface.co/datasets/MirceaT/RoLegalGEC
下载链接
链接失效反馈官方服务:
资源简介:
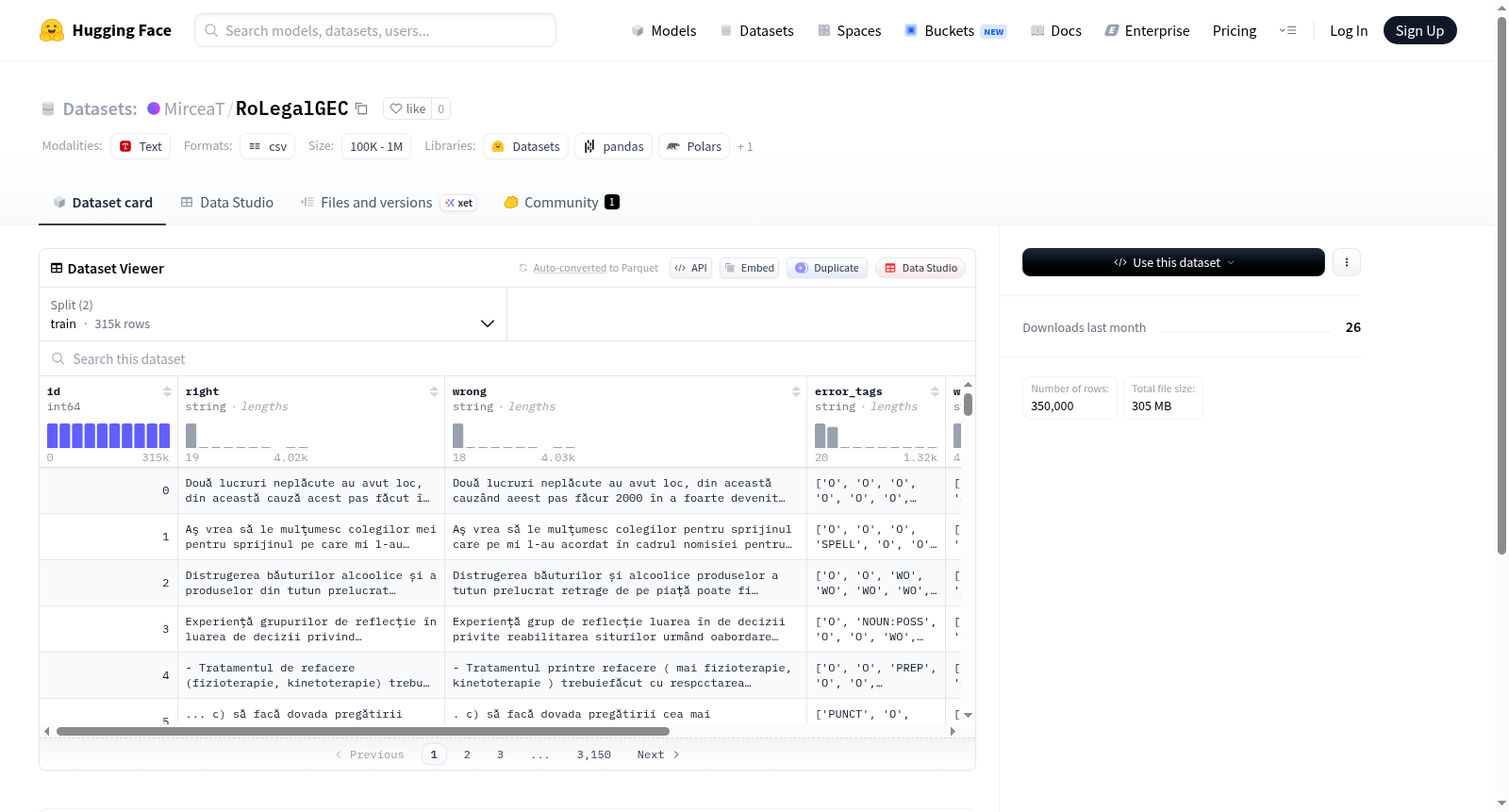
RoLegalGEC是由布加勒斯特理工大学等机构联合推出的首个罗马尼亚语法律领域语法错误检测与修正数据集,包含35万条法律文本段落及其错误标注。数据集通过合成生成方法构建,结合语法规则逆向应用、噪声注入及大语言模型提示技术,覆盖20类罗马尼亚语典型错误。该资源旨在支持法律文档自动校对系统的开发,填补低资源语言在专业领域语法纠错研究的空白。
RoLegalGEC is the first Romanian legal-domain grammatical error detection and correction dataset, jointly developed by institutions including the Polytechnic University of Bucharest and other relevant partners. It contains 350,000 legal text paragraphs with corresponding error annotations. The dataset is constructed via synthetic generation methods, which integrate reverse application of grammatical rules, noise injection, and large language model (LLM) prompting techniques, covering 20 typical types of Romanian grammatical errors. This resource aims to support the development of automatic legal document proofreading systems, and fills the research gap in professional-domain grammatical error correction for low-resource languages.
提供机构:
布加勒斯特理工大学; 巴黎第一大学·先贤祠-索邦; 布加勒斯特大学
创建时间:
2026-04-21
搜集汇总
数据集介绍
构建方式
在自然语言处理领域,针对低资源语言如罗马尼亚语构建专业领域数据集面临显著挑战。RoLegalGEC数据集通过系统化的合成错误生成方法,从MARCELL-RO和Europarl两个高质量法律语料库中提取35万条语法正确的法律文本。采用四种互补的生成策略:噪声注入技术模拟拼写和词序错误;基于混淆列表的替换方法处理功能词错误;零样本提示的LLM生成用于形容词形式和名词所有格等有限形态错误;两样本提示的LLM生成则借助常见罗马尼亚语错误示例库,精准生成动词时态、名词变格等复杂错误类型。这种分层生成机制确保了错误类型的全面覆盖与语言真实性。
特点
该数据集作为首个罗马尼亚语法律领域语法错误检测与修正并行语料库,具有鲜明的领域专属性与语言特性。其核心特征体现在精心设计的20类错误分类体系,该体系兼顾罗马尼亚语语法特性与国际标准,涵盖从拼写、标点到词形变化、主谓一致等全方位错误类型。数据集构建注重错误分布的自然性,通过统计分析和专家语料校准,使合成错误率接近真实语言使用场景。每条数据均包含原始正确文本、合成错误文本及详细的错误标注序列,形成完整的平行语料结构,为模型训练提供多维度监督信号。
使用方法
RoLegalGEC数据集支持语法错误检测与修正双任务评估框架。在错误检测任务中,可将数据集作为序列标注任务的训练资源,利用错误标注序列训练token分类模型。在错误修正任务中,平行语料可直接用于序列到序列模型的训练,将错误文本映射至正确文本。数据集特别设计了GEC-D任务范式,允许将检测任务输出的错误标签作为修正模型的附加输入,实现检测与修正的协同优化。研究实践中,可采用知识蒸馏的DistilBERT架构进行错误检测,并运用T5或BART等生成式Transformer架构进行错误修正,通过束搜索等解码策略优化输出质量。
背景与挑战
背景概述
RoLegalGEC数据集由布加勒斯特理工大学的研究人员Mircea Timpuriu和Dumitru-Clementin Cercel于2026年创建,旨在填补罗马尼亚语法律领域语法错误检测与纠正的资源空白。该数据集聚焦于自然语言处理中的语法错误检测与纠正任务,针对法律文档中文本准确性的关键需求,通过合成方法生成了35万条平行语料,涵盖了20类罗马尼亚语常见语法错误。其构建基于MARCELL-RO和Europarl等高质量法律语料库,不仅推动了低资源语言在法律领域的NLP研究,也为罗马尼亚语语法处理工具的开发提供了重要基础。
当前挑战
RoLegalGEC数据集面临的挑战主要体现在两个方面:在领域问题层面,法律文本的语法纠错需处理罗马尼亚语丰富的形态变化和句法结构,同时确保法律语义的精确性,这对模型的语境理解与错误分类提出了较高要求;在构建过程层面,合成数据生成需克服罗马尼亚语语法规则复杂、人工标注资源稀缺的困难,研究人员通过噪声注入、混淆列表和大型语言模型提示等多种方法模拟真实错误,但平衡错误多样性与语言自然度仍存在挑战。
常用场景
经典使用场景
在自然语言处理领域,特别是针对低资源语言的语法错误检测与纠正任务中,RoLegalGEC数据集为罗马尼亚语法律文本的语法错误分析提供了首个大规模并行语料库。该数据集通过合成生成方法,模拟了法律文档中常见的语法错误模式,为训练和评估语法错误检测与纠正模型奠定了坚实基础。其经典应用场景包括基于Transformer架构的序列标注模型和文本生成模型的训练,例如知识蒸馏的BERT模型用于错误检测,以及T5和BART模型用于错误纠正,从而在法律文本的自动校对和语言质量保障中发挥关键作用。
实际应用
在实际应用层面,RoLegalGEC数据集为法律文档的自动化校对和质量控制提供了有力工具。基于该数据集训练的模型能够识别和纠正法律文本中的语法错误,例如拼写错误、词序混乱、介词误用等,从而提升法律文档的准确性和可读性。这些技术可集成到法律文书处理系统、在线法律服务平台或政府公文审核流程中,辅助法律从业者高效完成文本修订工作,降低因语言错误导致的法律歧义风险,增强法律文本的权威性和专业性。
衍生相关工作
RoLegalGEC数据集的推出催生了一系列相关研究工作,特别是在低资源语言语法错误处理模型的优化与扩展方面。基于该数据集,研究者们探索了多种神经网络架构,如知识蒸馏的DistilBERT用于错误检测、序列标注模型结合罗马尼亚语预训练BERT进行错误分类,以及T5和BART等文本生成模型用于错误纠正。这些工作不仅提升了罗马尼亚语语法错误处理的性能,还为其他低资源语言在法律领域的语法错误研究提供了方法论参考,例如在乌克兰语、土耳其语等语言中类似数据集的构建与模型训练策略的借鉴。
以上内容由遇见数据集搜集并总结生成


