deepsweet/mdn
收藏Hugging Face2026-04-11 更新2026-04-12 收录
下载链接:
https://hf-mirror.com/datasets/deepsweet/mdn
下载链接
链接失效反馈官方服务:
资源简介:
---
license: other
license_link: https://github.com/mdn/content/blob/main/LICENSE.md
language:
- en
tags:
- rag
- embeddings
- lancedb
---
Pre‑ingested [LanceDB](https://lancedb.com/) of 50k+ rows from [MDN Web Docs](https://developer.mozilla.org/).
> [!NOTE]
> Main intention is to use it with the [companion RAG-MCP server](https://github.com/deepsweet/mdn) ready for semantic search with hybrid vector (1024-d) and full‑text (BM25) retrieval. Other use cases are welcome as long as it complies with the [license](#license).
## Content
The dataset covers the core MDN documentation sections, including:
- Web API
- JavaScript
- HTML
- CSS
- SVG
- HTTP
The [source content](https://github.com/mdn/content), originally in a fairly custom markdown format, is thoroughly processed into plain yet still structured text and then semantically split into meaningful standalone chunks without a hard token limit or overlap.There may still be some minor nuances and room for improvement in the chunked text. Please let me know if you spot any quirks.
The embedding model used for data ingestion is [BGE-M3](https://huggingface.co/BAAI/bge-m3) (1024 dimensions, 8192 tokens), specifically the quantized [Q4_K_M GGUF](https://huggingface.co/deepsweet/bge-m3-GGUF-Q4_K_M) version. Looking forward to trying [pplx-embed-context-v1](https://research.perplexity.ai/articles/pplx-embed-state-of-the-art-embedding-models-for-web-scale-retrieval) once it's [added](https://github.com/ggml-org/llama.cpp/issues/20055) to llama.cpp.
> [!WARNING]
> It is strongly recommended to use exactly the same model for correct similarity during query embedding.
## Usage
See [development repo](https://github.com/deepsweet/mdn) on GitHub for more details.
## Articles
- [Парсим MDN и пишем оффлайн RAG-MCP](https://habr.com/ru/articles/1019930/) (in Russian)
## License
This dataset is definitely a "derivative work" based upon the original MDN Web Docs content which [license](https://github.com/mdn/content/blob/main/LICENSE.md) is quite complex:
- "Prose" content is available under CC-BY-SA-2.5.
- Code examples and snippets added on or after August 20, 2010 are in the public domain (CC0).
- Code examples and snippets added before August 20, 2010 are available under MIT.
All code examples are never explicitly modified during the chunking step, and therefore are provided as is.
This dataset as a whole is provided under the same terms. No new copyright is asserted.
提供机构:
deepsweet
搜集汇总
数据集介绍
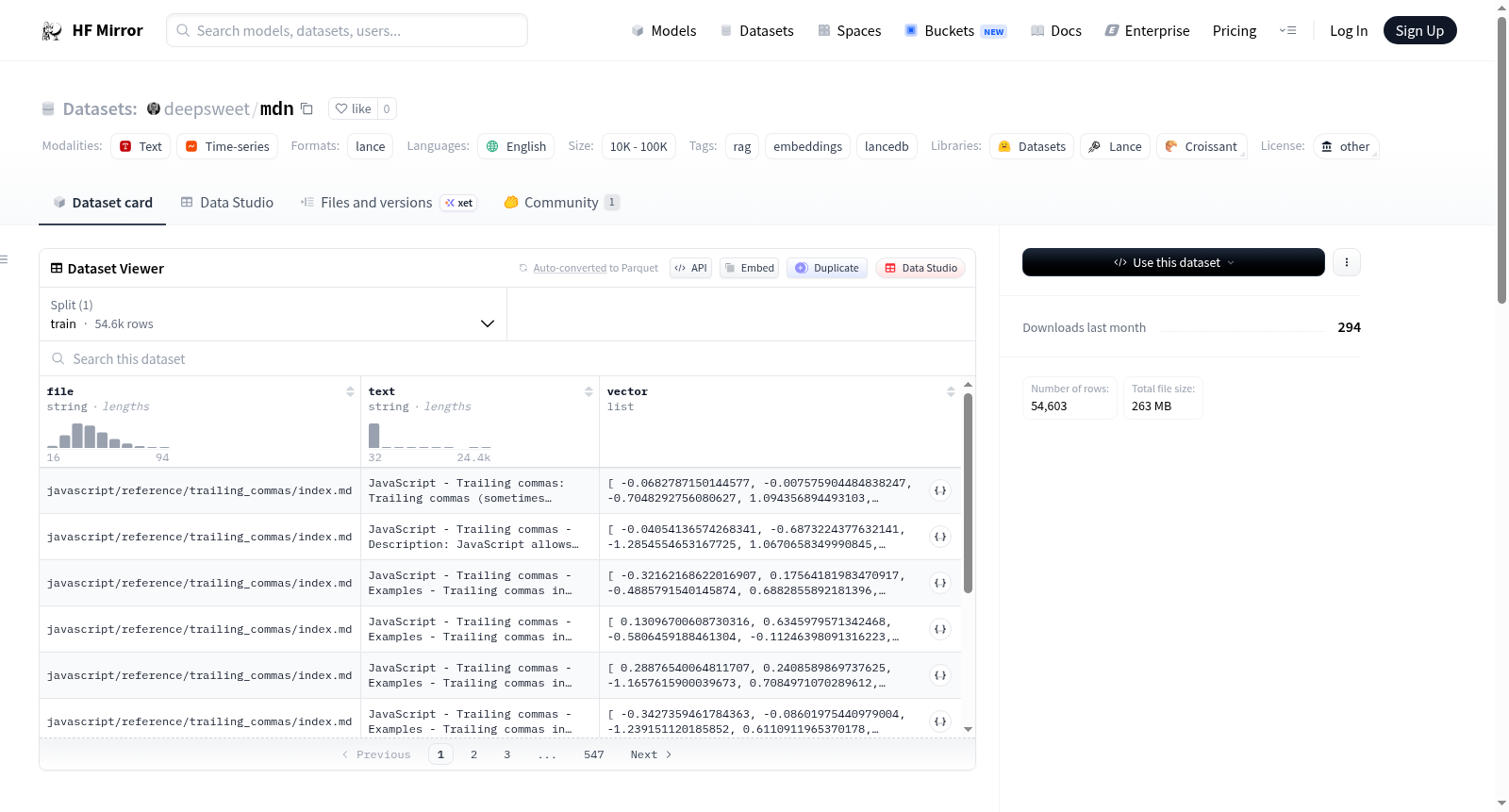
构建方式
在Web开发文档知识库构建领域,MDN数据集源自MDN Web Docs这一权威技术文档库。其构建过程首先对原始的自定义Markdown格式内容进行了深度清洗与转换,将其转化为结构清晰的纯文本。随后,采用语义分割技术将文档切分为具有独立意义的文本块,这一过程避免了僵化的令牌长度限制与重叠,旨在保持内容的连贯性与完整性。数据嵌入环节则选用了BGE-M3模型生成1024维的向量表示,为后续的语义检索奠定了坚实基础。
特点
该数据集的核心特点在于其覆盖了Web开发的核心技术领域,包括Web API、JavaScript、HTML、CSS、SVG与HTTP等关键模块,内容全面且权威。数据集经过精心处理,文本块既保持了原有的逻辑结构,又适合作为检索增强生成(RAG)等应用中的独立语义单元。特别值得注意的是,数据集已预先集成至LanceDB中,支持混合检索模式,即结合了高维向量语义搜索与BM25全文检索,这显著提升了信息检索的准确性与灵活性。
使用方法
该数据集主要设计用于与配套的RAG-MCP服务器协同工作,以实现高效的语义搜索。用户在进行查询时,需使用与数据嵌入阶段完全相同的BGE-M3模型来生成查询向量,以确保相似度计算的准确性。数据集以LanceDB格式提供,便于开发者直接进行向量与全文的混合检索操作。虽然其主要应用场景是检索增强生成,但数据集也开放用于其他符合其复杂许可证条款的用途,为Web开发知识的管理与应用提供了便利的工具基础。
背景与挑战
背景概述
MDN数据集由开发者社区于2024年构建,旨在为检索增强生成(RAG)系统提供高质量的Web开发文档语料。该数据集源自Mozilla开发者网络(MDN Web Docs),涵盖了Web API、JavaScript、HTML、CSS、SVG及HTTP等核心技术文档,经过深度处理转化为结构化文本块。其核心研究问题在于解决传统文档检索中语义理解不足的局限,通过嵌入模型BGE-M3生成高维向量,支持混合检索机制,显著提升了开发知识检索的准确性与效率,对自然语言处理与代码辅助工具领域产生了积极影响。
当前挑战
MDN数据集面临的挑战主要集中于领域问题与构建过程两方面。在领域层面,Web技术文档具有高度动态性与复杂性,如何精准捕捉API接口、代码示例与概念描述的语义关联,并适应快速演进的技术标准,构成了持续的检索难题。构建过程中,原始Markdown文档的非标准化格式需转化为统一文本结构,同时保持代码片段的完整性;语义分块需平衡信息独立性与上下文连贯性,避免信息碎片化;嵌入模型的选择与量化版本的应用亦对检索一致性提出了严格要求,任何偏差均可能影响相似性计算的有效性。
常用场景
经典使用场景
在Web开发与文档检索领域,MDN数据集以其结构化文本和语义分块特性,成为检索增强生成(RAG)系统的经典应用场景。该数据集通过BGE-M3模型嵌入为1024维向量,支持混合向量与全文检索,常用于构建智能文档助手,实现高效、精准的代码示例与API文档查询。开发者可借助此数据集快速定位技术细节,提升开发效率,尤其适用于离线环境下的语义搜索任务。
解决学术问题
该数据集有效解决了自然语言处理中大规模技术文档的语义检索与知识组织难题。通过将MDN Web Docs的复杂Markdown内容转化为规范化文本块,并辅以高质量嵌入表示,它为学术界提供了研究文档分割、跨模态检索以及长上下文理解的基准资源。其意义在于推动了开放领域问答系统在专业垂直场景下的性能优化,为知识密集型应用的算法评估奠定了数据基础。
衍生相关工作
围绕MDN数据集,已衍生出多项经典研究工作,例如基于LanceDB的混合检索框架优化、针对技术文档的特定领域嵌入模型微调等。相关项目如配套的RAG-MCP服务器,实现了语义搜索与全文检索的深度融合;同时,社区还探索了将数据集扩展至多语言版本或结合新型嵌入模型(如pplx-embed-context-v1),进一步提升了检索精度与跨文档关联能力,推动了开源知识库系统的持续演进。
以上内容由遇见数据集搜集并总结生成


