Tomerd88/obesity-lifestyle-analysis
收藏Hugging Face2026-04-11 更新2026-04-12 收录
下载链接:
https://hf-mirror.com/datasets/Tomerd88/obesity-lifestyle-analysis
下载链接
链接失效反馈官方服务:
资源简介:
---
license: mit
task_categories:
- tabular-classification
language:
- en
tags:
- health
- medical
- biology
pretty_name: Obesity Levels & Lifestyle Analysis
size_categories:
- 1K<n<10K
---
<video src="https://cdn-uploads.huggingface.co/production/uploads/69d98e416f24734dd0943c55/eKTE3OIHtHQfCqqNsmtm8.mp4" controls="controls" style="max-width: 720px;"></video>
# Obesity Levels & Lifestyle Dynamics: A Predictive Research Study
**Student:** Tomer Dariel
**Academic Institution:** Reichman University (IDC Herzliya)
**Course:** Introduction to Data Science
---
## 1. Project Overview
This research explores the critical relationship between lifestyle habits, physical attributes, and genetic predispositions in determining obesity levels. By analyzing multimodal data, the study aims to identify which factors—biological or behavioral—should be prioritized in public health assessments. The research moves beyond the common assumption that weight is purely a result of exercise, seeking to uncover the hidden "anchors" of body mass.
---
## 2. Research Questions & Dataset Selection
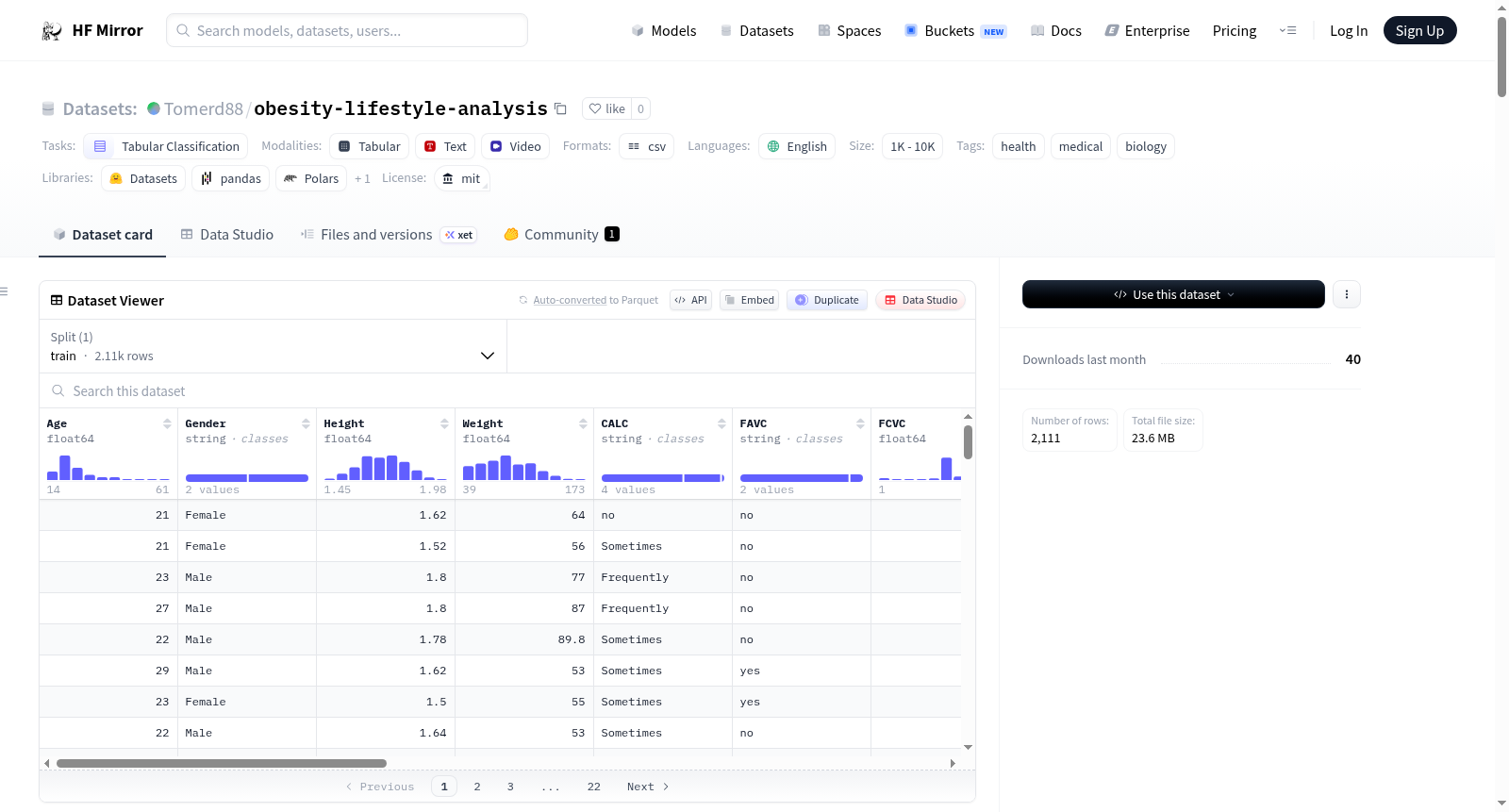
**Source:** The dataset is sourced from Kaggle (Estimation of Obesity Levels based on eating habits and physical condition), containing pre-processed multimodal data for health classification.
**Size:** The dataset consists of 2,111 rows and 17 features, providing a substantial foundation for non-basic statistical analysis.
**Features:**
* **Biological and Genetic (3 features):** Age, Height, and Family History of Overweight.
* **Behavioral Habits (7 features):** Physical Activity Frequency (FAF), Water Consumption (CH2O), Time using Technology (TUE), and Vegetable Consumption (FCVC).
**Target Variable:** `NObeyesdad`, which classifies each sample into 7 categories: Insufficient Weight, Normal Weight, Overweight I/II, and Obesity I/II/III.
**Primary Research Question:** Which factor serves as the strongest predictor of clinical obesity: physical stature (Height), behavioral habits (Activity), or genetic background (Family History)?
---
## 3. Data Cleaning & Preprocessing
**Integrity Check:** The dataset was found to be complete with no missing values (0 nulls). Duplicate rows were identified and removed to ensure statistical purity and prevent over-representation of specific profiles.
**Label Mapping:** I manually mapped the categorical target variable (`NObeyesdad`) into an ordinal scale ranging from 0 to 6. This allowed the analysis to treat obesity as a progression rather than independent labels.
**Feature Encoding:** Categorical variables such as `Family History` and `Gender` were converted into binary numerical values (0 and 1). This critical step enabled these features to be processed in the Advanced Correlation Matrix, measuring the "signal" of genetics against numeric behavioral habits.
---
## 4. Key Research Decision: Outlier Handling
**Identification:** Outliers were detected using Box Plots analyzing the distribution of Weight across Obesity Levels.

**Handling and Justification:** While standard practice often suggests removing outliers, I made the strategic decision to **keep all extreme values**.
**Reasoning:** In obesity research, outliers represent the most clinically significant cases—individuals at the extreme ends of the weight spectrum. Removing them would create a "sterile" dataset incapable of detecting the very conditions (Obesity Type III) that this research aims to predict. These outliers are not errors; they are the core of the study.
---
## 5. Height vs. Weight: The Physical Anchor
**Visualization:**

**Analysis:** The scatter plot revealed a positive correlation of **0.46**.
**Insight:** While height provides the physical frame for weight, the 0.46 correlation indicates that it only explains less than half of the variance. This finding led to the next stage of the study: investigating what fills the gap between stature and actual body mass.
---
## 6. Physical Activity vs. Weight: Challenging the Intuition
**Visualization:**

**Analysis:** I investigated the frequency of physical activity (FAF) as a predictor.
**Finding:** Surprisingly, the correlation was significantly lower than height or genetics.
**Insight:** This challenges the common intuition that exercise is the primary driver of weight. In this specific population, activity frequency is a supportive factor but lacks the predictive power of biological anchors, suggesting that lifestyle choices are often secondary to a genetic baseline.
---
## 7. Cross-Analysis: Family History & Gender
**Visualization:**

**Methodology:** I utilized a Pivot Table to calculate the mean weight across gender and genetic lines.
**Key Finding:** Individuals with a family history of overweight have a drastically higher weight floor.
**Insight:** The data reveals that males with a family history reached the highest average weights in the sample. This identifies a specific high-risk demographic where genetic predisposition and gender-specific biology intersect.
---
## 8. Advanced Correlation Map
**Visualization:**

**Analysis:** By including the newly encoded Family History variable in the correlation matrix, the true hierarchy of predictors emerged.
**Finding:** A remarkable **0.50 correlation** was found between Family History and the Obesity Level.
**Insight:** This was the strongest link in the entire study. It proves that a patient's genetic and environmental background is a more reliable primary differentiator for obesity than their physical height or their self-reported exercise habits.
---
## 9. Final Conclusions
**Genetics as a Proxy for Risk:** The study identifies Family History (0.50) as the most powerful predictor. Predictive models must prioritize genetic background to accurately identify at-risk individuals before they reach extreme obesity levels.
**Physical-Habit Dissonance:** The gap between the 0.46 (Height) and 0.50 (Genetics) correlations indicates that while we are anchored to our stature, our genetic environment sets our biological limit.
**Final Summary:** The research concludes that obesity is a multi-modal challenge. The findings suggest that public health interventions should be tailored to individuals with specific genetic risk factors, as behavioral habits alone show a lower direct correlation with clinical weight outcomes in this dataset.
---
提供机构:
Tomerd88
搜集汇总
数据集介绍
构建方式
在公共卫生与生物医学交叉领域,肥胖症研究日益关注多模态数据的整合分析。本数据集源自Kaggle平台,经过系统的数据清洗与预处理流程构建而成。原始数据包含2,111条样本与17个特征,涵盖生物遗传属性(如年龄、身高、家族史)与行为习惯(如体力活动频率、蔬菜摄入量)等多维度信息。数据完整性极高,无缺失值,并通过去重处理确保了样本的独立性。目标变量NObeyesdad被映射为有序数值,以反映肥胖程度的渐进性,而分类特征则经过编码转换为数值形式,为后续的相关性分析与模型训练奠定基础。
特点
该数据集的核心特点在于其多维度的健康信息整合与临床导向的数据结构。特征设计同时涵盖生物遗传因素与行为生活方式,使得研究者能够探索肥胖症的多重驱动机制。目标变量细致划分了七个肥胖等级,从体重不足到肥胖三级,为分类任务提供了精细的临床标签。数据集中特意保留了极端值样本,这些样本代表了肥胖谱系中的关键病例,增强了数据集在识别高危人群方面的实用价值。此外,特征之间的相关性结构,如家族史与肥胖程度高达0.50的相关性,揭示了遗传背景在肥胖预测中的主导作用,为公共卫生策略提供了实证依据。
使用方法
该数据集适用于表格分类任务,尤其适合用于健康风险评估与肥胖预测模型的研究。使用者可首先加载数据,利用提供的特征进行探索性分析,如通过散点图与相关矩阵揭示变量间的关系。在建模前,建议将分类特征进行适当编码,并利用有序的目标变量训练分类器,以预测个体的肥胖等级。数据集的样本规模适中,适合用于机器学习算法的训练与验证,同时其清晰的变量定义便于特征工程与解释性分析。研究者还可基于该数据集探讨遗传与行为因素的交互作用,为个性化健康干预提供数据支持。
背景与挑战
背景概述
肥胖与生活方式分析数据集由Reichman大学(IDC Herzliya)的数据科学课程学生Tomer Dariel于近期创建,旨在探究生活方式习惯、生理特征与遗传倾向在决定肥胖水平中的复杂关联。该研究聚焦于超越单纯运动影响的传统假设,通过整合生物遗传与行为习惯等多模态数据,深入解析体重变化的潜在“锚点”。其核心科学问题在于识别何种因素——生物性抑或行为性——在公共卫生评估中应被优先考量,从而为精准健康干预提供实证依据。
当前挑战
该数据集致力于解决肥胖风险预测这一领域挑战,其核心在于从多维度特征中辨识影响肥胖等级的关键驱动因子,尤其是遗传背景、生理指标与行为习惯之间的交互作用。在构建过程中,研究面临数据代表性挑战,需审慎处理极端值以保留临床显著案例;同时,特征编码与相关性分析需克服类别变量与连续变量整合的复杂性,确保遗传信号得以准确量化。此外,如何平衡直观行为指标与潜在生物锚点的解释力,亦是模型构建与结论泛化的重要难点。
常用场景
经典使用场景
在公共卫生与流行病学领域,肥胖问题已成为全球性的健康挑战,而该数据集为探索肥胖与生活方式之间的复杂关联提供了关键数据支撑。其经典使用场景在于构建预测模型,通过整合个体的生物特征、遗传背景及行为习惯等多模态特征,对肥胖等级进行精准分类。研究人员常利用机器学习算法,如决策树或逻辑回归,分析数据集中身高、家族史、体力活动频率等变量,以识别导致肥胖的主导因素,从而为临床风险评估和个性化干预策略提供科学依据。
解决学术问题
该数据集有效解决了肥胖研究中长期存在的学术争议,即遗传因素与生活方式何者对肥胖发展更具决定性影响。通过量化分析,它揭示了家族史与肥胖等级之间存在0.50的强相关性,超越了身高(0.46)和体力活动等传统预测因子的解释力。这一发现挑战了单纯依赖行为干预的公共卫生范式,推动了学术界从多模态视角重新审视肥胖的病因学机制,为构建更精准的风险预测模型奠定了实证基础,促进了遗传流行病学与行为科学的交叉融合。
衍生相关工作
基于该数据集的多模态特征,衍生了一系列经典研究工作。例如,在机器学习领域,研究者开发了集成学习模型,以提升肥胖等级分类的准确性;在生物统计学中,相关分析推动了因果推断方法的改进,用于辨析遗传与环境的交互效应。此外,该数据集的公开促进了跨学科合作,催生了结合基因组学与行为数据的纵向研究,进一步探索肥胖的动态发展轨迹。这些工作不仅丰富了健康信息学的理论体系,也为全球肥胖防控政策的制定提供了持续的数据驱动见解。
以上内容由遇见数据集搜集并总结生成


