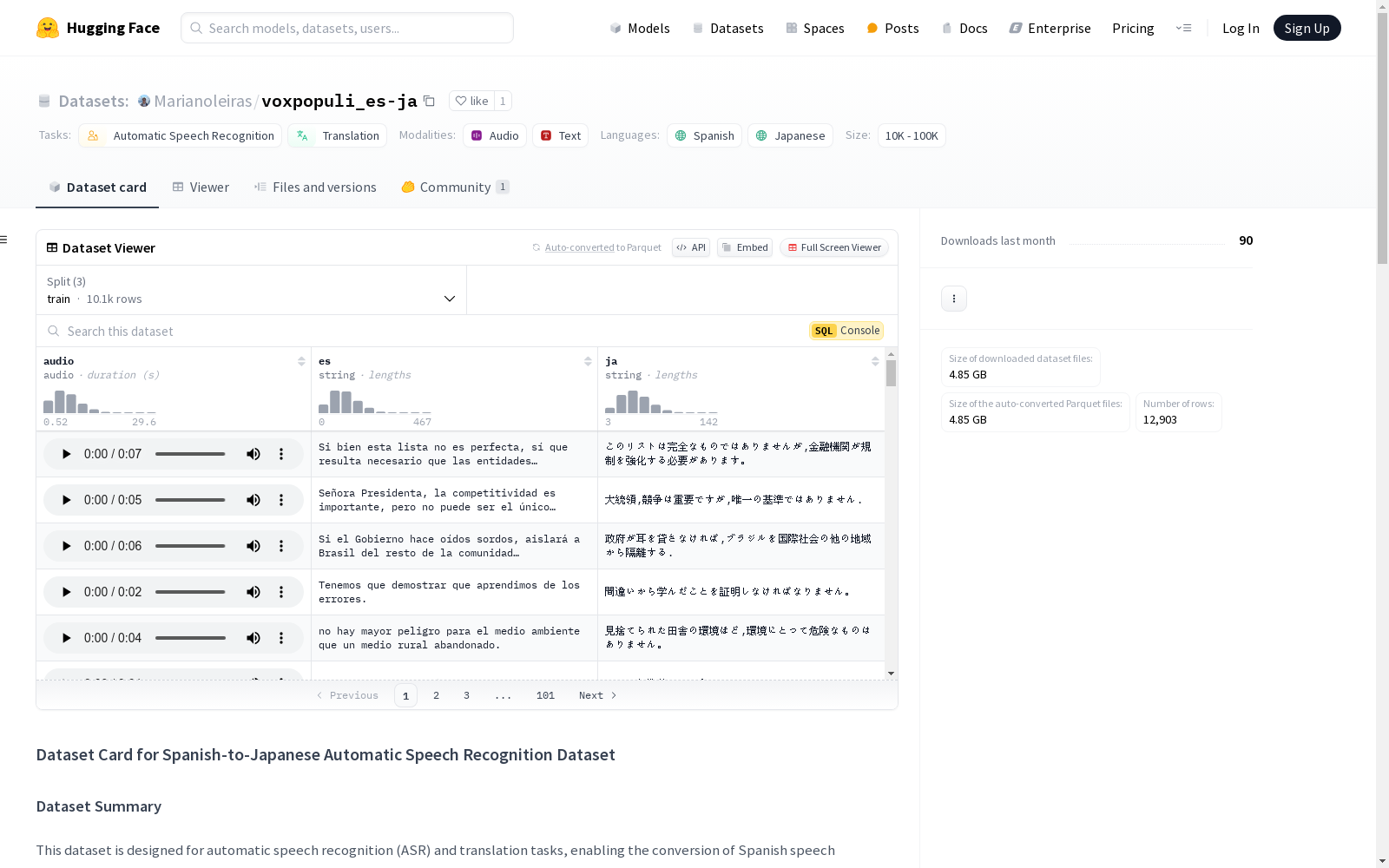
voxpopuli_es-ja
收藏数据集卡片:西班牙语到日语的自动语音识别数据集
数据集概述
该数据集旨在用于自动语音识别(ASR)和翻译任务,能够将西班牙语语音转换为日语文本。它包含高质量的音频录音,采样率为16 kHz,并配有西班牙语转录(es)及其日语翻译(ja)。
数据集结构
特征
数据集包含以下特征:
audio:音频录音,采样率为16 kHz。es:音频的西班牙语转录。ja:西班牙语转录的日语翻译。
数据分割
| 分割 | 样本数量 |
|---|---|
| 训练 | 10,081 |
| 验证 | 1,456 |
| 测试 | 1,366 |
数据集大小
- 下载大小: 4.85 GB
- 数据集大小: 5.66 GB
数据集处理
数据集的构建过程如下:
- 基础数据集:使用 facebook/voxpopuli 数据集作为基础数据集,提供西班牙语音频及其对应的转录。
- 翻译为英语:使用 Helsinki-NLP/opus-mt-es-en 机器翻译模型将西班牙语转录翻译为英语。
- 翻译为日语:使用 Helsinki-NLP/opus-tatoeba-en-ja 机器翻译模型将英语翻译进一步翻译为日语。
- 处理日语文本:日语翻译中包含不必要的空白,这些空白在日语书写中不常见。这些空白被删除以确保格式和一致性。
- 质量过滤:使用 Unbabel/wmt23-cometkiwi-da-xl MT 质量评估模型对日语翻译进行质量评估。低质量的翻译被过滤掉,以确保最终数据集在音频、转录和翻译之间保持一定的质量对齐。
引用
@article{wang2021voxpopuli, title={VoxPopuli: A Large-Scale Multilingual Speech Corpus for Representation Learning, Semi-Supervised Learning and Interpretation}, author={Chung-Cheng Chiu and Paden Tomasello and ...}, year={2021}, publisher={Meta AI}, url={https://huggingface.co/datasets/facebook/voxpopuli} }
@inproceedings{tiedemann-thottingal-2020-opus, title={OPUS-MT -- Building Open Translation Services for the World}, author={J{"o}rg Tiedemann and Santhosh Thottingal}, booktitle={Proceedings of the 22nd Annual Conference of the European Association for Machine Translation (EAMT)}, year={2020}, url={https://huggingface.co/Helsinki-NLP} }
@inproceedings{rei-etal-2023-cometkiwi, title={COMETKiwi: Advanced Quality Estimation Model for Machine Translation}, author={Rei, Ricardo and others}, year={2023}, url={https://huggingface.co/Unbabel/wmt23-cometkiwi-da-xl} }
数据集卡片联系人
Mariano González (marianoleiras@hotmail.com)