WebBench
收藏Hugging Face2025-05-27 更新2025-05-28 收录
下载链接:
https://huggingface.co/datasets/Halluminate/WebBench
下载链接
链接失效反馈官方服务:
资源简介:
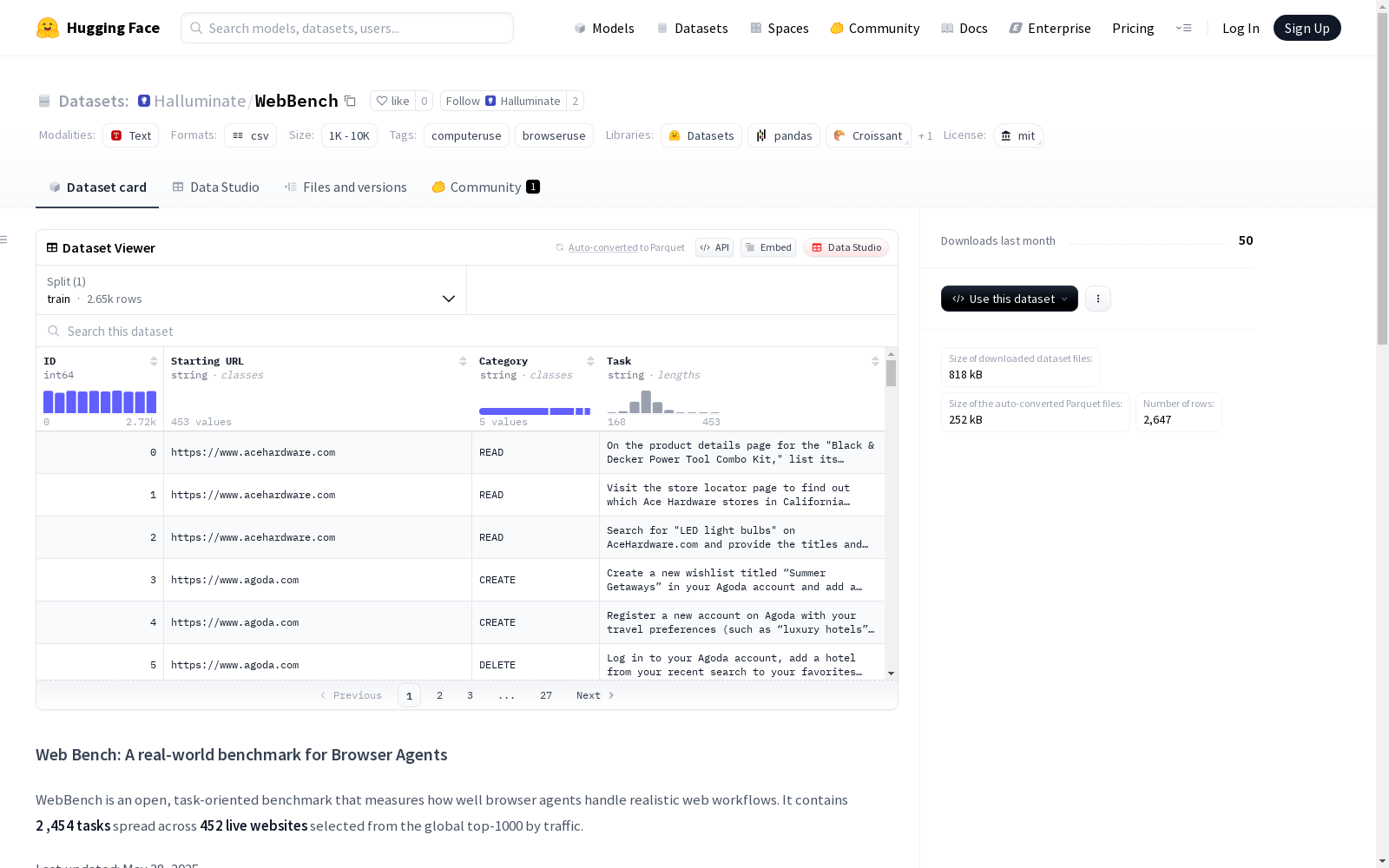
WebBench是一个针对浏览器代理的实世界任务基准测试,包含约2454个经过精心策划的任务,这些任务分布在450多个真实网站上,覆盖了现代网络的真正多样性。数据集的任务类型包括阅读、创建、更新、删除和文件操作等,旨在为研究人员和开发者提供一种准确测量浏览器代理性能、快速原型化和验证浏览器代理在不同网络场景下的方法。
创建时间:
2025-05-19
原始信息汇总
WebBench数据集概述
基本信息
- 许可证: MIT
- 标签: computeruse, browseruse
- 数据规模: 1K<n<10K
数据集简介
WebBench是首个针对基于动作的浏览器网页代理的实时基准测试数据集,旨在解决现有浏览器代理评估方法的局限性。
核心特点
- 真实世界复杂性
- 提供接近真实的基于网页的读取和动作导向任务。
- 多样化覆盖
- 涵盖450+个真实网站,反映现代网页的真实变异性。
- 开源特性
- 公开发布2,454个精心策划的任务。
任务类别分布
| 类别 | 描述 | 示例 | 占比 |
|---|---|---|---|
| READ | 需要搜索和提取信息的任务 | 导航至新闻版块并总结最新科学政策更新的标题和要点 | 64.4% |
| CREATE | 需要在网站上创建数据的任务 | 登录账户并在"愿望清单"版块创建名为"2024夏季"的新看板 | 20.9% |
| UPDATE | 需要更新网站数据的任务 | 调整Springer账户中的期刊通知偏好 | 7.1% |
| DELETE | 需要从网站删除数据的任务 | 创建测试问题后删除 | 6.1% |
| FILE_MANIPULATION | 需要从互联网下载文件的任务 | 下载流行甜点食谱的可打印文件 | 1.5% |
网站类别
- 覆盖17个主要类别
- 从全球流量前1000的网站中采样
- 经过清洗处理(移除重复域名、非英文网站和付费墙网站)
应用方向
- 精确测量代理在真实环境中的性能
- 快速原型设计和验证浏览器代理
- 推动浏览器自动化技术的边界
相关资源
- GitHub仓库: https://github.com/Halluminate/WebBench
- 技术报告: https://halluminate.ai/blog/benchmark
搜集汇总
数据集介绍
构建方式
WebBench数据集通过精心筛选全球流量排名前1000的452个活跃网站,构建了一个包含2454项任务的真实场景测试基准。其任务设计采用分层抽样策略,覆盖信息检索、数据创建、内容更新、数据删除及文件操作五大典型网络行为类别,各任务均基于真实用户操作场景建模,确保数据生态效度。数据采集过程采用自动化脚本与人工验证相结合的方式,最终形成结构化任务描述与操作流程标注体系。
使用方法
研究人员可通过官方GitHub仓库获取完整的任务描述集与评估框架。使用时应遵循标准测试协议,将智能体部署在纯净的浏览器环境中执行任务,通过预设的成功率、完成时间等指标进行量化评估。数据集支持模块化调用,可根据研究需求选择特定任务类别或网站子集。对于新型智能体开发,建议先在READ类基础任务上验证核心能力,再逐步扩展到包含身份验证、动态元素处理的复杂任务场景。
背景与挑战
背景概述
WebBench数据集由Halluminate团队于2025年推出,旨在为浏览器智能体在真实网络环境中的任务执行能力提供标准化评估框架。该数据集从全球流量前1000的网站中精选452个活跃站点,构建了涵盖信息检索、数据创建、内容更新等五大类别的2454项任务。作为首个面向开放网络环境的任务型基准测试工具,WebBench通过模拟真实用户操作场景,填补了传统封闭测试环境与动态互联网应用之间的评估鸿沟,为智能体交互能力研究提供了重要基础设施。
当前挑战
构建WebBench面临双重挑战:在领域问题层面,动态网页的DOM结构变异、非模态弹窗干扰以及多步骤身份验证流程,对智能体的鲁棒性提出极高要求;在数据集构建层面,需平衡任务多样性(覆盖64.4%读取类与20.9%创建类操作)与可重复性,确保452个网站在不同测试时段保持接口稳定性。实时网站的布局更新频率与API变动进一步增加了基准测试结果的可比性维护难度。
常用场景
经典使用场景
在浏览器智能体研究领域,WebBench数据集以其真实场景下的任务导向型基准测试著称。该数据集覆盖全球流量前1000名的452个活跃网站,包含2454个多样化任务,为评估智能体在信息检索、数据创建、更新删除等复杂操作中的表现提供了标准化平台。研究人员通过模拟用户与网页的交互流程,能够系统性地检验智能体在动态DOM结构、弹窗处理及身份验证等实际挑战中的鲁棒性。
解决学术问题
WebBench有效解决了浏览器智能体研究中缺乏标准化评估体系的痛点。通过构建涵盖64.4%信息读取、20.9%数据创建等比例的任务体系,该数据集为量化智能体在多层次网页操作中的性能提供了科学依据。其特别针对DOM结构突变、异步加载等传统难点设计任务,推动了智能体跨网站泛化能力、多步骤任务规划等核心问题的研究进展,填补了模拟环境与真实网络场景间的评估鸿沟。
实际应用
该数据集已广泛应用于商业智能助手开发与网页自动化测试领域。企业利用其丰富的任务场景优化智能客服系统的网页导航精度,如电商平台通过CREATE类任务训练商品收藏功能自动化。网络安全团队则借助FILE_MANIPULATION任务验证下载防护机制的可靠性,教育科技公司采用READ任务评估在线学习平台的辅助信息检索性能,显著降低了真实用户测试成本。
数据集最近研究
最新研究方向
随着人工智能技术在浏览器代理领域的深入应用,WebBench数据集作为衡量代理处理真实网络工作流程能力的基准,近期研究聚焦于多模态任务执行与动态环境适应性。研究者们正探索如何提升代理在复杂网页结构中的信息检索精度,特别是在跨语言、跨文化情境下的表现。数据集涵盖的实时网站任务为验证代理在CRUD操作和文件管理方面的鲁棒性提供了丰富场景,相关成果已应用于智能助手和自动化测试工具的优化。技术报告显示,该数据集正推动浏览器代理在电商、学术出版等垂直领域的实用化进程,其开源特性亦促进了学术界与工业界的协作创新。
以上内容由遇见数据集搜集并总结生成


