million-text-embeddings
收藏Hugging Face2024-11-28 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/Sreenath/million-text-embeddings
下载链接
链接失效反馈官方服务:
资源简介:
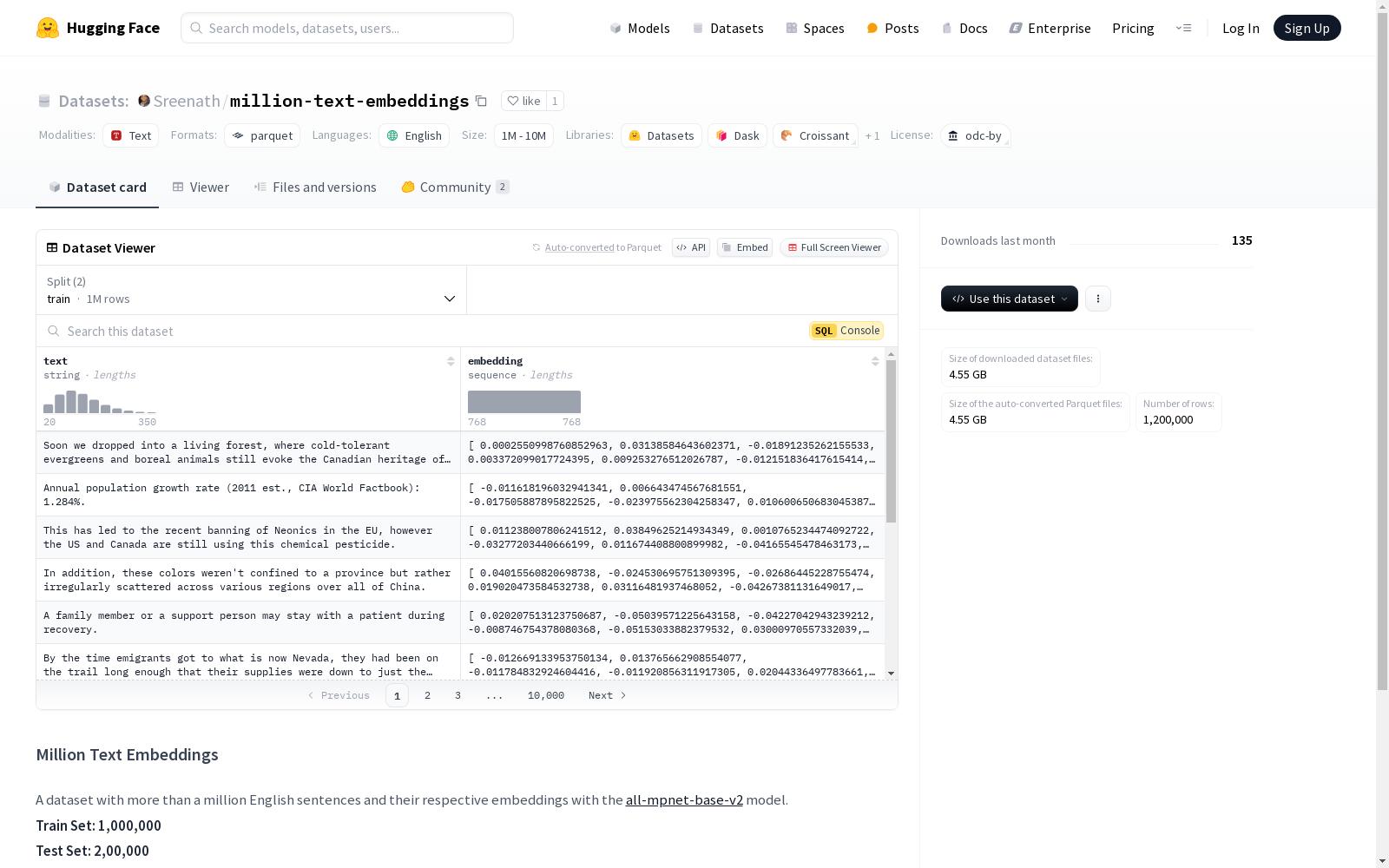
数据集包含一百万条英文句子及其对应的嵌入向量,使用all-mpnet-base-v2模型生成。每个嵌入向量的维度为768。数据集的源是sentence-transformers/agnews。数据集分为训练集,包含1000000个样本。
This dataset contains one million English sentences and their corresponding embedding vectors, which were generated using the all-mpnet-base-v2 model. Each embedding vector is 768-dimensional. The dataset is sourced from sentence-transformers/agnews, and it is split into a training set containing 1,000,000 samples.
创建时间:
2024-11-28
原始信息汇总
Million Text Embeddings 数据集概述
基本信息
- 语言: 英语
- 许可证: Open Data Commons Attribution License (ODC-BY)
- 配置: 默认配置
数据文件
- 训练集:
- 路径:
data/train-* - 样本数量: 1,000,000
- 字节数: 3,213,583,060
- 路径:
- 测试集:
- 路径:
data/test-* - 样本数量: 200,000
- 字节数: 642,710,945
- 路径:
数据集特征
- 文本: 字符串类型
- 嵌入: 浮点数序列 (float32)
数据集大小
- 下载大小: 13,632,873,927 字节
- 数据集大小: 3,856,294,005 字节
其他信息
- 维度: 768
- 源数据集: agentlans/high-quality-english-sentences
- GitHub 链接: sreenaths/hf-datasets
搜集汇总
数据集介绍
构建方式
Million Text Embeddings数据集的构建基于高质量的英文句子集合,通过使用all-mpnet-base-v2模型生成对应的文本嵌入。该数据集从agentlans/high-quality-english-sentences中提取了超过一百万个英文句子,并利用先进的自然语言处理技术,将这些句子转化为768维的向量表示。构建过程中,数据集被划分为训练集和测试集,分别包含100万和20万个样本,确保了数据的多样性和广泛性。
使用方法
Million Text Embeddings数据集适用于多种自然语言处理任务,如文本分类、语义相似度计算和句子嵌入生成。用户可以通过Hugging Face平台轻松下载数据集,并利用其提供的训练集和测试集进行模型训练和评估。数据集的嵌入向量可直接用于深度学习模型的输入,或作为预训练模型的补充数据。此外,用户还可以参考GitHub上的示例代码,快速上手并集成该数据集到自己的项目中,以提升模型的性能和泛化能力。
背景与挑战
背景概述
Million Text Embeddings数据集于近年由研究人员Sreenath S.及其团队创建,旨在为自然语言处理领域提供大规模的文本嵌入数据。该数据集包含超过一百万条英文句子及其对应的嵌入向量,这些嵌入向量通过all-mpnet-base-v2模型生成。数据集的原始文本来源于agentlans/high-quality-english-sentences,确保了文本的高质量和多样性。该数据集的发布为文本相似度计算、语义搜索等任务提供了重要的基础资源,推动了自然语言处理技术的发展。
当前挑战
Million Text Embeddings数据集在构建过程中面临多重挑战。首先,生成大规模高质量的文本嵌入需要强大的计算资源和高效的模型,这对硬件和算法提出了较高要求。其次,确保文本的多样性和代表性是另一个关键问题,避免数据偏差和重复现象需要精心设计数据采集和处理流程。此外,嵌入向量的维度选择和模型选择对最终的应用效果有显著影响,如何在保持高维度的同时降低计算复杂度是一个技术难题。最后,数据集的存储和传输也面临挑战,如何高效地管理和分发大规模数据是实际应用中不可忽视的问题。
常用场景
经典使用场景
在自然语言处理领域,Million Text Embeddings数据集广泛应用于文本相似度计算、语义搜索和文本分类等任务。通过提供超过一百万条英文句子及其对应的嵌入向量,该数据集为研究人员和开发者提供了一个强大的工具,用于训练和评估各种基于嵌入的模型。特别是在需要高精度语义理解的应用场景中,该数据集展现了其独特的价值。
解决学术问题
Million Text Embeddings数据集有效解决了文本表示学习中的关键问题,如如何在高维空间中捕捉语义信息、如何提升文本相似度计算的准确性等。通过使用all-mpnet-base-v2模型生成的嵌入向量,该数据集为研究者提供了一个标准化的基准,推动了文本嵌入技术的进一步发展,显著提升了相关学术研究的效率和效果。
实际应用
在实际应用中,Million Text Embeddings数据集被广泛用于构建智能客服系统、推荐系统和信息检索系统。通过利用该数据集中的嵌入向量,企业能够更准确地理解用户意图,提供个性化的服务。此外,该数据集还在教育、医疗等领域中发挥了重要作用,帮助开发出更智能的文本分析工具。
数据集最近研究
最新研究方向
在自然语言处理领域,文本嵌入技术作为语义表示的核心手段,近年来备受关注。Million Text Embeddings数据集凭借其百万级别的英文句子及其对应的嵌入向量,为研究者提供了丰富的语义分析资源。当前,该数据集在前沿研究中主要聚焦于大规模预训练模型的微调与优化,尤其是在多任务学习、跨语言迁移以及语义相似度计算等方向展现出显著的应用潜力。随着深度学习模型复杂度的提升,如何高效利用大规模嵌入数据进行模型训练与推理,成为研究热点之一。此外,该数据集在知识图谱构建、智能问答系统等实际应用场景中也发挥了重要作用,推动了自然语言处理技术的进一步发展。
以上内容由遇见数据集搜集并总结生成


