hiragana-dataset
收藏官方服务:
资源简介:
一个小型数据集,包含手写平假名字符的灰度图片,尺寸为83x84,涵盖50个不同的字符(所有46个平假名加上4个带有浊音或半浊音符号的平假名)。每个字符有20个样本,总计1000张图片。
A small dataset comprising grayscale images of handwritten Hiragana characters, each sized 83x84 pixels. It includes 50 distinct characters (all 46 basic Hiragana plus 4 additional characters with voiced or semi-voiced marks). Each character is represented by 20 samples, totaling 1000 images.
创建时间:
2017-04-30
原始信息汇总
hiragana-dataset 概述
数据集描述
- 类型: 手写平假名字符图像数据集
- 图像特征: 灰度图像,尺寸为 83x84
- 字符数量: 包含50个不同的平假名字符(46个基本平假名加上4个带有浊点或半浊点的平假名)
- 样本数量: 每个字符有20个样本,总计1000张图像
制作方法
- 使用Python程序结合图像处理技术,从扫描的纸张中提取每个单独的字符。
用途
- 适用于测试目的,如构建神经网络以识别不同的平假名,MATLAB导入脚本已提供。
搜集汇总
数据集介绍
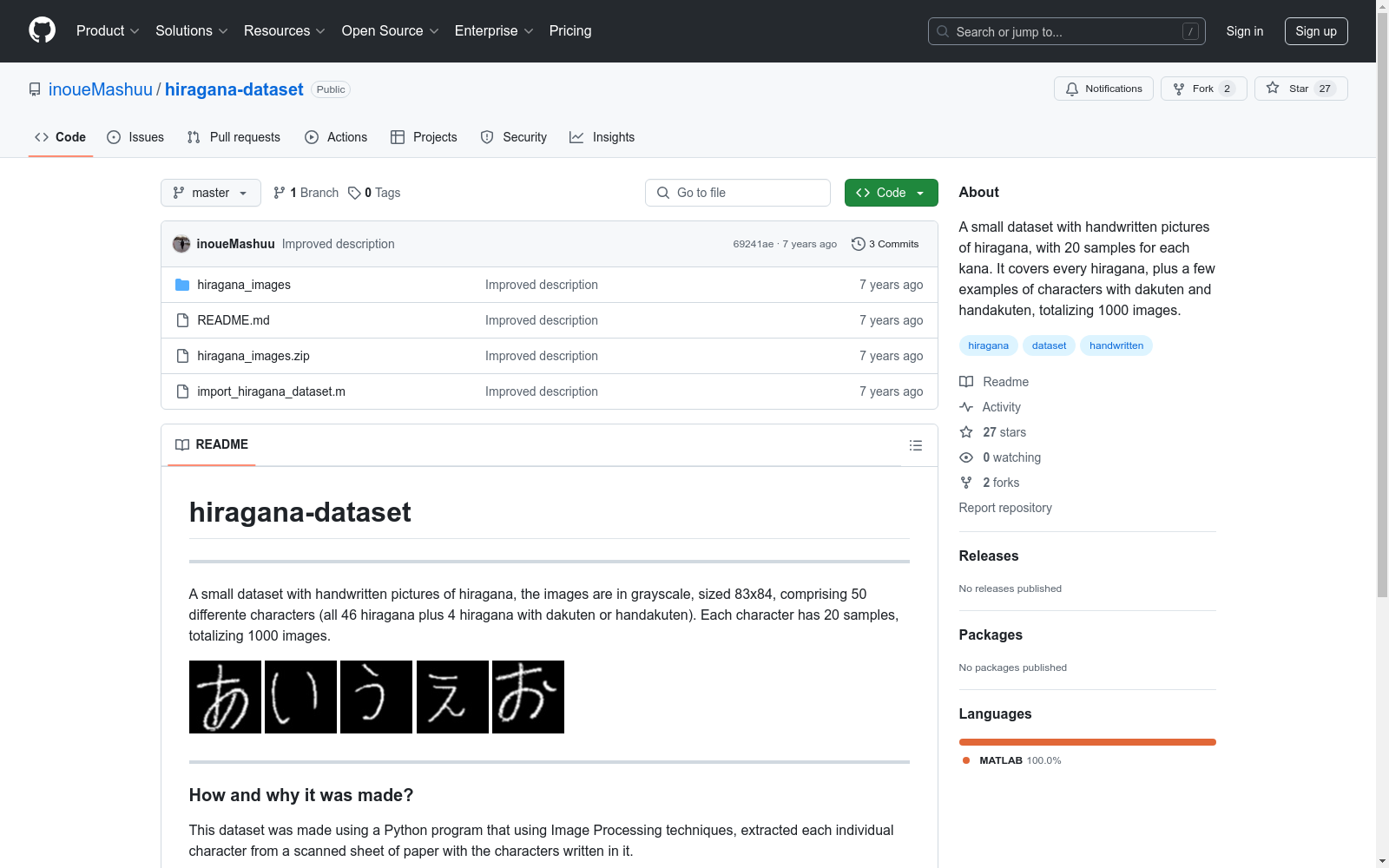
构建方式
该数据集通过Python程序结合图像处理技术构建而成,从扫描的纸张中提取出每个单独的平假名字符。具体而言,程序对扫描图像进行处理,分离出每个字符,并将其保存为灰度图像,尺寸为83x84像素。此过程确保了数据集的每个样本都具有一致的格式和质量,为后续的识别任务提供了基础。
特点
该数据集包含50个不同的平假名字符,其中包括46个基本字符及4个带有浊音或半浊音的字符。每个字符有20个样本,总计1000张图像。其特点在于图像均为灰度格式,尺寸统一,适合用于测试和训练神经网络等机器学习模型。尽管规模较小,但数据集的结构化和标准化使其成为初步实验和算法验证的理想选择。
使用方法
该数据集可用于开发和测试平假名字符识别的神经网络模型。用户可以通过提供的MATLAB导入脚本轻松加载数据集,进行模型训练和评估。此外,数据集的图像格式和数量使其适合于图像处理和模式识别领域的多种实验,如特征提取、分类算法测试等。使用者可根据具体需求调整和扩展数据集,以适应更复杂的应用场景。
背景与挑战
背景概述
在日语学习与计算机视觉的交叉领域,手写平假名识别成为一个备受关注的研究课题。hiragana-dataset由一位匿名研究者创建,旨在为手写平假名的识别任务提供一个小规模但实用的数据集。该数据集包含50个不同的平假名字符(包括46个基本字符及4个带有浊音或半浊音的字符),每个字符有20个样本,总计1000张灰度图像,尺寸为83x84像素。通过Python程序结合图像处理技术,从扫描的纸张中提取出每个单独的字符,为神经网络等机器学习模型的测试与训练提供了基础数据。
当前挑战
尽管hiragana-dataset为手写平假名识别提供了初步的数据支持,但其规模较小,仅适用于测试目的,难以满足深度学习模型对大规模数据的需求。此外,手写平假名的多样性,如笔画风格、书写角度和字符变形等,为模型的准确识别带来了挑战。在数据集构建过程中,如何高效地从复杂背景中提取并标准化手写字符,也是一项技术难题。
常用场景
经典使用场景
在机器学习和模式识别领域,hiragana-dataset常被用于开发和测试手写日语平假名识别算法。由于该数据集包含了50种不同的平假名字符,每种字符有20个样本,共计1000张灰度图像,因此非常适合用于训练和验证神经网络模型。例如,研究者可以使用该数据集来构建和优化基于MATLAB的神经网络,以实现对手写平假名的自动识别。
解决学术问题
hiragana-dataset在学术研究中主要解决了手写体识别中的多样性和复杂性问题。通过提供多样化的手写样本,该数据集帮助研究者探索和验证不同算法在处理手写字符时的性能,尤其是在处理字符变形、书写风格差异等方面。这不仅推动了手写识别技术的发展,也为日语学习辅助工具的开发提供了重要的数据支持。
衍生相关工作
基于hiragana-dataset,研究者们开发了多种手写识别算法,并将其应用于更广泛的日语字符识别任务中。例如,一些研究工作扩展了该数据集的应用范围,将其与其他日语字符数据集结合,用于开发多语言手写识别系统。此外,该数据集还激发了对手写体识别技术在教育、文化和商业领域的深入研究。
以上内容由遇见数据集搜集并总结生成


