LLF-Bench
收藏arXiv2023-12-13 更新2024-06-21 收录
下载链接:
https://microsoft.github.io/LLF-Bench
下载链接
链接失效反馈官方服务:
资源简介:
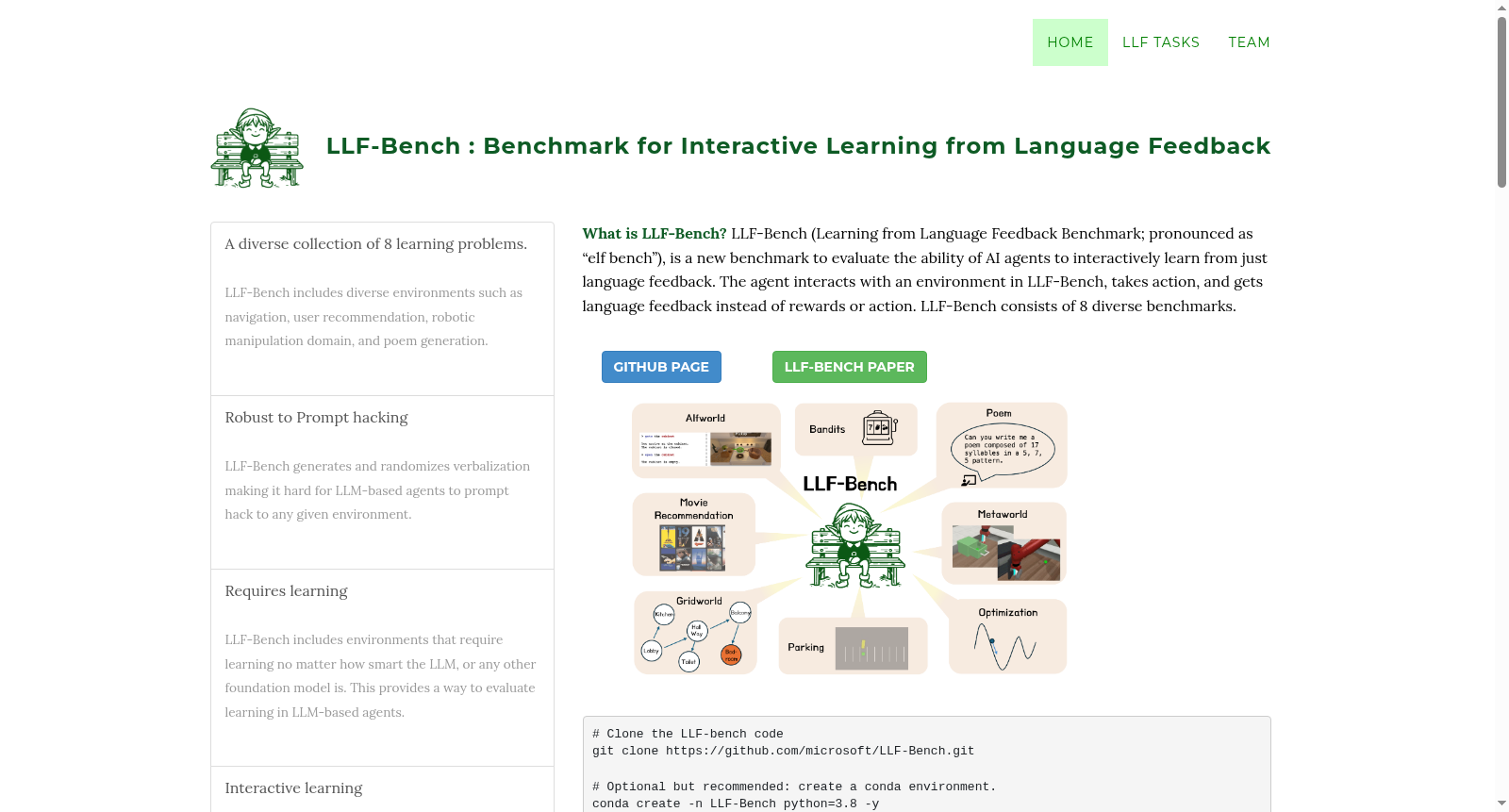
LLF-Bench是一个由微软研究院和斯坦福大学合作开发的综合性数据集,旨在评估AI代理通过自然语言反馈进行交互式学习的能力。该数据集包含8个子集,涵盖用户推荐、诗歌创作、导航和机器人控制等多个领域的序列决策任务。每个任务中,AI代理需根据自然语言指令和反馈来解决问题。LLF-Bench通过实施多种随机化技术,确保任务对代理来说是新颖的,从而测试其对不同表述的鲁棒性。此外,该数据集提供了一个统一的OpenAI Gym接口,使用户能够轻松配置反馈类型,研究代理对不同类型反馈的响应。LLF-Bench作为一个独特的研究平台,旨在推动和测试通过语言反馈学习的AI代理的发展。
LLF-Bench is a comprehensive dataset jointly developed by Microsoft Research and Stanford University, designed to evaluate the capability of AI Agents to perform interactive learning via natural language feedback. This dataset contains 8 subsets, covering sequential decision-making tasks across multiple domains including user recommendation, poetry creation, navigation, and robot control. In each task, the AI Agent is required to solve problems based on natural language instructions and feedback. LLF-Bench adopts various randomization techniques to ensure that tasks are novel to the AI Agents, thereby testing their robustness against diverse expressions. Additionally, the dataset provides a unified OpenAI Gym interface, enabling users to easily configure feedback types and study the AI Agents' responses to different types of feedback. As a unique research platform, LLF-Bench aims to promote and test the development of AI Agents that learn via language feedback.
提供机构:
微软研究院
创建时间:
2023-12-12
搜集汇总
数据集介绍
构建方式
在人工智能交互学习领域,LLF-Bench的构建体现了对语言反馈学习能力的系统性评估需求。该数据集通过整合八个多样化的顺序决策任务,包括用户推荐、诗歌创作、导航及机器人控制等,构建了一个统一且可配置的测试平台。其核心设计在于采用随机化技术,如指令转述和环境参数随机化,确保任务对智能体呈现新颖性,从而有效评估其从语言反馈中学习的能力,而非依赖先验知识。数据集遵循OpenAI Gym接口标准,提供了灵活的语言反馈配置选项,支持性能评估、行为建议和解释性反馈等多种反馈类型,为研究语言反馈学习机制奠定了坚实基础。
特点
LLF-Bench的显著特点在于其语言反馈系统的可配置性与多样性。数据集不仅涵盖了离散、连续及自由文本等多种动作空间,还通过精心设计的反馈分类体系,将语言反馈细分为即时性能评估、未来行为建议和过去行为解释三大类,模拟了人类教学中的丰富交互模式。此外,数据集引入了指令和反馈的模板化转述机制,通过语义等效的多样化表达,增强了智能体对语言变化的鲁棒性,有效防止了针对特定文本实现的过拟合。这些特性共同使LLF-Bench成为一个能够全面评估智能体从语言反馈中学习与泛化能力的独特研究平台。
使用方法
使用LLF-Bench时,研究人员可通过标准的OpenAI Gym接口与数据集交互,利用reset和step函数获取任务指令、环境观察及语言反馈。智能体应基于自然语言指令和反馈进行决策,而无需依赖隐藏的奖励信号,以此模拟真实世界中从语言指导中学习的过程。数据集支持多种反馈类型和指令模式的配置,允许用户根据研究需求定制学习信号。同时,通过文本包装器,LLF-Bench可适配基于大语言模型的智能体,便于评估其在多轮交互中的学习与决策行为,为开发高效的语言反馈学习算法提供实证基础。
背景与挑战
背景概述
在人工智能交互学习领域,自然语言反馈作为一种高效的知识传递机制,长期以来被视为提升智能体学习效率的关键途径。然而,传统强化学习范式主要依赖数值奖励信号,难以充分捕捉人类教学中丰富的语义信息。为此,微软研究院与斯坦福大学的研究团队于2023年共同推出了LLF-Bench基准测试平台,旨在系统评估智能体从自然语言反馈中交互式学习的能力。该数据集通过整合多臂老虎机、诗歌创作、机器人控制等八类序列决策任务,构建了覆盖离散、连续及自由文本动作空间的多样化测试环境。其核心创新在于将语言指令与反馈作为环境固有组成部分,并引入文本复述与环境随机化机制,以推动通用学习智能体的发展,为自然语言指导下的自适应学习研究奠定了重要基础。
当前挑战
LLF-Bench所针对的领域核心挑战在于如何使智能体像人类一样,通过自然语言反馈高效学习复杂任务,而非依赖传统的数值奖励机制。这要求智能体不仅需理解语言指令的语义,还需从反馈中提取结构化学习信号,实现跨任务的稳健泛化。在数据集构建过程中,研究团队面临多重技术难题:首先,需设计能够生成多样化且语义一致的指令与反馈的文本模板系统,以抵御智能体对特定文本表述的过拟合;其次,必须为连续控制、文本生成等异构任务建立统一的交互接口,同时确保环境参数的随机化不会破坏任务的可解性;此外,还需平衡反馈信息的丰富性与评估的客观性,避免合成反馈引入额外偏差。这些挑战共同指向了构建可靠语言反馈学习基准的复杂性。
常用场景
经典使用场景
在交互式人工智能与自然语言处理领域,LLF-Bench作为评估智能体从语言反馈中学习能力的基准平台,其经典应用场景聚焦于模拟多轮决策任务。该数据集通过整合用户推荐、诗歌创作、导航控制及机器人操作等多样化任务,构建了一个统一的OpenAI Gym接口环境。在此框架下,智能体需依据自然语言指令执行动作,并基于环境生成的语言反馈进行动态调整与学习,从而模拟人类在复杂环境中通过语言指导逐步优化行为的过程。
实际应用
在实际应用层面,LLF-Bench为构建适应性强、可交互的人工智能系统提供了关键支撑。例如,在个性化推荐系统中,智能体可通过解析用户语言反馈动态调整推荐策略;在机器人控制领域,操作员能以自然语言实时指导机械臂动作修正,降低专业设备依赖。数据集支持的可配置反馈类型(如建议、解释与即时表现评估)进一步模拟了真实教学场景,使得智能体能够在教育辅助、智能客服及自动化流程优化等场景中实现更自然、高效的人机协作。
衍生相关工作
围绕LLF-Bench衍生的经典研究主要集中于语言反馈的算法创新与基准扩展。例如,基于其框架的后续工作探索了大型语言模型在反馈理解中的泛化能力,并开发了结合提示工程与元学习的自适应策略。同时,该数据集启发了对多模态语言决策任务的延伸研究,如将视觉观察与语言指令融合的跨模态基准构建。此外,针对反馈类型的细粒度分析催生了新型评估指标,推动了交互式学习理论在语言驱动强化学习、人机对话系统等方向的深入发展。
以上内容由遇见数据集搜集并总结生成


