SLS-Bench
收藏Hugging Face2026-05-03 更新2026-05-04 收录
下载链接:
https://huggingface.co/datasets/anon-sls-bench/SLS-Bench
下载链接
链接失效反馈官方服务:
资源简介:
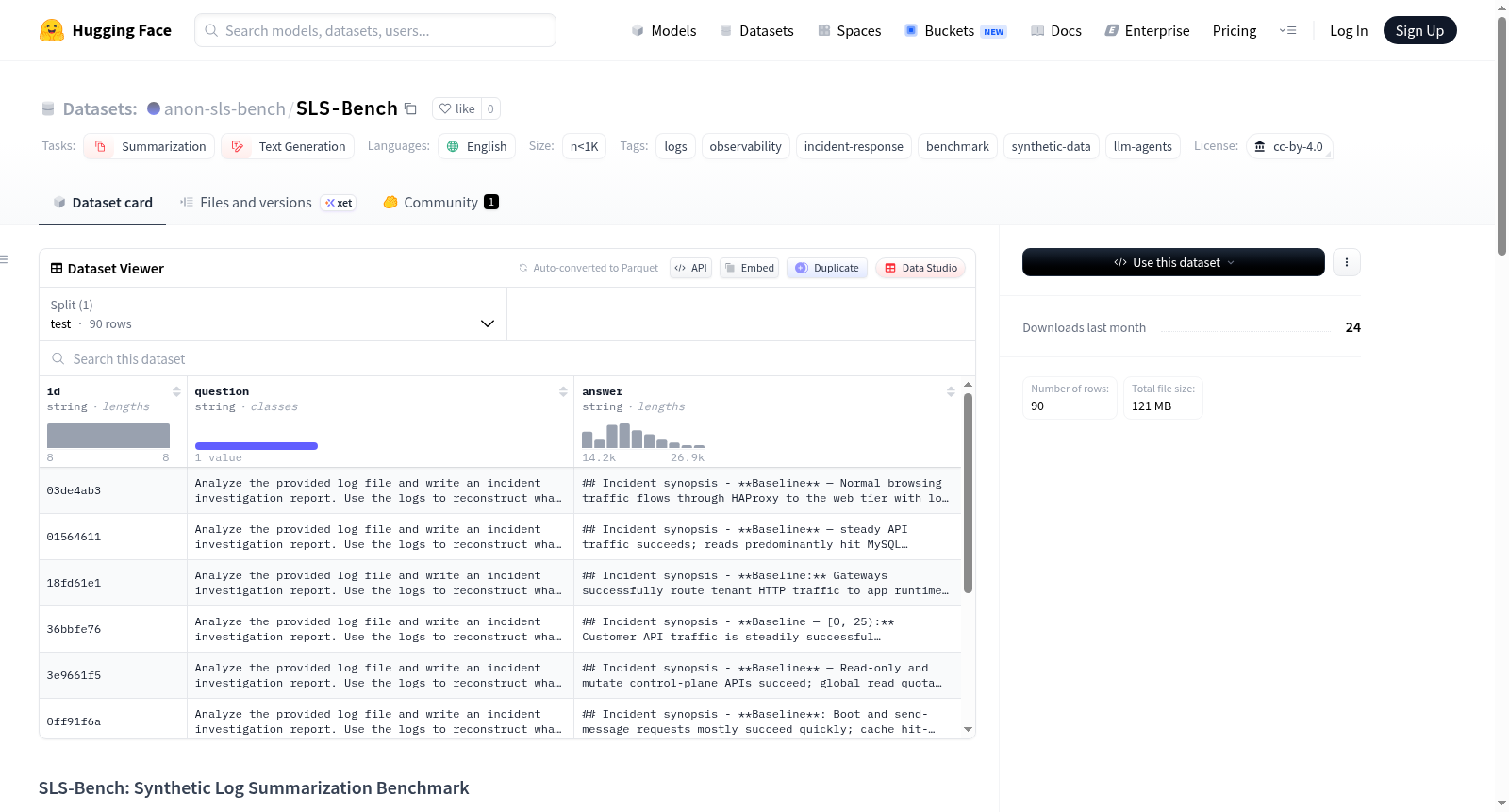
SLS-Bench是一个用于评估大型语言模型(LLM)代理在事件日志摘要任务上性能的合成基准数据集。该数据集包含90个事件日志摘要问题,每个问题包含唯一的ID、相同的问题文本、参考答案以及对应的事件日志流。日志数据以CSV格式存储,包含时间戳、日志级别、消息、跟踪ID、服务和主机等字段。数据集总大小约为830 MB(未压缩),每个问题的日志行数在21,393到95,503之间,参考答案长度在1,860到3,335个单词之间。该数据集专门用于评估目的,不适用于训练、实时分类或多模态评估。所有数据均为合成生成,不包含真实个人信息。数据集已验证可用于23种LLM模型的基准测试,并经过校准的LLM评委评估。主要风险包括对结果的过度依赖和将合成基准分数误认为操作准备度。
SLS-Bench is a synthetic benchmark dataset for evaluating the performance of large language model (LLM) agents on event log summarization tasks. The dataset contains 90 event log summarization problems, each with a unique ID, identical problem text, reference answers, and corresponding event log streams. The log data is stored in CSV format, containing fields such as timestamp, log level, message, trace ID, service, and host. The total dataset size is approximately 830 MB (uncompressed), with the number of log lines per problem ranging from 21,393 to 95,503, and reference answer lengths ranging from 1,860 to 3,335 words. This dataset is specifically designed for evaluation purposes and is not suitable for training, real-time classification, or multimodal evaluation. All data is synthetically generated and contains no real personal information. The dataset has been validated for benchmarking 23 LLM models and has been evaluated by calibrated LLM judges. Main risks include over-reliance on results and mistaking synthetic benchmark scores for operational readiness.
创建时间:
2026-05-02
原始信息汇总
数据集概述:SLS-Bench(合成日志摘要基准评估)
SLS-Bench 是一个用于评估 LLM(大语言模型)代理在日志摘要任务上表现的数据集。该数据集包含 90 个 从实际事件后分析报告中衍生的合成日志问题,以测试模型的日志压缩与关键信息提取能力。
核心文件与结构
| 文件 | 说明 |
|---|---|
problems.jsonl |
包含 90 条测试记录,每条记录有 3 个字段:id(唯一标识)、question(问题)、answer(参考答案)。所有问题相同,仅底层事件与参考答案不同。 |
logs.zip |
压缩包,解压后为 logs/<id>.csv 文件,每个文件对应一个问题的日志流。包含列:timestamp, level, message, trace_id, service, host。 |
统计信息
| 指标 | 最小值 | 中位数 | 最大值 |
|---|---|---|---|
| 日志行数(条) | 21,393 | 56,740 | 95,503 |
| 日志文件大小(MB) | 3.0 | 8.7 | 20.5 |
| 参考答案长度(词数) | 1,860 | 2,418 | 3,335 |
- 总问题数:90 个
- 总日志体积:解压后 ~830 MB
数据特征与合规说明
- 语言:英语(
en) - 任务类型:摘要(
summarization)、文本生成(text-generation) - 数据标签:日志、可观测性、事件响应、基准测试、合成数据、LLM 代理
- 数据量:<1 K(记录数小于 1000)
- 许可证:CC-BY-4.0
负责人工智能声明
| 方面 | 说明 |
|---|---|
| 局限 | 仅用于评估,不适用于训练、实时故障诊断、多模态评估或运维认证。 |
| 偏差 | 样本来源偏向于公开发布事后报告的组织;LLM 生成的内容继承了对广泛记录的技术的偏见。 |
| 个人信息 | 无。所有类似标识符的值均为合成生成。 |
| 使用场景 | 已验证可用于对 23 个 LLM 的基准进行校准评估,以评分摘要质量。 |
| 社会影响 | 若可靠,可减轻值班负担;主要风险是过度依赖及将合成基准分数视为运维就绪状态。 |
| 数据来源 | 完全合成,从公开的事件后报告通过 LLM 管道生成。 |
搜集汇总
数据集介绍
构建方式
SLS-Bench 是一个专为评估大语言模型在日志摘要任务中表现而设计的合成基准数据集。其构建灵感源自可观测性与故障响应领域对智能化事件总结的迫切需求,通过深度挖掘公开的事后复盘报告,借助大语言模型驱动的流水线生成了90个高度拟真的故障事件日志流与对应的参考摘要。每个样本包含一个独立的问题描述、基于相同格式的日志文件以及由专家级语言模型撰写的参考答案,确保评估任务具有一致的提法但迥异的故障场景。
特点
该数据集具有鲜明的合成性与可复现性,所有日志中的标识符、时间戳与消息内容均为完全虚构,从根本上规避了隐私与敏感信息泄露风险。数据规模控制在90个样本、约830MB解压后的日志体量,单个日志文件行数中位数超过五万七千行,参考摘要长度中位数约两千四百词,为深入测试长文本理解与压缩能力提供了恰到好处的挑战。每个问题共享同一提问模板,但日志流与答案的差异化则聚焦于评估模型对细微上下文变动的敏感度。
使用方法
使用 SLS-Bench 时,可通过 HuggingFace Datasets 库直接加载问题集,随后解压 logs.zip 并依据样本 ID 读取对应的 CSV 日志文件,形成“问题-日志-标准答案”的三元组。此外,数据集支持通过 ML Croissant 格式进行语义化访问,便于在多模态工作流中整合。该基准主要用于离线评测场景,搭配预先校准的大语言模型裁判,对生成摘要进行质量打分,从而对比不同代理在结构化日志摘要任务上的表现差异。
背景与挑战
背景概述
SLS-Bench(Synthetic Log Summarization Benchmark)是一个专为评估大语言模型(LLM)代理在日志摘要任务中表现而设计的基准数据集,由匿名研究团队于近年创建。在大规模分布式系统运维领域,日志数据是故障排查与事件响应的核心依据,而事件后总结(postmortem)的自动生成能显著减轻运维人员的认知负担。SLS-Bench基于90个从真实公开事件后报告中提取并经由LLM管道合成的故障场景,每个场景提供从2万至9.5万行不等的结构化日志流以及人工校对的参照摘要。该数据集聚焦于评估LLM代理从海量、嘈杂的日志流中提炼关键故障信息的能力,填补了现有日志分析基准在端到端摘要生成任务上的空白。其发布推动了可观测性领域LLM应用的效果评测标准化,为智能运维(AIOps)的自动化事件总结提供了可靠的评估标杆。
当前挑战
SLS-Bench所解决的领域问题核心挑战在于:自动化日志摘要任务需同时应对日志数据的高噪性、异构性及事件上下文的多样性,现有模型常因缺乏结构化理解而输出冗长或无关的内容。构建过程中的主要挑战包括:一、需从公开事件后报告中提取关键事件轨迹,并借助LLM生成高度仿真的合成日志流与参考摘要,确保场景覆盖广泛的故障类型与技术栈;二、日志规模庞大(单个场景日志文件可达20MB),导致评估时对LLM的上下文窗口与推理效率提出严苛要求;三、为避免信息泄露与隐私风险,所有标识符与敏感信息均须完全合成,同时保证合成数据与实际运维场景在统计特征上的分布一致性。最终,数据集的设计还需规避选择偏倚,确保不同技术环境下的事件总结能力均能被公平评估。
常用场景
经典使用场景
在可观测性工程与智能运维领域,SLS-Bench作为一项开创性的合成日志摘要基准测试,其核心使用场景聚焦于评估大语言模型代理在真实规模日志数据上的摘要生成能力。该数据集精心构建了90个涵盖不同故障类型的日志流实例,每个实例包含数万行多维度日志记录(时间戳、级别、消息、追踪ID、服务及主机),并配有专家级参考摘要。研究者通常利用此基准对LLM日志摘要代理进行系统性评估,通过对比模型输出与黄金标准摘要,量化模型在提取关键事件、识别根因、压缩信息噪声等方面的表现。这一场景直接服务于运维智能化的核心需求——将海量、高噪、时序耦合的日志转化为人类可快速理解的故障叙事。
解决学术问题
SLS-Bench直面了运维大语言模型评估中长期存在的两大困境:缺乏领域专用的大规模评估基准,以及真实数据涉及的隐私与标注成本高昂。传统总结评测如CNN/DailyMail聚焦新闻文体,无法直接迁移至技术日志的稀疏语义与异常模式。该数据集通过合成数据技术,从公开事后剖析报告中提取故障模式并生成带标注的日志流,为学术界提供首个可控、可复现的日志摘要评测平台。它系统性地解决了日志摘要质量量化问题,使研究者能够深入分析模型对跨服务调用链的还原能力、对非常规日志模式的敏感度,以及摘要的时效性与完整性之间的平衡,推动了从通用文本压缩到领域认知摘要的范式跃迁。
衍生相关工作
SLS-Bench的发布催生了一系列围绕日志智能处理的高影响力工作,形成了从评测基准到方法论的全链条创新。在基准验证层面,研究者基于该数据集构建了包含23个LLM的校准裁判集成,证明了GPT-4、Claude等模型在日志摘要品质打分上可作为可靠代理指标。在模型优化方向,社区涌现出旨在提升日志语义压缩率的稀疏注意力变体,以及融合时间序列与日志文本的多模态摘要框架。数据合成技术同样得到推进,衍生出从公开SRE报告半自动生成训练样本的流水线,并探索了将SLS-Bench的评估协议引入更广泛的时序数据处理任务(如告警关联与根因定位)。这些工作共同勾勒出从人工规则驱动的运维自动化迈向大模型认知驱动的可观测性智能化的演进路线图。
以上内容由遇见数据集搜集并总结生成


