REPLIQA
收藏arXiv2024-06-18 更新2024-06-19 收录
下载链接:
https://huggingface.co/datasets/ServiceNow/repliqa
下载链接
链接失效反馈官方服务:
资源简介:
REPLIQA是由ServiceNow Research和Mila – 魁北克人工智能研究所创建的一个新型问答数据集,旨在评估大型语言模型在未见过的参考内容上的表现。该数据集包含约90,000个问答对,基于18,000个由人类注释者创作的虚构情景参考文档。数据集的创建过程涉及雇佣第三方内容创作者和注释者,确保数据的新颖性和不可预测性。REPLIQA特别适用于评估模型在开放域问答和文档主题检索任务上的能力,旨在解决现有数据集可能存在的数据泄露问题,确保评估的公正性和准确性。
REPLIQA is a novel question answering dataset developed by ServiceNow Research and Mila – Quebec Artificial Intelligence Institute, which aims to evaluate the performance of Large Language Models (LLMs) on unseen reference content. The dataset contains approximately 90,000 QA pairs, derived from 18,000 fictional scenario reference documents created by human annotators. The dataset construction process involves hiring third-party content creators and annotators to ensure the novelty and unpredictability of the data. REPLIQA is particularly suitable for evaluating a model's capabilities in open-domain question answering and document topic retrieval tasks, and aims to address potential data leakage issues in existing datasets to ensure the fairness and accuracy of the evaluations.
提供机构:
ServiceNow Research 和 Mila – 魁北克人工智能研究所
创建时间:
2024-06-18
搜集汇总
数据集介绍
构建方式
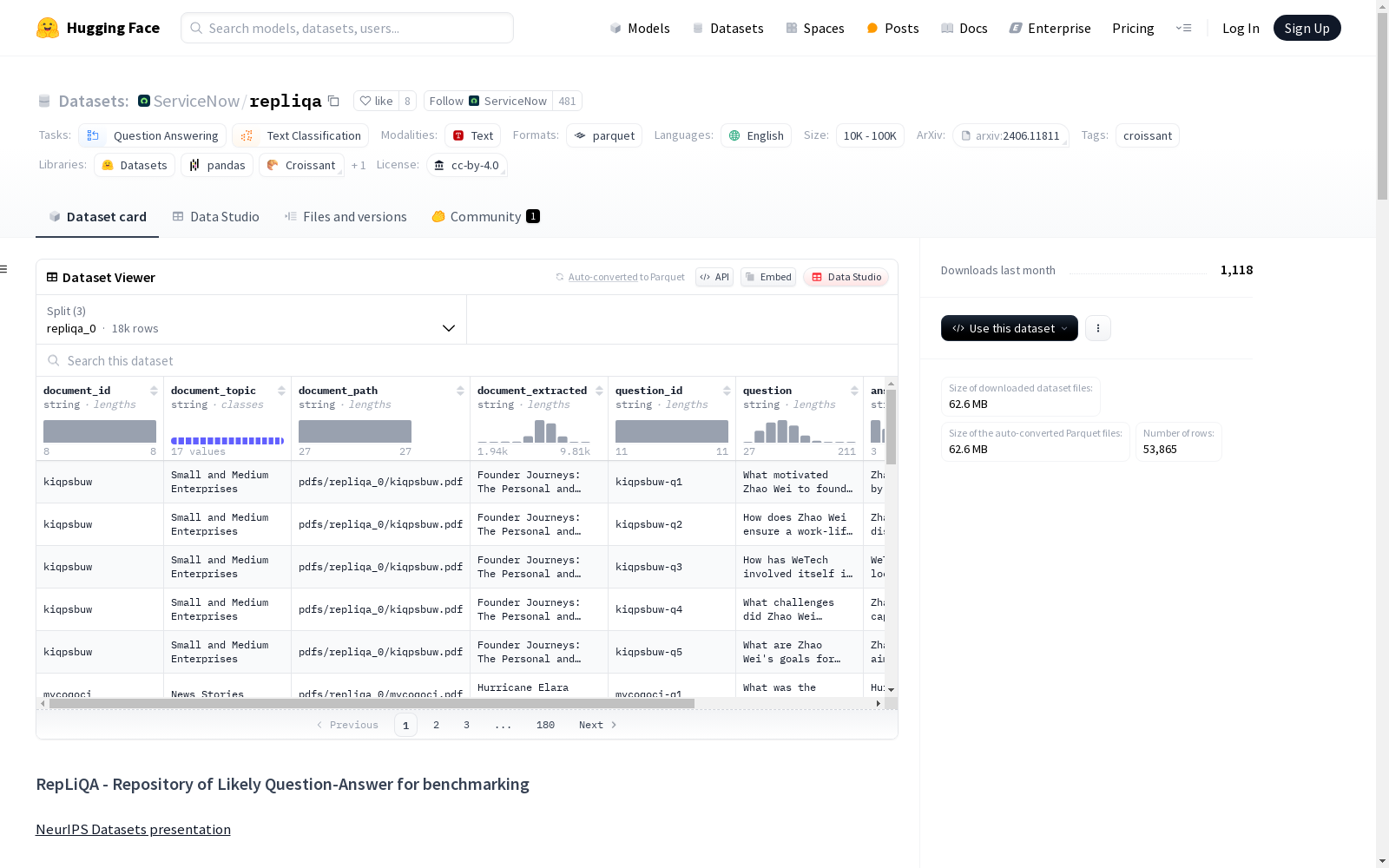
REPLIQA数据集的构建过程经过精心设计,旨在评估大型语言模型(LLMs)在未见过的参考内容上的表现。首先,研究团队通过外包公司聘请了80-90名内容创作者,负责撰写虚构的参考文档,涵盖17个不同的主题。这些文档均为人工创作,确保其内容与互联网上的现有信息无重叠。随后,40-50名注释者为每个文档生成5个问题及其对应的答案,确保答案仅能从提供的文档中得出。整个过程经过严格的质量控制,包括同行评审和专家审查,以确保数据的准确性和一致性。最终,数据集被划分为五个部分,采用分阶段发布策略,以减少数据泄露的风险。
特点
REPLIQA数据集的核心特点在于其内容的独特性和多样性。每个样本包含一个虚构的参考文档、一个相关问题、一个基于文档的答案以及包含答案的文档段落。所有文档均为人工创作,确保其内容与互联网上的现有信息无重叠,从而避免了数据污染问题。此外,数据集的17个主题涵盖了广泛的领域,如网络安全、本地新闻、区域民俗等,确保了数据的多样性和代表性。REPLIQA还包含约20%的无法回答的问题,进一步增强了数据集的挑战性。
使用方法
REPLIQA数据集主要用于评估大型语言模型在未见过的参考内容上的问答和主题检索能力。用户可以通过Hugging Face平台访问和下载数据集。为了确保评估的公正性,建议用户在使用数据集时,明确说明所使用的数据分割(如REPLIQA0或最新发布的分割),并分别报告每个分割的结果。此外,用户可以通过比较不同模型在REPLIQA和传统数据集(如TRIVIAQA)上的表现,来评估模型在未见内容上的泛化能力。数据集的分阶段发布策略也允许用户在数据泄露风险较低的情况下进行长期评估。
背景与挑战
背景概述
REPLIQA数据集由ServiceNow Research和Mila – Québec Artificial Intelligence Institute的研究团队于2024年6月发布,旨在为大语言模型(LLMs)在未见过的参考内容上的表现提供基准测试。该数据集的核心研究问题在于解决现有基准数据集可能被LLMs训练数据污染的问题,从而确保模型评估的准确性。REPLIQA包含17,954篇由人工编写的虚构参考文档,每篇文档配有五个问题-答案对,确保答案仅能从提供的文档中获取。该数据集的发布方式采用分阶段逐步公开的策略,以避免数据泄露到LLMs的训练集中。REPLIQA的推出为评估LLMs在开放域问答和文档主题检索任务中的表现提供了新的标准,推动了语言模型评估的透明性和可靠性。
当前挑战
REPLIQA数据集在构建和应用过程中面临多重挑战。首先,数据集的创建需要确保所有参考文档和问题-答案对均为全新且未在互联网上公开的内容,以避免数据污染。这一要求使得文档的编写和问题的设计必须高度依赖人工创造力,且需通过严格的审核流程确保其独特性和质量。其次,数据集的构建过程中,如何平衡文档的多样性与一致性也是一个重要挑战,尤其是在涉及虚构场景和实体时,需确保内容的合理性和逻辑性。此外,数据集的逐步发布策略虽然有效延缓了数据泄露的风险,但也增加了数据集管理和维护的复杂性。最后,如何在大规模基准测试中准确评估LLMs的表现,尤其是在模型依赖内部记忆而非参考文档的情况下,仍然是一个亟待解决的问题。
常用场景
经典使用场景
REPLIQA数据集主要用于评估大型语言模型(LLMs)在未见过的参考内容上的问答能力。其经典使用场景包括在开放域问答任务中,模型需要基于提供的参考文档生成准确的答案。通过设计虚构的场景和文档,REPLIQA确保了模型无法依赖预训练中的记忆,从而真正测试其理解和推理能力。
衍生相关工作
REPLIQA的发布推动了多个相关研究工作的进展。例如,基于REPLIQA的评估结果,研究者们进一步探索了模型在检索增强生成(RAG)任务中的表现。此外,REPLIQA的设计理念也启发了其他领域的数据集构建,特别是在确保数据新颖性和评估公正性方面。
数据集最近研究
最新研究方向
近年来,随着大语言模型(LLMs)的快速发展,评估这些模型在未见数据上的表现成为了研究的热点。REPLIQA数据集的推出正是为了应对这一挑战,尤其是在问答和主题检索任务中,确保模型的表现不依赖于训练数据的记忆。该数据集通过引入虚构的参考文档和问题-答案对,避免了数据泄露问题,从而为模型提供了全新的测试环境。当前的研究方向主要集中在如何通过REPLIQA评估模型在上下文条件下的阅读理解能力,尤其是在面对未见内容时的表现。此外,研究还探讨了模型规模对性能的影响,发现较大的模型虽然在记忆能力上表现优异,但在阅读理解任务中并不总是优于较小的模型。这一发现为未来的模型优化提供了新的思路,尤其是在检索增强生成(RAG)等实际应用场景中。
相关研究论文
- 1RepLiQA: A Question-Answering Dataset for Benchmarking LLMs on Unseen Reference ContentServiceNow Research 和 Mila – 魁北克人工智能研究所 · 2024年
以上内容由遇见数据集搜集并总结生成


