langcache-crossencoder-data
收藏Hugging Face2025-08-05 更新2025-08-06 收录
下载链接:
https://huggingface.co/datasets/aditeyabaral-redis/langcache-crossencoder-data
下载链接
链接失效反馈官方服务:
资源简介:
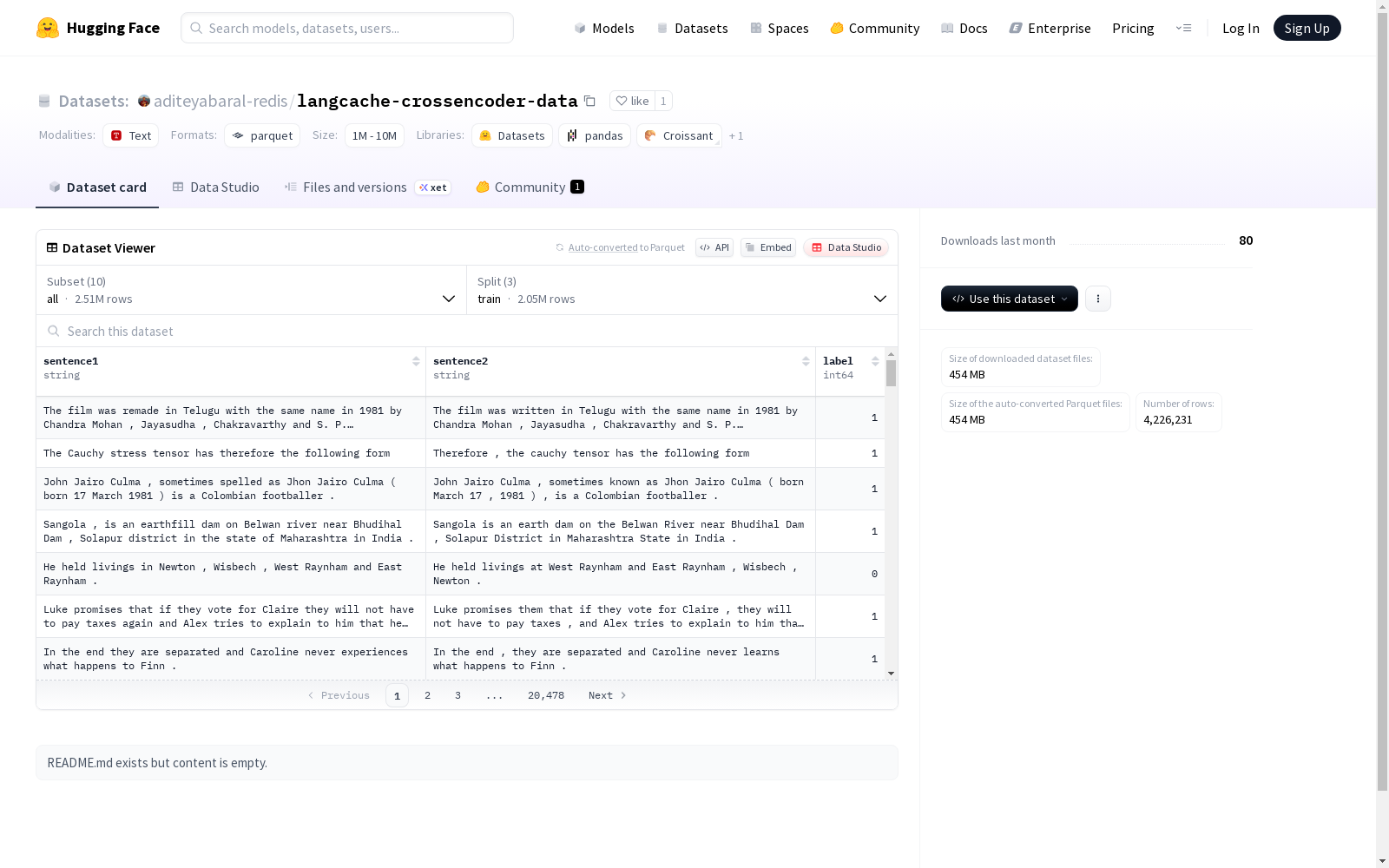
这是一个包含多个子数据集的集合,每个子数据集都包含句子对和相应的标签。具体用途可能涉及文本分类或判断句子间的相似度。数据集分为训练集、验证集和测试集,适用于机器学习模型的训练和评估。
创建时间:
2025-08-05
原始信息汇总
数据集概述
基本信息
- 数据集名称: langcache-crossencoder-data
- 数据集地址: https://huggingface.co/datasets/aditeyabaral-redis/langcache-crossencoder-data
数据集配置
数据集包含以下配置:
- all
- apt
- mrpc
- parade
- paws
- pit2015
- qqp
- sick
- stsb
- ttic31190
通用特征
所有配置均包含以下特征:
- sentence1: 字符串类型
- sentence2: 字符串类型
- label: 整型(int64)
各配置详情
1. all
- 训练集: 2,047,713 条样本,326,590,348 字节
- 验证集: 49,653 条样本,6,708,829 字节
- 测试集: 413,370 条样本,57,838,563 字节
- 下载大小: 261,668,579 字节
- 数据集大小: 391,137,740 字节
2. apt
- 训练集: 3,746 条样本,560,405 字节
- 测试集: 1,261 条样本,192,293 字节
- 下载大小: 241,861 字节
- 数据集大小: 752,698 字节
3. mrpc
- 训练集: 3,668 条样本,929,171 字节
- 验证集: 408 条样本,104,247 字节
- 测试集: 1,725 条样本,435,510 字节
- 下载大小: 995,696 字节
- 数据集大小: 1,468,928 字节
4. parade
- 训练集: 7,550 条样本,1,761,250 字节
- 验证集: 1,275 条样本,293,719 字节
- 测试集: 1,357 条样本,319,262 字节
- 下载大小: 769,767 字节
- 数据集大小: 2,374,231 字节
5. paws
- 训练集: 645,652 条样本,155,223,868 字节
- 测试集: 10,000 条样本,2,402,165 字节
- 下载大小: 108,634,033 字节
- 数据集大小: 157,626,033 字节
6. pit2015
- 训练集: 13,063 条样本,1,345,346 字节
- 验证集: 4,727 条样本,462,242 字节
- 测试集: 972 条样本,94,569 字节
- 下载大小: 596,490 字节
- 数据集大小: 1,902,157 字节
7. qqp
- 训练集: 363,846 条样本,49,445,436 字节
- 验证集: 40,430 条样本,5,492,034 字节
- 测试集: 390,965 条样本,53,607,251 字节
- 下载大小: 69,155,510 字节
- 数据集大小: 108,544,721 字节
8. sick
- 训练集: 4,439 条样本,481,342 字节
- 验证集: 495 条样本,54,519 字节
- 测试集: 4,906 条样本,531,654 字节
- 下载大小: 347,239 字节
- 数据集大小: 1,067,515 字节
9. stsb
- 训练集: 5,749 条样本,754,791 字节
- 验证集: 1,500 条样本,216,064 字节
- 测试集: 1,379 条样本,169,974 字节
- 下载大小: 707,456 字节
- 数据集大小: 1,140,829 字节
10. ttic31190
- 训练集: 1,000,000 条样本,116,088,739 字节
- 验证集: 818 条样本,86,004 字节
- 测试集: 805 条样本,85,885 字节
- 下载大小: 80,228,243 字节
- 数据集大小: 116,260,628 字节
搜集汇总
数据集介绍
构建方式
在自然语言处理领域,langcache-crossencoder-data数据集通过整合多个经典文本语义匹配任务构建而成。该数据集采用模块化设计理念,包含all、apt、mrpc等10种独立配置,每个配置均包含训练集、验证集和测试集的标准划分。数据构建过程中严格保持原始语料的文本对结构和标签体系,sentence1和sentence2字段完整保留了文本对的原始表述,label字段则采用int64类型统一编码语义关系标签。
特点
该数据集最显著的特点是具备多任务协同的架构设计,总规模超过200万样本,其中paws子集包含64万训练样本,ttic31190子集达到百万量级。各子集保持统一的特征空间设计,均包含文本对和分类标签三元组结构,但针对不同语义匹配场景进行了专业划分,如parade侧重释义识别,stsb专攻语义相似度评分。数据分布呈现显著差异化,从apt子集的3746个训练样本到all配置的204万样本,为模型提供多粒度测试环境。
使用方法
使用该数据集时可根据研究需求灵活选择配置模式,完整训练可加载all配置获取集成数据,特定领域研究则可调用如mrpc或qqp等独立子集。数据集采用标准HuggingFace格式组织,通过指定config_name参数即可访问不同子集,每个子集均预置train/validation/test标准划分。典型应用场景包括加载paws子集进行对抗性文本对分类训练,或使用stsb子集进行语义相似度回归分析,模型验证阶段可跨子集测试泛化能力。
背景与挑战
背景概述
langcache-crossencoder-data数据集是一个专注于文本语义匹配任务的大规模语料库,整合了包括PAWS、QQP、MRPC在内的多个经典自然语言处理数据集。该数据集由研究团队在深度学习与自然语言理解技术快速发展的背景下构建,旨在为跨编码器模型(Cross-Encoder)提供统一的训练与评估基准。通过融合不同领域和场景的文本对数据,该数据集显著提升了模型在语义相似度计算、复述识别等任务上的泛化能力,成为近年来预训练语言模型微调研究的重要基础设施之一。
当前挑战
该数据集面临的核心挑战体现在语义标注的复杂性与数据异构性两方面。不同子数据集采用差异化的标注标准(如二分类标签与连续分数并存),导致跨域迁移学习时需解决标签空间对齐问题。构建过程中需克服原始数据质量参差不齐的困难,例如部分语料存在标注噪声或领域偏移现象。此外,超大规模样本的整合对计算资源提出极高要求,如何在保证数据多样性的同时实现高效存储与读取,成为工程技术层面的关键挑战。
常用场景
经典使用场景
在自然语言处理领域,langcache-crossencoder-data数据集广泛应用于文本相似度计算和句子对分类任务。该数据集整合了多个经典子集,如MRPC、PAWS和QQP等,为研究者提供了丰富的句子对标注数据,用于训练和评估跨编码器模型。通过该数据集,研究者能够深入探索句子间的语义相似性和逻辑关联,为文本匹配任务提供可靠基准。
实际应用
在实际应用中,langcache-crossencoder-data数据集被广泛应用于搜索引擎、智能客服和推荐系统等场景。例如,在搜索引擎中,该数据集训练的模型能够精准匹配用户查询与相关文档,提升搜索结果的相关性。在智能客服领域,模型通过分析用户问题与知识库中的句子对,实现高效的自动问答功能。
衍生相关工作
基于langcache-crossencoder-data数据集,研究者们开发了多种先进的跨编码器模型,如BERT-based和RoBERTa-based的文本匹配模型。这些模型在多项自然语言处理任务中取得了显著成果,例如语义文本相似度(STS)和复述检测(Paraphrase Detection)。该数据集还催生了一系列优化方法,如动态负采样和难例挖掘技术,进一步推动了文本匹配领域的发展。
以上内容由遇见数据集搜集并总结生成


