KIMI-K2.5-700000x
收藏Hugging Face2026-04-03 更新2026-04-04 收录
下载链接:
https://huggingface.co/datasets/ianncity/KIMI-K2.5-700000x
下载链接
链接失效反馈官方服务:
资源简介:
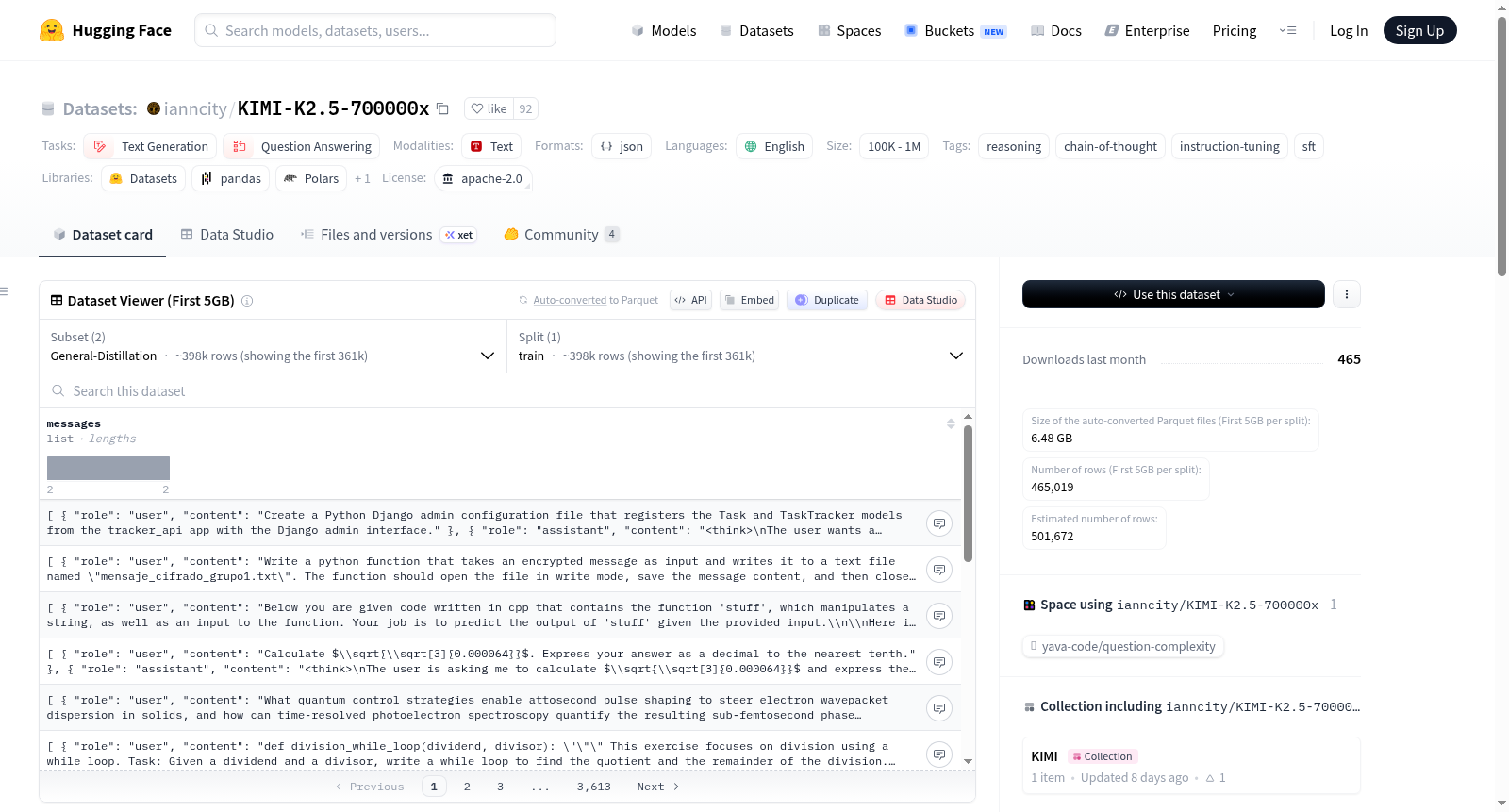
KIMI-K2.5-700000x 是一个包含 700,000 个推理痕迹的数据集,适用于文本生成和问答任务,特别强调推理和指令调优。数据集涵盖了编程(50%)、科学(20%)、数学(15%)、计算机科学(5%)、逻辑问题(5%)和创意写作(5%)等多个领域。科学子集 PHD-Science 额外包含 100,000 个完成样本。数据集总令牌数为 2.5B。数据收集使用了 TeichAI 的改进版 Datagen,耗时约 80 小时。数据集采用 Apache-2.0 许可证,语言为英语,规模在 100K 到 1M 之间。
创建时间:
2026-03-26
原始信息汇总
数据集概述
基本信息
- 数据集名称: KIMI-K2.5-700000x
- 许可证: apache-2.0
- 主要语言: 英语 (en)
- 数据规模: 100K<n<1M
- 任务类别: 文本生成 (text-generation)、问答 (question-answering)
- 标签: 推理 (reasoning)、思维链 (chain-of-thought)、指令微调 (instruction-tuning)、监督微调 (sft)
数据内容与结构
- 总数据量: 700,000 条推理轨迹
- 数据来源: 从
KIMI-K2.5蒸馏而来,侧重于高级推理 (highreasoning) - 总词元数: 2.5B
数据分布
- 编程: 50% (包含: Web开发、Python、C++、Java、JS、C、Ruby、Lua、Rust、C#)
- 科学: 20% (物理、化学、生物) - 在 PHD-Science 子集中额外包含 100k 条补全
- 数学: 15% (代数、微积分、概率)
- 计算机科学: 5%
- 逻辑问题: 5%
- 创意写作: 5%
配置与文件
数据集包含两个配置,每个配置对应一个数据文件:
-
配置名称: General-Distillation
- 文件路径:
kimi-k2.5-main.jsonl - 拆分: 训练集 (train)
- 文件路径:
-
配置名称: PHD-Science
- 文件路径:
KimiK-2.5-PHD-Science.jsonl - 拆分: 训练集 (train)
- 文件路径:
数据收集
- 收集方法: 使用由 TeichAI 修改的 Datagen 工具收集
- 收集时长: 约 80 小时
搜集汇总
数据集介绍
构建方式
在人工智能领域,高质量推理数据对于提升模型逻辑思维能力至关重要。KIMI-K2.5-700000x数据集的构建采用了经过改进的Datagen技术,由TeichAI团队在约80小时内高效完成数据生成。该过程专注于从KIMI-K2.5模型中蒸馏出70万条高质量推理轨迹,特别强化了复杂推理能力的提取,确保了数据在逻辑链条上的深度与连贯性。
特点
该数据集在内容分布上展现出高度的多样性与专业性,其中编程相关数据占比50%,覆盖Web开发、Python、C++等多种语言;科学领域占20%,并额外包含10万条博士级科学子集数据;数学与计算机科学分别占15%和5%。整体数据规模达到25亿标记,为模型训练提供了丰富的语义与逻辑素材。
使用方法
数据集适用于文本生成与问答任务,尤其能够支持思维链推理和指令微调。用户可通过加载General-Distillation或PHD-Science配置来访问不同子集,数据以JSONL格式存储,便于直接用于监督微调流程。该资源为开发高级推理模型提供了扎实的基础,助力研究者在复杂问题求解领域取得进展。
背景与挑战
背景概述
随着大型语言模型在复杂推理任务上的需求日益增长,高质量的指令微调与思维链数据成为提升模型性能的关键。KIMI-K2.5-700000x数据集应运而生,由TeichAI团队于近期通过改进的Datagen方法在约80小时内构建完成。该数据集专注于从KIMI-K2.5模型中蒸馏出70万条高难度推理轨迹,覆盖编程、科学、数学、计算机科学、逻辑问题及创意写作等多个领域,旨在为文本生成与问答任务提供丰富的监督信号,推动模型在深层推理与跨学科问题解决能力上的进步。
当前挑战
在解决复杂推理与指令遵循的领域问题时,该数据集面临生成高质量、多样化思维链的挑战,需确保推理轨迹的逻辑严谨性与学科准确性。构建过程中,挑战集中于从源模型高效蒸馏大规模数据,同时维持编程、物理、化学等专业内容的精确性,并平衡不同学科的比例以支持广泛的泛化能力。此外,处理高达25亿的令牌数量对数据清洗、存储与处理流程提出了显著的技术要求。
常用场景
经典使用场景
在人工智能领域,特别是大型语言模型的推理能力优化中,KIMI-K2.5-700000x数据集凭借其丰富的思维链数据,为模型训练提供了关键支撑。该数据集涵盖了编程、科学、数学等多个高难度推理领域,其中编程任务占比高达50%,科学类任务占20%,数学任务占15%,这些数据通过蒸馏技术从KIMI-K2.5模型中提取,形成了700,000条高质量的推理轨迹。研究人员通常利用这些轨迹进行指令微调或监督微调,以增强模型在复杂问题上的逐步推理能力,特别是在代码生成、科学问题解答和逻辑推理等场景中,模型能够模仿人类思维过程,产生更准确、连贯的输出。
实际应用
在实际应用中,KIMI-K2.5-700000x数据集被广泛用于开发智能辅助工具,如代码自动生成系统、教育领域的解题助手以及科研分析平台。例如,在软件开发中,模型基于数据集的编程部分可以生成高质量的代码片段;在科学教育中,它帮助学生理解物理、化学等学科的推理过程;在逻辑决策支持系统中,模型能提供清晰的推理路径,增强用户对AI输出的信任。这些应用提升了生产效率和学习体验,体现了数据集在现实场景中的实用价值。
衍生相关工作
围绕该数据集,衍生出多项经典研究工作,主要集中在推理模型的优化和扩展上。例如,研究人员利用其思维链数据开发了更高效的指令微调方法,提升了模型在少样本学习中的表现;同时,基于数据集的科学子集,出现了专注于高级科学问题解答的专用模型,这些工作进一步推动了人工智能在专业领域的应用。此外,数据集还促进了跨领域推理任务的研究,为后续大规模推理数据集的构建提供了参考范式,丰富了人工智能生态。
以上内容由遇见数据集搜集并总结生成


