Mgnify
收藏Hugging Face2026-05-11 更新2026-05-13 收录
下载链接:
https://huggingface.co/datasets/LiteFold/Mgnify
下载链接
链接失效反馈官方服务:
资源简介:
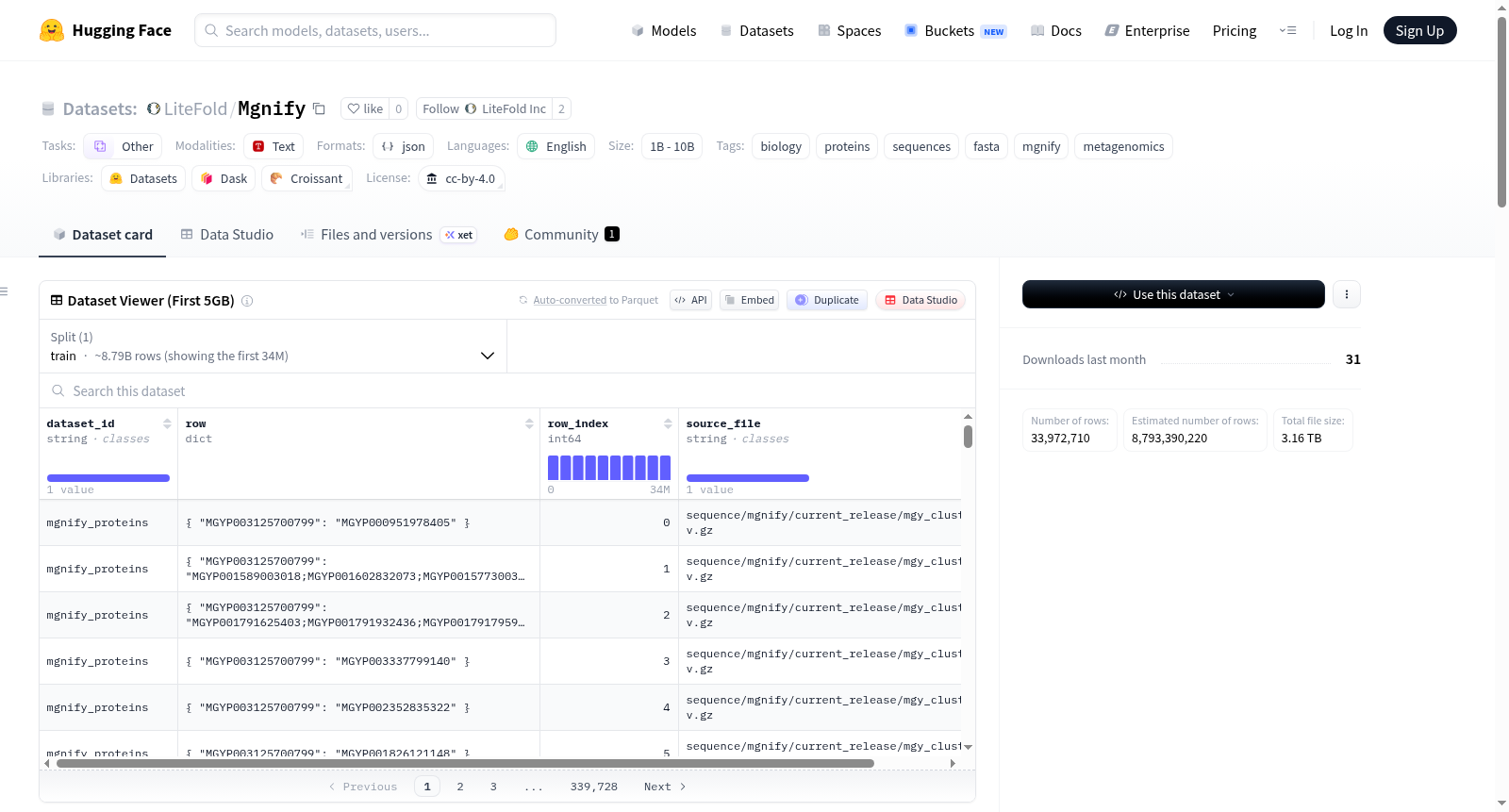
MGnify蛋白质目录数据集是MGnify蛋白质簇目录(包含mgy_clusters和mgy_proteins分区)的标准化FASTA分片集合,源自EMBL-EBI的MGnify微生物组分析资源,经过MegaData后下载流水线处理并标准化。数据集包含两个主要部分:一是sequences/目录下的FASTA格式蛋白质序列分片(使用Zstandard压缩),按源文件组织;二是tables/目录下的JSONL格式标准化元数据表。数据规模包括26个源文件、3,148个分片,压缩分片总大小为319.27 GiB,以及28个标准化表文件,压缩表总大小为2.17 TiB。重要注意事项:每个源目录下的shard-000000.fasta.zst仅为100条记录的验证样本,不包含在正式数据集中;metadata/和manifests/目录未提供,需通过流式处理分片重新生成统计信息。该数据集适用于宏基因组学、蛋白质序列分析、大规模生物信息学流水线等任务,需注意数据使用需遵循CC BY 4.0许可证并引用相关文献。
The MGnify protein catalog dataset is a standardized FASTA sharded collection of the MGnify protein cluster catalog (including the mgy_clusters and mgy_proteins partitions). It is derived from the MGnify microbiome analysis resource at EMBL-EBI, processed and standardized through the MegaData post-download pipeline. The dataset consists of two main components: first, FASTA-formatted protein sequence shards (compressed with Zstandard) in the sequences/ directory, organized by source files; second, standardized metadata tables in JSONL format in the tables/ directory. The data scale includes 26 source files, 3,148 shards with a total compressed size of 319.27 GiB, and 28 standardized table files with a total compressed size of 2.17 TiB. Important notes: The shard-000000.fasta.zst in each source directory is only a validation sample of 100 records and is not included in the official dataset; the metadata/ and manifests/ directories are not provided and need to be regenerated through streaming processing of shards for statistical information. The dataset is suitable for tasks such as metagenomics, protein sequence analysis, and large-scale bioinformatics pipelines, and users must comply with the CC BY 4.0 license and cite relevant literature.
创建时间:
2026-05-10
搜集汇总
数据集介绍
构建方式
MGnify蛋白质目录数据集源自EMBL-EBI的宏基因组学分析资源,经由MegaData后下载流水线处理并标准化FASTA分片文件而构建。原始数据来源于MGnify蛋白质簇目录的mgy_clusters与mgy_proteins分区,包含26个源文件,被划分为3,148个分片,压缩后总容量达319.27 GiB。构建过程中剔除了每个源文件中用于验证的100条记录样本,仅保留从shard-000001.fasta.zst开始的有效分片。标准化表格文件亦同步生成,以JSONL格式存储,共计28个文件,压缩后体积约2.17 TiB,确保数据结构的完整性与下游访问的高效性。
特点
该数据集的核心特点在于其规模宏大且结构高度组织化,涵盖宏蛋白质组学领域的关键序列信息。每个源文件以<source_slug>唯一标识,对应上游原始压缩归档,如sequence_uniprotkb_uniprot_sprot.fasta.gz,便于溯源。分片文件采用Zstandard压缩格式,显著降低存储与传输成本。数据集明确排除了验证样本分片shard-000000.fasta.zst,仅提供完整清洁数据,避免噪声干扰。此外,数据集未附带元数据与清单文件,鼓励用户通过流式处理下游分片自行统计记录与残基数量,赋予研究者在数据分析中的灵活性。
使用方法
用户可通过HuggingFace Hub的snapshot_download函数,结合allow_patterns参数指定’sequences/*/shard-*.fasta.zst’模式,高效下载指定源目录下的所有分片至本地。利用zstandard库的ZstdDecompressor进行流式解压,逐分片读取FASTA记录,可集成自定义解析器处理序列头与序列体。对于快速预览,亦可借助命令行工具zstd结合管道操作,直接解压并查看序列内容。推荐下游计算中基于FASTA记录头部的’>’符号统计每个分片的记录数量,以重构缺失的元数据,从而支持后续的聚类分析、功能注释或比较基因组学研究。
背景与挑战
背景概述
MGnify蛋白质数据集由欧洲生物信息学研究所(EMBL-EBI)于2020年发布,依托MGnify宏基因组分析资源平台构建。该数据集聚焦于微生物组蛋白质序列的聚类与注释,旨在解决宏基因组学中蛋白质功能注释碎片化、数据规模庞大且异构性强的核心研究问题。通过整合来自全球宏基因组项目的海量蛋白质序列,MGnify提供了标准化、可重复使用的序列索引与聚类目录,为微生物生态学、功能基因挖掘及蛋白质进化研究奠定了重要数据基础。作为宏基因组学领域的标杆性资源,MGnify显著推动了微生物暗物质的功能解析与跨学科数据共享。
当前挑战
构建与利用MGnify数据集面临多重挑战。领域层面,宏基因组蛋白质序列高度冗余且大规模聚类需兼顾计算效率与生物学意义,传统工具在面对数千亿残基的数据规模时性能瓶颈显著。构建过程中,原始数据来自26个异构源文件,需统一格式并清洗无效条目(如shard-000000中的验证样本),同时处理319 GiB压缩分片与2.17 TiB的规范化表格之间的格式匹配问题。此外,元数据与清单文件因采样限制无法直接复用,下游用户需重新遍历分片生成记录统计,增加了数据复用与可复现性分析的复杂性。
常用场景
经典使用场景
在微生物组与蛋白质组学的交叉研究领域,Mgnify蛋白目录数据集扮演着基础性资源的角色。该数据集包含了来自MGnify平台的蛋白质簇与蛋白质序列的标准化FASTA分片数据,覆盖了宏基因组学中广泛存在的未培养微生物蛋白序列。其经典使用场景集中于大规模的蛋白质序列同源性搜索、功能注释以及聚类分析,研究者可借助该数据集对复杂环境样本(如土壤、海洋、人体肠道)中的蛋白序列进行系统性比对,揭示微生物群落的代谢潜能与进化关系。此外,该数据集的分布式分片设计便于并行化处理,为构建蛋白质家族数据库与训练深度学习蛋白语言模型提供了高质量的序列源头。
实际应用
在实际应用层面,Mgnify数据集为多个生物技术领域提供了直接支撑。在酶工程与生物勘探中,研究者可通过挖掘该数据集中特定环境来源的蛋白序列,发现耐高温、耐酸碱或具有特殊催化活性的新型酶类,服务于工业生物催化与合成生物学。在精准医学领域,该数据集助力分析人体微生物组中的耐药基因簇与毒力因子,为抗生素替代疗法与疾病诊断标志物开发提供了序列资源。此外,在农业与环境保护方面,基于该数据集的微生物蛋白功能分析可指导土壤健康评估、生物修复策略设计以及作物益生菌的定向筛选,展现出跨行业应用的广阔潜力。
衍生相关工作
围绕Mgnify数据集已衍生出多项具有深远影响力的经典研究工作。核心的奠基性文献由Mitchell等人于2020年在《Nucleic Acids Research》上发表,全面阐述了MGnify资源在微生物组分析中的架构与数据流程。在此基础上,后续研究利用该数据集的蛋白目录开展了大规模的功能基因预测,例如通过整合MGnify序列与KEGG、Pfam等数据库,构建了覆盖全球生态系统的微生物基因目录与蛋白功能图谱。衍生工作中也不乏深度学习方法的创新应用,如基于该数据集预训练的蛋白质语言模型在零样本功能预测与结构推断任务上展现了卓越性能,进一步推动了计算宏蛋白质组学范式的演进与成熟。
以上内容由遇见数据集搜集并总结生成


