Core-S2RGB-SigLIP
收藏Hugging Face2024-12-10 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/Major-TOM/Core-S2RGB-SigLIP
下载链接
链接失效反馈官方服务:
资源简介:
该数据集包含20,212,974个Sentinel-2 Level 2A (RGB)图像的嵌入,使用SigLIP模型提取。每个样本包含多个字段,如unique_id、embedding、grid_cell等,用于描述图像的详细信息。输入数据是来自MajorTOM Core-S2LA数据集的Sentinel-2 (Level 2A) RGB反射率图像,模型使用SigLIP模型的图像编码器提取嵌入。数据集的生成和使用可以通过提供的Python脚本进行。
创建时间:
2024-11-30
原始信息汇总
Core-S2RGB-SigLIP 🔴🟢🔵
数据集概述
- 模态: Sentinel-2 Level 2A (RGB)
- 嵌入数量: 20,212,974
- 感知类型: 真彩色
- 注释: 视觉-语言全局
- 源数据集: Core-S2L2A
- 源模型: SigLIP-SO400M-384
- 大小: 41.3 GB
内容
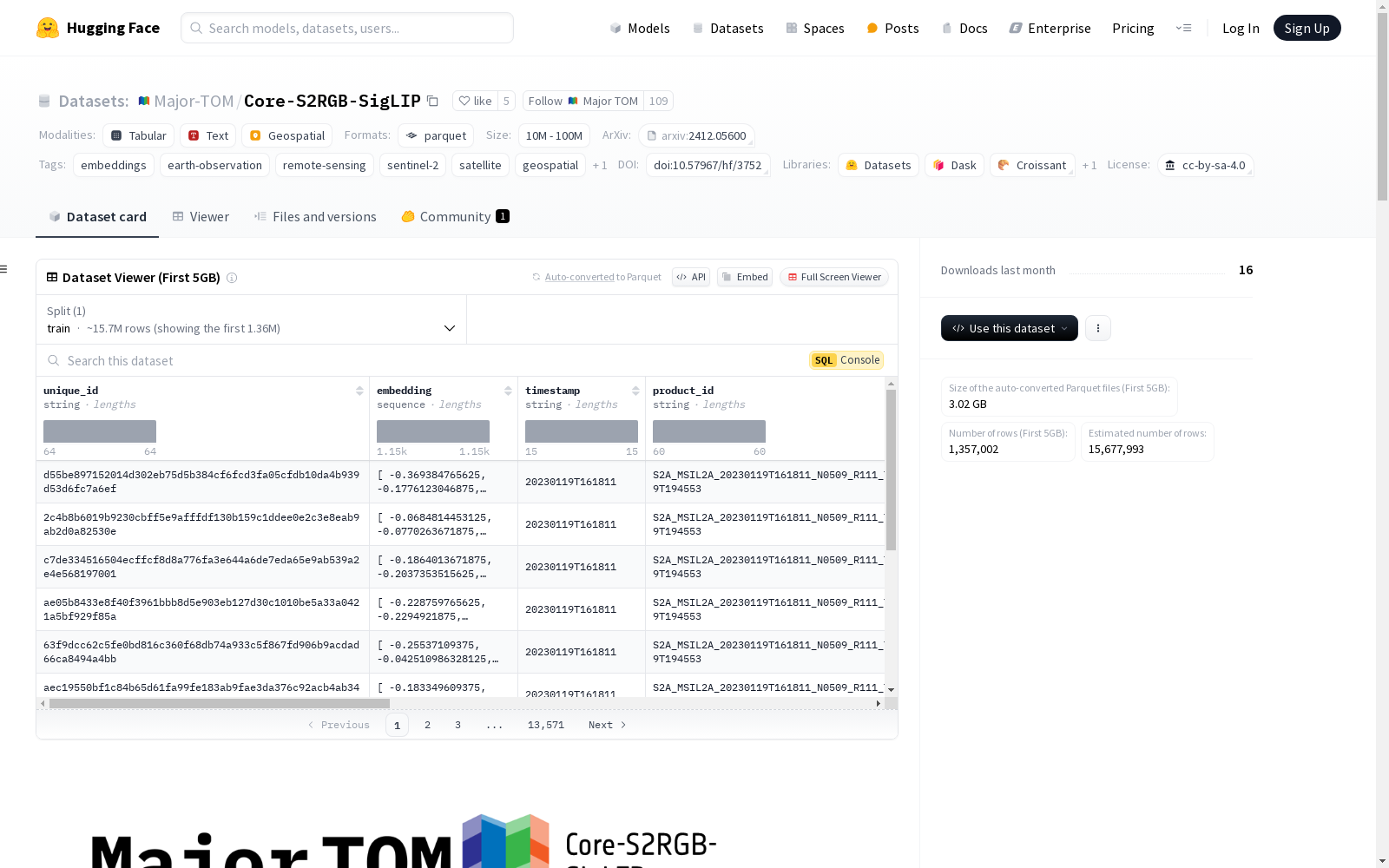
| 字段 | 类型 | 描述 |
|---|---|---|
| unique_id | string | 从几何、时间、product_id和嵌入模型生成的哈希值 |
| embedding | array | 原始嵌入数组 |
| grid_cell | string | Major TOM单元格 |
| grid_row_u | int | Major TOM单元格行 |
| grid_col_r | int | Major TOM单元格列 |
| product_id | string | 原始产品的ID |
| timestamp | string | 样本的时间戳 |
| centre_lat | float | 片段中心的纬度 |
| centre_lon | float | 片段中心的经度 |
| geometry | geometry | 片段的多边形足迹(WGS84) |
| utm_footprint | string | 片段的多边形足迹(图像UTM) |
| utm_crs | string | 原始产品的CRS |
| pixel_bbox | bbox | 片段的边界框(像素) |
输入数据
- 数据来源: Sentinel-2 (Level 2A) RGB反射率乘以2.5并裁剪在0和1之间,以模拟训练数据中的图像
- 样本来源: MajorTOM Core-S2LA
- 图像输入大小: 384 x 384像素,目标重叠: 10%,border_shift: True
模型
- 图像编码器: SigLIP模型的视觉-语言模型用于提取嵌入
示例使用
python from datasets import load_dataset
dataset = load_dataset("Major-TOM/Core-S2RGB-SigLIP")
生成自己的Major TOM嵌入
- 工具包: embedder子包提供了生成嵌入的工具
- 示例笔记本: 05-Generate-Major-TOM-Embeddings.ipynb
项目合作
- 合作方: CloudFerro 和 Φ-lab, European Space Agency (ESA)
- 计算资源: GPU加速实例 在 CREODIAS 云服务平台
作者
- Mikolaj Czerkawski (Φ-lab, European Space Agency)
- Marcin Kluczek (CloudFerro)
- Jędrzej S. Bojanowski (CloudFerro)
开放访问手稿
- 论文: arXiv:2412.05600
搜集汇总
数据集介绍
构建方式
在遥感与地球观测领域,Core-S2RGB-SigLIP数据集通过结合Sentinel-2 Level 2A RGB影像数据与SigLIP模型的图像编码器,构建了大规模的视觉嵌入表示。该数据集的构建基于[Core-S2L2A](https://huggingface.co/datasets/Major-TOM/Core-S2L2A)数据集,利用SigLIP模型提取了20,212,974个嵌入向量。这些嵌入向量是通过对Sentinel-2影像进行预处理,将其反射率乘以2.5并裁剪至[0,1]范围,随后输入到SigLIP模型中生成的。该过程确保了嵌入向量能够与自然语言处理中的文本嵌入相结合,从而实现跨模态分析。
特点
Core-S2RGB-SigLIP数据集的主要特点在于其大规模的嵌入表示和跨模态分析能力。该数据集包含了20,212,974个嵌入向量,每个向量对应一个Sentinel-2影像片段,提供了丰富的地理空间信息。此外,嵌入向量的生成基于SigLIP模型,使其能够与文本嵌入结合,支持视觉-语言的全局分析。数据集还提供了详细的地理信息,如影像片段的中心经纬度、几何形状等,便于进一步的地理空间分析。
使用方法
Core-S2RGB-SigLIP数据集的使用方法简便且灵活。用户可以通过Hugging Face的`datasets`库直接加载数据集,代码示例如下:
python
from datasets import load_dataset
dataset = load_dataset('Major-TOM/Core-S2RGB-SigLIP')
此外,用户还可以利用[Major TOM Embedder](https://github.com/ESA-PhiLab/Major-TOM/tree/main/src/embedder)工具包生成自定义的嵌入向量,并通过提供的Jupyter Notebook示例进行操作。数据集的嵌入向量可用于多种应用场景,如地理空间分析、遥感影像分类和视觉-语言模型训练等。
背景与挑战
背景概述
Core-S2RGB-SigLIP数据集是由欧洲空间局(ESA)的Φ-lab与CloudFerro合作开发的,旨在为地球观测数据提供高效的向量表示。该数据集基于Sentinel-2 Level 2A的RGB影像,通过SigLIP模型提取嵌入向量,生成了20,212,974个嵌入向量,总大小为41.3 GB。这一数据集的创建旨在解决地球观测数据在存储和计算需求上的挑战,通过提供标准化的嵌入向量,使得大规模数据集的浏览和分析变得更加高效。该数据集的发布标志着地球观测领域在AI应用上的重要进展,尤其是在处理大规模地理空间数据方面。
当前挑战
Core-S2RGB-SigLIP数据集在构建过程中面临了多个挑战。首先,如何从Sentinel-2的原始数据中提取有效的嵌入向量,以确保其在视觉语言任务中的适用性,是一个技术难题。其次,处理和存储如此大规模的嵌入向量,对计算资源和存储空间提出了极高的要求。此外,确保数据集的标准化和开放性,以便于全球研究者使用,也是一项重要的挑战。最后,如何在保持数据质量的同时,降低数据处理和分析的复杂性,是该数据集在实际应用中需要解决的关键问题。
常用场景
经典使用场景
Core-S2RGB-SigLIP数据集的经典应用场景主要集中在遥感图像的语义理解和特征提取领域。通过使用SigLIP模型的图像编码器,该数据集能够从Sentinel-2卫星的RGB图像中提取高维嵌入向量,这些向量不仅保留了图像的空间信息,还包含了丰富的语义特征。这种嵌入表示使得研究人员能够在不增加存储和计算负担的情况下,高效地对大规模遥感数据进行分析和检索。
解决学术问题
Core-S2RGB-SigLIP数据集解决了遥感领域中长期存在的数据处理效率低下和语义理解不足的问题。通过提供高维嵌入向量,该数据集为研究人员提供了一种新的方式来处理和分析大规模的地球观测数据,从而推动了遥感图像的语义分割、目标检测和场景分类等研究方向的发展。其意义在于,它为遥感数据的智能化处理提供了标准化的解决方案,并显著提升了数据处理的效率和精度。
衍生相关工作
Core-S2RGB-SigLIP数据集的发布催生了一系列相关的经典工作,特别是在遥感图像的语义理解和特征提取领域。例如,基于该数据集的研究工作提出了多种改进的嵌入提取方法,进一步提升了遥感图像的语义表示能力。此外,该数据集还激发了多个跨领域的研究项目,如结合自然语言处理技术,实现遥感图像与文本描述的联合理解,从而推动了遥感数据在智能决策系统中的应用。
以上内容由遇见数据集搜集并总结生成


