datajuicer/llava-pretrain-refined-by-data-juicer
收藏Hugging Face2024-03-07 更新2024-06-15 收录
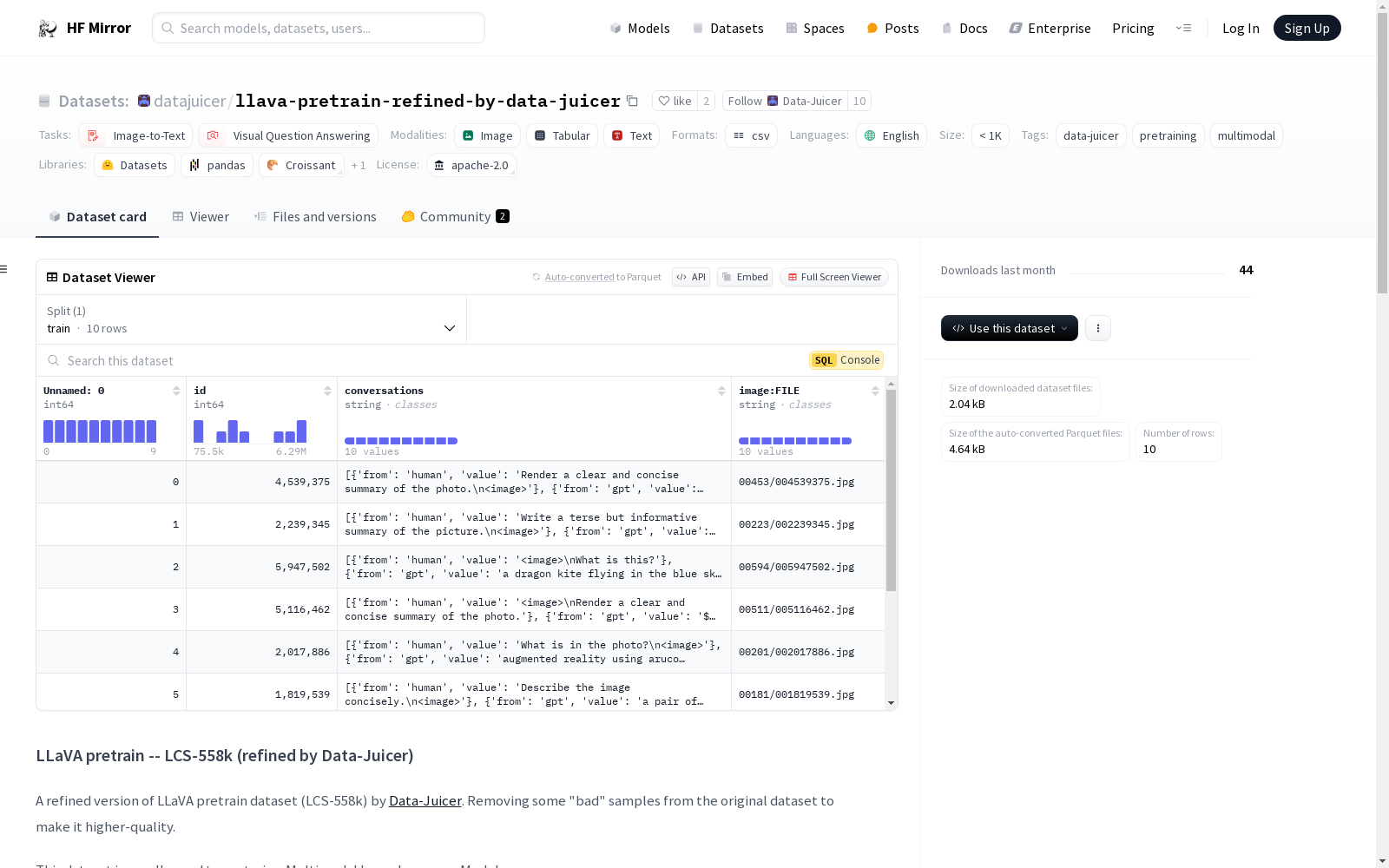
下载链接:
https://hf-mirror.com/datasets/datajuicer/llava-pretrain-refined-by-data-juicer
下载链接
链接失效反馈官方服务:
资源简介:
LLaVA pretrain -- LCS-558k数据集是LLaVA预训练数据集的一个精炼版本,通过Data-Juicer工具去除了原始数据集中的一些低质量样本,以提高数据集的质量。该数据集主要用于多模态大语言模型的预训练。数据集的样本数量为500,380个,保留了原始数据集的约89.65%。精炼过程包括修复Unicode错误、标点符号规范化、过滤不符合特定条件的文本和图像样本等步骤。
LLaVA Pretrain -- The LCS-558k dataset is a refined version of the LLaVA pre-training dataset. Some low-quality samples from the original dataset are removed via the Data-Juicer tool to improve the overall quality of the dataset. This dataset is primarily intended for the pre-training of multimodal large language models. It contains 500,380 samples, retaining approximately 89.65% of the original dataset. The refinement process involves steps including fixing Unicode errors, standardizing punctuation, filtering out text and image samples that do not meet specific criteria, and so on.
提供机构:
datajuicer
原始信息汇总
LLaVA pretrain -- LCS-558k (refined by Data-Juicer)
数据集概述
- 数据集名称: LLaVA pretrain -- LCS-558k (refined by Data-Juicer)
- 数据集版本: 由Data-Juicer精炼的版本,去除了部分“不良”样本,提高了数据质量。
- 数据集用途: 通常用于预训练多模态大型语言模型。
- 数据集大小: 约115MB,包含500,380个样本,保留了原始数据集的约89.65%。
数据集信息
- 样本数量: 500,380
- 保留比例: 约89.65%(从原始数据集中保留)
精炼配方
- 项目名称: llava-1.5-pretrain-dataset-refine-recipe
- 数据集路径: blip_laion_cc_sbu_558k_dj_fmt_only_caption.jsonl
- 导出路径: blip_laion_cc_sbu_558k_dj_fmt_only_caption_refined.jsonl
- 子进程数量: 42
- 文本键名: text
- 图像键名: images
- 图像特殊标记: <image>
- 块结束特殊标记: <|__dj__eoc|>
- 开启追踪: true
处理流程
- 修复Unicode错误: fix_unicode_mapper
- 标点符号规范化: punctuation_normalization_mapper
- 字母数字过滤: alphanumeric_filter
- 最小比例: 0.60
- 字符重复过滤: character_repetition_filter
- 重复长度: 10
- 最大比例: 0.09373663
- 标记词过滤: flagged_words_filter
- 语言: en
- 最大比例: 0.0
- 困惑度过滤: perplexity_filter
- 语言: en
- 最大困惑度: 14435.5806
- 特殊字符过滤: special_characters_filter
- 最小比例: 0.16534802
- 最大比例: 0.42023757
- 单词重复过滤: word_repetition_filter
- 语言: en
- 重复长度: 10
- 最大比例: 0.03085751
- 图像宽高比过滤: image_aspect_ratio_filter
- 最小比例: 0.333
- 最大比例: 3.0
- 任意或全部: any
- 图像形状过滤: image_shape_filter
- 最大宽度: 727.8798422276
- 最大高度: 606.2421072264
- 任意或全部: any
- 图像大小过滤: image_size_filter
- 最大大小: 124KB
- 任意或全部: any
- 图像文本相似度过滤: image_text_similarity_filter
- 使用的CLIP模型: openai/clip-vit-base-patch32
- 最小相似度: 0.20315419
- 图像文本匹配过滤: image_text_matching_filter
- 使用的BLIP模型: Salesforce/blip-itm-base-coco
- 最小匹配分数: 0.44930778
搜集汇总
数据集介绍
构建方式
该数据集是基于LLaVA预训练数据集(LCS-558k)的精炼版本,由Data-Juicer团队通过去除原始数据集中的一些‘不良’样本而构建。构建过程中,采用了多种过滤操作,如字符重复过滤、特殊字符过滤、图像宽高比过滤等,以确保数据集的高质量。具体操作包括修复Unicode错误、规范化标点符号、以及根据图像与文本的相似度和匹配度进行过滤。
使用方法
该数据集通常用于多模态大语言模型的预训练。用户可以通过指定的链接获取完整数据集,并根据提供的处理脚本进行数据预处理。数据集的格式已转换为Data-Juicer格式,便于直接应用于相关模型训练。使用时,建议结合具体的模型需求,调整和优化数据处理流程。
背景与挑战
背景概述
在多模态大语言模型(Multimodal Large Language Model, MLLM)的预训练过程中,高质量的数据集是确保模型性能的关键。LLaVA pretrain -- LCS-558k(由Data-Juicer精炼)数据集,由阿里巴巴的Data-Juicer团队于近期创建,旨在提供一个经过精细筛选的高质量数据集,以支持多模态大语言模型的预训练。该数据集的核心研究问题是如何通过去除原始数据集中的‘不良’样本,提升数据集的整体质量,从而优化模型的训练效果。这一研究对多模态学习领域具有重要影响,因为它直接关系到模型在视觉问答和图像到文本任务中的表现。
当前挑战
构建LLaVA pretrain -- LCS-558k数据集面临的主要挑战包括:首先,如何在庞大的原始数据集中准确识别并去除‘不良’样本,这需要高效的过滤算法和严格的筛选标准。其次,确保在去除‘不良’样本的同时,不丢失数据集的多样性和代表性,这是一个平衡质量与多样性的难题。此外,数据集的构建过程中还需考虑图像与文本之间的匹配度和相似度,这要求开发复杂的图像文本相似性过滤器和匹配算法。这些挑战共同构成了该数据集在多模态学习领域中的重要研究课题。
常用场景
经典使用场景
在多模态大语言模型的预训练过程中,datajuicer/llava-pretrain-refined-by-data-juicer数据集扮演着至关重要的角色。该数据集通过精炼原始LLaVA预训练数据集,剔除了质量较低的样本,从而显著提升了数据集的整体质量。这种高质量的数据集为模型提供了更为纯净和丰富的视觉与文本信息,使得模型在图像描述生成和视觉问答任务中表现更为出色。
解决学术问题
该数据集通过精细化的数据处理流程,解决了多模态数据预训练中常见的数据噪声问题。具体而言,它通过一系列过滤操作,如字符重复过滤、特殊字符过滤和图像文本相似度过滤等,有效去除了低质量样本,提升了数据集的纯净度。这不仅有助于提高模型的训练效率,还为多模态模型的性能提升提供了坚实的基础。
实际应用
在实际应用中,datajuicer/llava-pretrain-refined-by-data-juicer数据集被广泛应用于多模态大语言模型的预训练阶段。例如,在智能客服系统中,该数据集可以用于训练模型理解用户上传的图片并生成相应的文本回复;在教育领域,它可以用于开发能够自动生成教材插图描述的智能工具。这些应用场景均得益于数据集的高质量和多模态特性。
数据集最近研究
最新研究方向
在多模态大语言模型(MLLM)领域,datajuicer/llava-pretrain-refined-by-data-juicer数据集的最新研究方向主要集中在提升预训练数据的质量和多样性。通过精细化的数据处理流程,如字符重复过滤、特殊字符比率控制、以及图像与文本的相似度匹配,该数据集旨在为模型提供更为纯净和高质量的训练样本。这一研究方向不仅有助于提升模型的泛化能力和性能,还为多模态任务如视觉问答和图像到文本生成提供了更为可靠的数据基础。
以上内容由遇见数据集搜集并总结生成


