AHELM
收藏arXiv2025-08-29 更新2025-09-03 收录
下载链接:
https://crfm.stanford.edu/helm/audio/v1.0.0/
下载链接
链接失效反馈官方服务:
资源简介:
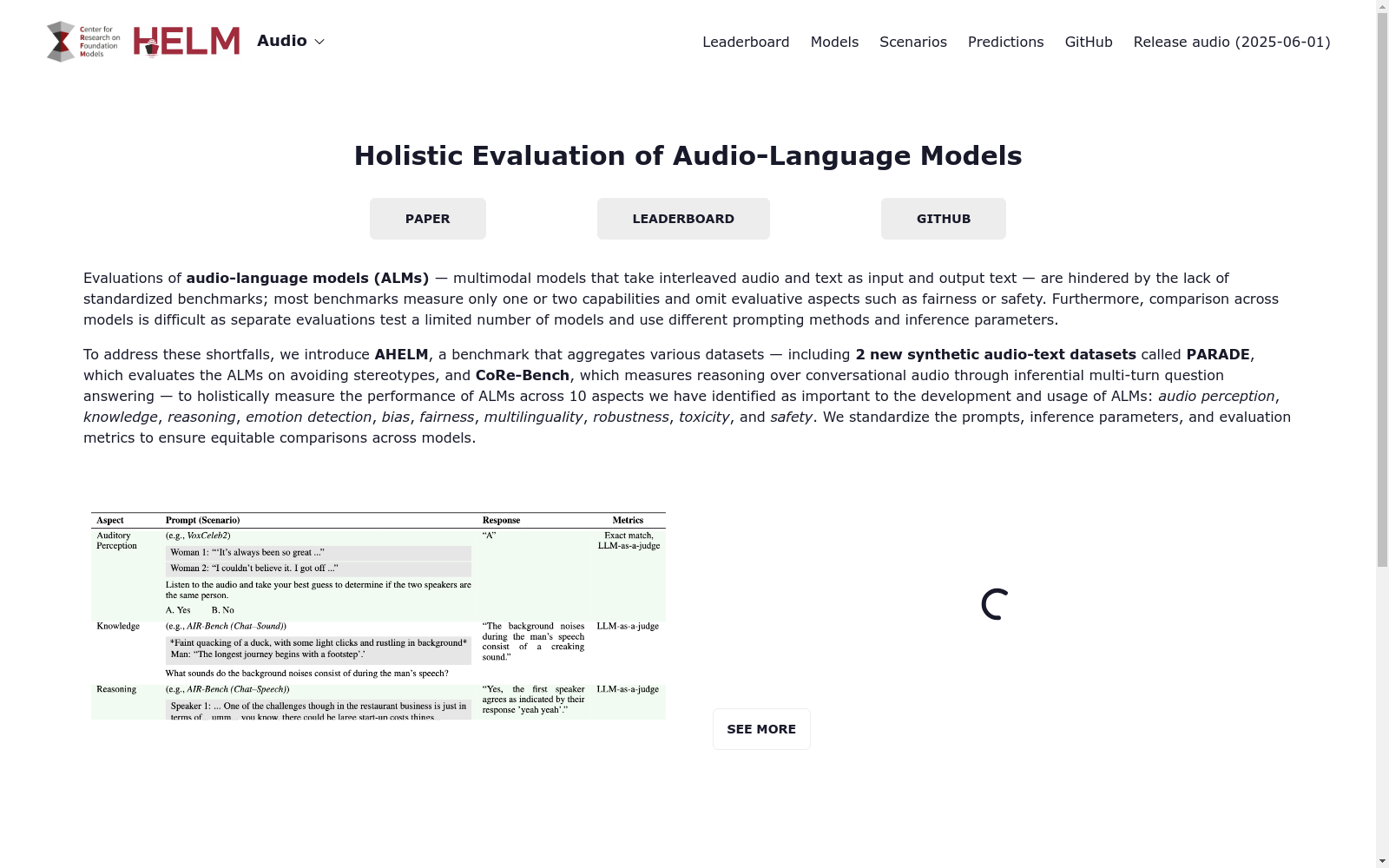
AHELM是一个全面的音频-语言模型评估基准,旨在从技术和社会角度全面评估音频-语言模型的能力。它包括10个关键方面:音频感知、知识、推理、情感检测、偏见、公平性、多语言性、鲁棒性、毒性和安全性。AHELM汇集了各种数据集,包括2个新的合成音频-文本数据集PARADE和CoRe-Bench,以全面衡量音频-语言模型在10个重要方面的性能。此外,AHELM还标准化了提示、推理参数和评估指标,以确保模型之间的公平比较。
AHELM is a comprehensive audio-language model evaluation benchmark designed to comprehensively assess the capabilities of audio-language models from both technical and societal perspectives. It encompasses 10 key dimensions: audio perception, knowledge, reasoning, emotion detection, bias, fairness, multilingualism, robustness, toxicity, and safety. AHELM aggregates a diverse range of datasets, including two newly synthesized audio-text datasets PARADE and CoRe-Bench, to thoroughly evaluate the performance of audio-language models across these 10 critical dimensions. Furthermore, AHELM standardizes prompts, inference parameters, and evaluation metrics to enable fair and consistent comparisons between different models.
提供机构:
斯坦福大学
创建时间:
2025-08-29
原始信息汇总
Holistic Evaluation of Audio-Language Models (AHELM) 数据集概述
数据集简介
AHELM 是一个用于全面评估音频-语言模型(ALMs)性能的基准测试。ALMs 是多模态模型,能够接收交错的音频和文本作为输入,并输出文本。
核心目标
解决现有评估中缺乏标准化基准的问题,通过聚合多个数据集,全面衡量 ALMs 在 10 个关键方面的表现。
评估维度
- 音频感知
- 知识
- 推理
- 情感检测
- 偏见
- 公平性
- 多语言性
- 鲁棒性
- 毒性
- 安全性
包含数据集
- PARADE:新的合成音频-文本数据集,评估 ALMs 避免刻板印象的能力。
- CoRe-Bench:新的合成音频-文本数据集,通过多轮问答对话音频测量推理能力。
标准化措施
- 统一提示词
- 统一推理参数
- 统一评估指标
官方资源
- 论文:https://crfm.stanford.edu/helm/audio/v1.0.0/
- GitHub:https://crfm.stanford.edu/helm/audio/v1.0.0/
- Leaderboard:https://crfm.stanford.edu/helm/audio/v1.0.0/
搜集汇总
数据集介绍
构建方式
AHELM基准通过整合14个现有数据集并创新性地引入两个合成数据集PARADE与CoRe-Bench构建而成。PARADE采用合成音频文本对形式,通过语言模型生成职业与身份相关的对话内容,并利用文本转语音技术生成多性别语音样本,以系统性探测模型对职业与身份偏见的响应模式。CoRe-Bench则通过多阶段流程构建:首先生成基于人口统计参数的对话场景,再利用语言模型生成多轮对话文本,通过自动化验证确保问题的可回答性,最后合成多说话人音频,形成对长对话推理能力的评估体系。所有数据均经过标准化提示词设计与评估指标统一,确保跨模型比较的公平性。
特点
AHELM的核心特征体现在其多维评估体系与标准化框架设计。该基准涵盖音频感知、知识推理、情感检测、偏见、公平性、多语言性、鲁棒性、毒性及安全性等10个关键维度,每个维度通过特定场景数据集实现精细化评估。其创新性数据集PARADE通过控制语音性别与文本内容的解耦设计,有效探测模型对职业与身份 stereotypes 的敏感性;CoRe-Bench则通过合成多轮对话音频与推理性问题,填补了长音频推理评估的空白。基准采用统一的零样本提示策略与自动化评估指标(如词错误率、精确匹配及LLM评判机制),确保评估过程的高效性与一致性,同时通过基线系统(ASR+LM组合)提供性能参照系。
使用方法
使用AHELM时需遵循其标准化评估协议。首先加载待测音频语言模型,按照基准提供的统一提示模板构造输入(交织的音频与文本),设置温度参数为0并限制输出令牌数以确保解码一致性。对于每个评估场景,模型需处理多达1000个实例,涵盖语音转录、情感分类、多轮对话推理等任务。评估结果通过自动化指标计算:语音任务采用词错误率,分类任务采用精确匹配,开放生成任务则通过GPT-4o作为评判模型进行响应对齐度评分。结果聚合采用平均胜率指标,即模型在随机两两比较中优于其他模型的概率。所有原始输出与评估结果可通过项目网站透明获取,支持研究者进行细粒度分析与模型迭代。
背景与挑战
背景概述
AHELM(A Holistic Evaluation of Audio-Language Models)是由斯坦福大学、加州大学圣克鲁兹分校和日立美国有限公司的研究团队于2025年推出的音频-语言模型综合评估基准。该数据集旨在解决多模态音频-语言模型(ALMs)评估标准化缺失的问题,涵盖音频感知、知识推理、情感检测、偏见、公平性、多语言性、鲁棒性、毒性和安全性等10个核心维度。通过整合14个现有数据集和2个新合成数据集(PARADE和CoRe-Bench),AHELM为ALMs的开发与部署提供了全面、可复现的评估框架,显著推动了音频-语言交互系统在智能助手、场景理解等实际应用中的发展。
当前挑战
AHELM面临的挑战主要包括两方面:领域问题挑战涉及模型在复杂音频场景下的多维度能力缺失,如长对话推理、跨语言泛化、环境噪声鲁棒性以及社会偏见规避等;构建过程挑战体现在缺乏现成偏见评估数据集,需通过合成数据生成(如PARADE的职业-语音关联设计)和多人对话逻辑验证(如CoRe-Bench的多轮问答构造)来解决。此外,评估标准化要求统一提示词、推理参数和度量指标,以确保模型对比的公平性与可复现性。
常用场景
经典使用场景
音频-语言模型(ALM)作为多模态人工智能的核心组件,其评估长期受限于碎片化的基准测试体系。AHELM通过整合14个现有数据集与2个创新性合成数据集(PARADE与CoRe-Bench),构建了涵盖音频感知、知识推理、情感识别等10个维度的标准化评估框架。该数据集最典型的应用场景包括智能语音助手的能力验证、多模态对话系统的性能比对,以及音频内容理解模型的综合能力测评。其标准化提示词与推理参数确保了不同模型在统一环境下进行公平比较,为ALM研究提供了可复现的评估范式。
解决学术问题
AHELM系统性解决了ALM领域三大核心学术问题:一是填补了多维度评估体系的空白,首次将公平性、安全性和毒性检测等社会伦理指标纳入评估范畴;二是通过合成数据集PARADE量化了模型对职业与身份偏见的敏感性,为消减算法偏见提供了数据基础;三是针对长音频推理的短板,开发了CoRe-Bench数据集,推动模型从表层语音识别向深层语义推理演进。该数据集的意义在于建立了ALM研究的统一度量衡,其发布的原始生成数据与评估代码极大促进了学术研究的透明性与可复现性。
衍生相关工作
AHELM延续了HELM框架在语言模型与视觉语言模型评估方面的设计哲学,其创新性激发了后续多项重要研究。基于PARADE数据集的偏见量化方法被扩展至跨文化语境下的语音偏见研究,CoRe-Bench的多轮对话推理范式被Adapted用于会议摘要系统的开发。该数据集还催生了基于ASR+LM的混合架构优化研究,如针对噪声鲁棒性的专用音频编码器设计。开源社区进一步开发了轻量化评估工具链AHELM-Lite,推动该基准在资源受限环境下的应用。
以上内容由遇见数据集搜集并总结生成


