p9r3k6b1-zx7v4n2_tran
收藏Hugging Face2025-11-24 更新2025-11-25 收录
下载链接:
https://huggingface.co/datasets/eb-b/p9r3k6b1-zx7v4n2_tran
下载链接
链接失效反馈官方服务:
资源简介:
这个数据集包含了组织在文件夹中的转录音频文件,以便于扩展。数据集共有1043个音频文件,分布在5个文件夹内,每个文件夹最多可容纳5000个文件。数据集的结构包括音频文件和元数据文件,元数据文件以parquet格式存储。
创建时间:
2025-11-17
原始信息汇总
数据集概述
基本信息
- 数据集名称: eb-b/p9r3k6b1-zx7v4n2_tran
- 许可证: MIT
- 任务类别: 自动语音识别
- 支持语言: 阿姆哈拉语 (am)、多语言 (multilingual)
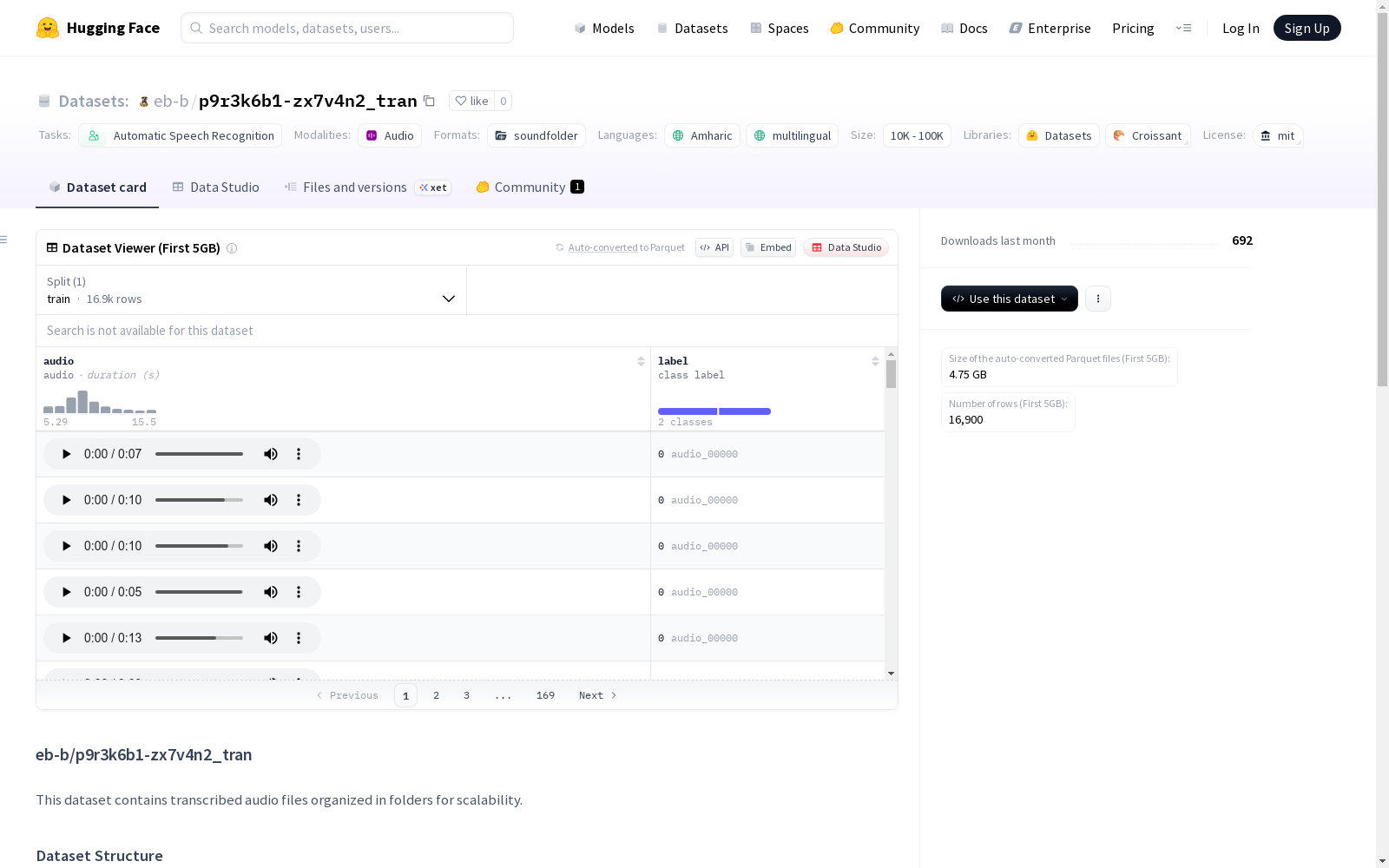
数据集结构
- 音频文件: 存储在
audio_XXXXX/文件夹中(每个文件夹最多5000个文件) - 元数据: 存储在
data_XXXXX/文件夹中,格式为parquet文件
统计信息
- 文件总数: 1,043
- 批次总数: 4,190
- 音频文件夹数量: 5
- 每个文件夹文件数: 最多5000
数据加载方式
python from datasets import load_dataset dataset = load_dataset("eb-b/p9r3k6b1-zx7v4n2_tran")
文件夹组织规范
- 音频文件分布:
audio_00000/: 文件0-4,999audio_00001/: 文件5,000-9,999
- 元数据文件命名:
data_00000/batches_0000000001_to_0000000020.parquet
搜集汇总
数据集介绍
构建方式
在自动语音识别研究领域,数据的高效组织对模型训练至关重要。该数据集采用分层存储架构,将音频文件按每5000个为一组分配至独立的audio_XXXXX目录中,同时将对应的元数据以Parquet格式封装于data_XXXXX文件夹内。这种设计遵循大规模数据集管理的最佳实践,通过分布式存储结构有效规避了文件系统的性能瓶颈,为多语言语音数据处理提供了可扩展的底层支持。
特点
作为涵盖阿姆哈拉语及多语种资源的语音数据集,其核心价值体现在精心设计的资源分布模式。数据集共包含1043个基础单元,划分为4190个批处理单元,所有音频材料均通过标准化命名规则实现快速索引。每个存储目录严格限制不超过5000个文件,既保障了数据调取效率,又保持了与现代分布式计算框架的兼容性,为跨语言语音识别研究提供了结构化的数据基础。
使用方法
基于Hugging Face生态系统的技术规范,研究者可通过load_dataset接口直接载入完整数据集。代码执行时会自动解析audio字段内嵌的路径标识符,将分散存储的音频片段动态重构为连续数据流。这种封装机制使使用者无需关注底层文件分布细节,仅需通过标准API即可调用全部1043个数据实例,极大简化了多模态语音数据的实验流程。
背景与挑战
背景概述
在自动语音识别技术快速发展的背景下,多语言语音数据资源成为推动跨语言通信系统进步的关键要素。p9r3k6b1-zx7v4n2_tran数据集由eb-b研究团队构建,专注于整合阿姆哈拉语等语言的转录音频,旨在解决低资源语言在语音识别模型训练中的代表性不足问题。该数据集采用模块化存储结构,通过分布式文件夹管理海量音频文件与元数据,遵循现代数据工程的最佳实践,为语音技术在多语言环境中的适应性研究提供了标准化基础。
当前挑战
构建p9r3k6b1-zx7v4n2_tran数据集面临双重挑战:在领域问题层面,低资源语言的语音变异性和标注一致性难以保障,需克服方言差异与噪声干扰对识别精度的影响;在技术实施层面,超百万级文件的分布式存储要求精密设计目录架构,同时确保元数据与音频流的高效映射,避免因数据规模引发的加载延迟或系统瓶颈。
常用场景
经典使用场景
在语音技术领域,该数据集通过组织大规模转录音频文件,为自动语音识别系统提供了标准化训练资源。其结构化的存储方式支持高效数据加载,便于模型在多样化语言环境下进行端到端学习,尤其适用于处理阿姆哈拉语等多语言场景下的语音转文本任务。
衍生相关工作
基于该数据集的经典衍生工作包括端到端语音识别架构的优化研究,以及跨语言迁移学习模型的创新。这些工作不仅拓展了多模态预训练技术的边界,还催生了面向低资源语言的专用工具包,持续推动着语音技术生态的演进。
数据集最近研究
最新研究方向
在自动语音识别领域,多语言模型的研究正日益受到关注,特别是针对资源稀缺语言如阿姆哈拉语的开发。该数据集通过结构化存储海量音频与元数据,为低资源语言识别技术提供了重要支持。前沿研究聚焦于跨语言迁移学习与端到端模型优化,利用此类数据集提升模型在复杂语音环境中的泛化能力。随着全球化交流需求增长,多语言语音处理技术已成为行业热点,推动着智能助手与无障碍通信等应用的创新发展。
以上内容由遇见数据集搜集并总结生成


