有没有相关的论文或文献参考?
这个数据集是基于什么背景创建的?
数据集的作者是谁?
能帮我联系到这个数据集的作者吗?
这个数据集如何下载?
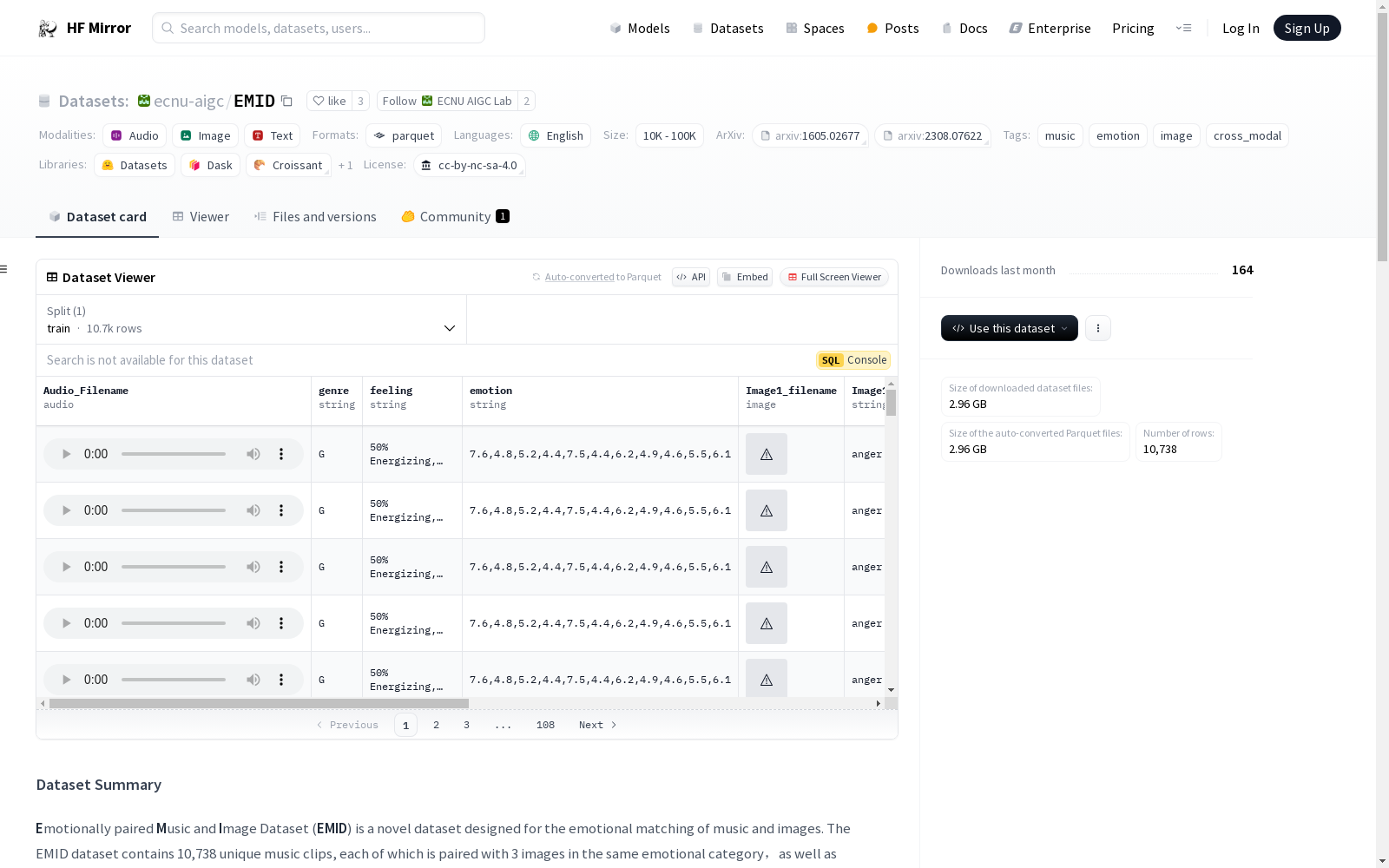
Emotionally paired Music and Image Dataset (EMID) 是一个新颖的数据集,旨在用于音乐和图像的情感匹配。EMID 数据集包含 10,738 个独特的音乐片段,每个片段都与同一情感类别的 3 张图像配对,并附有丰富的注释。这些音乐片段被分为 13 个情感类别,这些类别源自 What music makes us feel: At least 13 dimensions organize subjective experiences associated with music across different cultures 的研究,从中我们获得了 1,836 个原始音乐片段。随后,我们从 Building a Large Scale Dataset for Image Emotion Recognition: The Fine Print and The Benchmark 中获取了标记为 Mikels 的八种情感的图像。通过我们论文中提出的处理流程,我们扩展了原始音乐片段,并获得了最终的数据集。
| 情感类别 | 扩展前 | 扩展后 |
|---|---|---|
| A | 45 | 255 |
| B | 80 | 545 |
| C | 54 | 320 |
| D | 131 | 771 |
| E | 306 | 1531 |
| F | 174 | 889 |
| G | 367 | 1832 |
| H | 86 | 1036 |
| I | 36 | 323 |
| J | 124 | 1014 |
| K | 129 | 799 |
| L | 105 | 484 |
| M | 199 | 939 |
| 总计 | 1836 | 10738 |
| 字段名称 | 解释 | 示例 |
|---|---|---|
| Audio_Filename | 音乐片段的唯一文件名 | 106.m4a___172.mp3 |
| genre | 代表 13 个情感类别之一的字母 A 到 M | K |
| feeling | 参与者在听完这段音乐后的感受及其比例 | "33% Sad, depressing, 22% Awe-inspiring, amazing, 22% Proud, strong, 22% Triumphant, heroic, 19% Dreamy, 15% Beautiful, 15% Bittersweet, 11% Calm, relaxing, serene, 11% Compassionate, sympathetic, 11% Entrancing, 11% Transcendent, mystical, 7% Eerie, mysterious, 7% Painful, 7% Tender, longing, 4% Energizing, pump-up, 4% Indignant, defiant" |
| emotion | 音乐引发的 11 个情感维度的主观体验评分,范围从 1 到 9 | "5,5.3,5,6,3.1,6.1,5.1,3.6,6.2,5.9,5.6" |
| Image1_filename | 图像 1 的文件名 | excitement_0616.jpg |
| Image1_tag | 图像 1 的情感类别 | excitement |
| Image1_text | 由 GIT 模型生成的图像 1 的文本描述 | [the marching band in the parade] |
| Image2_filename | 图像 2 的文件名 | amusement_2906.jpg |
| Image2_tag | 图像 2 的情感类别 | amusement |
| Image2_text | 由 GIT 模型生成的图像 2 的文本描述 | [the marching band at disneyland] |
| Image3_filename | 图像 3 的文件名 | amusement_2226.jpg |
| Image3_tag | 图像 3 的情感类别 | amusement |
| Image3_text | 由 GIT 模型生成的图像 3 的文本描述 | [a marching band in a parade with people watching.] |
| is_original_clip | 如果该值为真,则音乐片段来自原始音乐数据集,否则它是通过我们的处理流程从原始音乐片段扩展而来的。原始音乐片段被认为能提供更好的情感匹配性能 | False |
中国气象数据
本数据集包含了中国2023年1月至11月的气象数据,包括日照时间、降雨量、温度、风速等关键数据。通过这些数据,可以深入了解气象现象对不同地区的影响,并通过可视化工具揭示中国的气温分布、降水情况、风速趋势等。
github 收录
RAVDESS
情感语音和歌曲 (RAVDESS) 的Ryerson视听数据库包含7,356个文件 (总大小: 24.8 GB)。该数据库包含24位专业演员 (12位女性,12位男性),以中性的北美口音发声两个词汇匹配的陈述。言语包括平静、快乐、悲伤、愤怒、恐惧、惊讶和厌恶的表情,歌曲则包含平静、快乐、悲伤、愤怒和恐惧的情绪。每个表达都是在两个情绪强度水平 (正常,强烈) 下产生的,另外还有一个中性表达。所有条件都有三种模态格式: 纯音频 (16位,48kHz .wav),音频-视频 (720p H.264,AAC 48kHz,.mp4) 和仅视频 (无声音)。注意,Actor_18没有歌曲文件。
OpenDataLab 收录
HUSTgearbox
This reposotory release a gearbox failure dataset, which can support intelliegnt fault diagnosis research
github 收录
糖尿病预测数据集
糖尿病相关的医学研究或者健康数据
AI_Studio 收录
Breast Ultrasound Images (BUSI)
小型(约500×500像素)超声图像,适用于良性和恶性病变的分类和分割任务。
github 收录