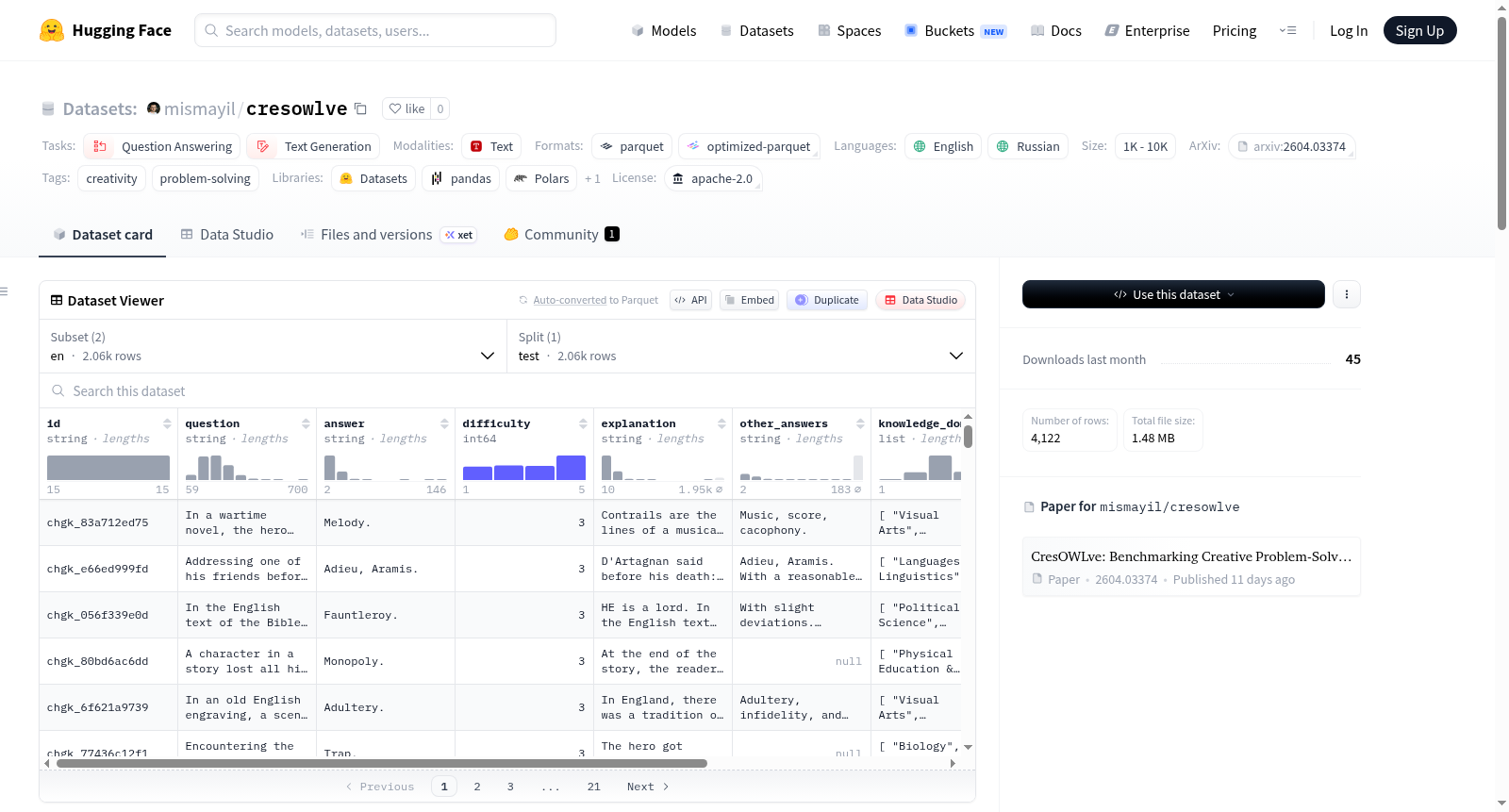
cresowlve
收藏CresOWLve 数据集概述
数据集基本信息
- 数据集名称: CresOWLve: Benchmarking Creative Problem-Solving Over Real-World Knowledge
- 发布地址: https://huggingface.co/datasets/mismayil/cresowlve
- 许可证: Apache-2.0
- 任务类别: 问答、文本生成
- 语言: 英语、俄语
- 标签: 创造力、问题解决
- 规模类别: 1K<n<10K
数据集描述
这是一个基于现实世界知识、可由人类专家解决的双语创造性问题解决基准。CresOWLve 涵盖广泛的知识和创意领域,难度各异,需要多种创造性思维策略,并经过人工验证以确保质量。它包含约2000个开放式问题及其答案和解释。
数据集结构与内容
数据集包含两个配置:en(英语)和ru(俄语)。每个配置仅包含一个test(测试)分割。
数据字段
每个样本包含以下字段:
id: 唯一样本ID。question: 文本形式的开放式问题。answer: 问题的原始答案文本。difficulty: 问题的难度等级(1-5)。explanation: 参考答案的解释(如果可用)。other_answers: 其他可接受的答案(如果有)。knowledge_domains: 回答问题所涉及的知识领域(学科、主题)列表。creative_domains: 回答问题所涉及的创意领域/思维策略列表。cultures: 回答问题所涉及的文化/人口统计列表。
数据规模
- 英语 (
en) 配置:- 下载大小: 619,691 字节
- 数据集大小: 1,156,563 字节
- 样本数量: 2,061 个
- 俄语 (
ru) 配置:- 下载大小: 852,319 字节
- 数据集大小: 1,759,010 字节
- 样本数量: 2,061 个
知识领域
基准问题涉及至少以下一个领域的知识: 文学、历史、电影与媒体研究、语言与语言学、人文地理、宗教研究、人类学、体育教育、生物学、工程与技术、视觉艺术、音乐、政治学、家政与日常生活、表演艺术、心理学、社会学、地球与环境科学、军事、物理学、天文学与空间科学、商学、哲学、设计与建筑、医学与健康科学、经济学、数学、化学、法律与犯罪学、其他科学、艺术史与视觉文化、教育、传播学、考古学。
创意语言与思维
基准问题涉及多个创意语言领域和技能: 横向思维、类比、抽象、笑话、双关语、隐喻、常识推理、诗歌、习语、新词、讽刺、谚语、发散性思维、组合性、明喻。
文化与人口统计
基准问题需要了解来自不同文化的实体和人物知识: 英语、俄语、法语、德语、意大利语、希腊语、拉丁语、美国、西班牙语、日语、波兰语、阿拉伯语、荷兰语、瑞典语、中文、希伯来语、乌克兰语、罗马、印度、挪威语、丹麦语、苏格兰语、葡萄牙语、土耳其语、捷克语、瑞士语、埃及语、格鲁吉亚语、爱尔兰语、波斯语、巴西语、欧洲、亚美尼亚语等。
数据来源
基准问题来源于著名的俄罗斯智力游戏“What?Where?When?”(https://en.wikipedia.org/wiki/What%3F_Where%3F_When%3F)。为确保可访问性和相关性,设计了一个多阶段的基准构建流程,以过滤不合适和非创造性的问题,并将剩余的谜题翻译成英语并进行人工验证。最终的数据集为评估基于现实世界知识的创造性问题解决提供了一个多样化且高质量的基准。
相关资源
- 代码仓库: https://github.com/mismayil/cresowlve
- 论文: https://arxiv.org/abs/2604.03374
引用信息
@misc{ismayilzada2026cresowlve, title={CresOWLve: Benchmarking Creative Problem-Solving Over Real-World Knowledge}, author={Mete Ismayilzada and Renqing Cuomao and Daniil Yurshevich and Anna Sotnikova and Lonneke van der Plas and Antoine Bosselut}, year={2026}, eprint={2604.03374}, archivePrefix={arXiv}, primaryClass={cs.CL}, url={https://arxiv.org/abs/2604.03374}, }