SVG
收藏Hugging Face2025-03-25 更新2025-03-26 收录
下载链接:
https://huggingface.co/datasets/Mortdecai/SVG
下载链接
链接失效反馈官方服务:
资源简介:
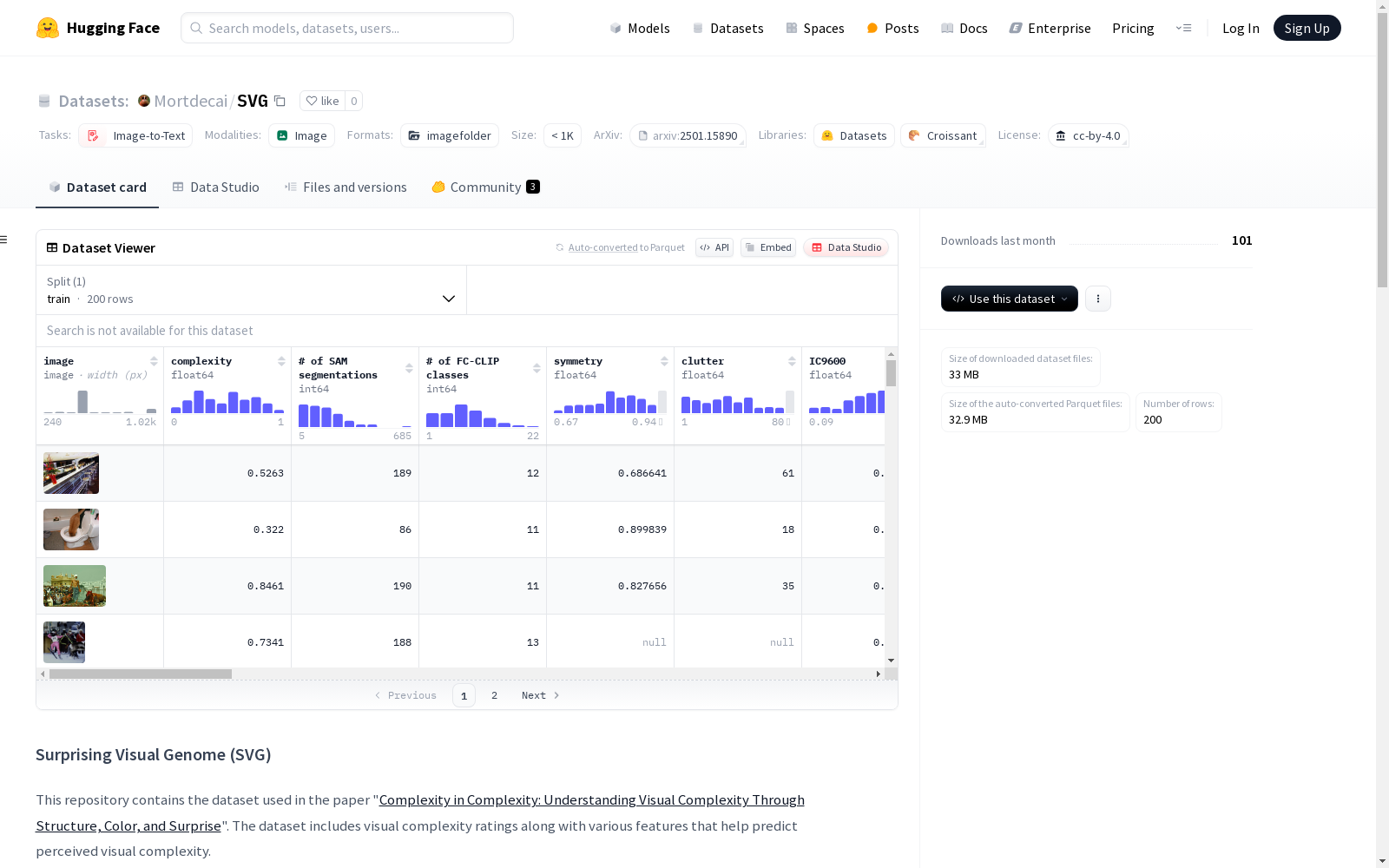
Surprising Visual Genome (SVG)数据集包含视觉复杂性评分和各种有助于预测感知视觉复杂性的特征。这些特征包括图像的唯一标识符、人类评定的视觉复杂性分数、不同模型识别的段落数和语义类别数、对称性、视觉杂乱度、预测复杂性、边缘密度、多尺度独特颜色分数、惊喜分数等。
创建时间:
2025-03-21
搜集汇总
数据集介绍
构建方式
SVG数据集通过多维度特征融合构建而成,其核心数据来源于视觉基因组中的人类标注复杂性评分。研究团队采用SAM模型进行图像分割,结合FC-CLIP模型提取语义类别,并整合了包括对称性、杂乱度在内的多种视觉特征指标。特别值得注意的是,数据集引入了基于Gemini-1.5-flash LLM生成的惊喜度评分,以及AMNet预测的记忆性分数,构建过程体现了计算视觉与认知科学的交叉融合。
特点
该数据集最显著的特点是建立了视觉复杂性与多种量化指标之间的关联体系。除了包含传统的边缘密度、色彩多样性等视觉特征外,还创新性地引入了多尺度索贝尔梯度评分和惊喜度评估。数据集涵盖了从低层次的图像结构特征到高层次的语义特征,以及人类认知层面的评分,为研究视觉复杂性提供了多维度的分析视角。
使用方法
SVG数据集适用于视觉复杂性预测模型的开发与验证。研究人员可通过分析图像特征与人类评分之间的关系,探索视觉复杂性的形成机制。具体应用时,可基于提供的特征矩阵进行回归分析或机器学习建模,也可将惊喜度评分作为独立变量研究其对复杂性的影响。数据集中的多尺度特征特别适合用于研究视觉信息处理的分层机制。
背景与挑战
背景概述
SVG(Surprising Visual Genome)数据集由Karahan Sarıtaş、Peter Dayan等研究人员于2025年提出,旨在通过结构、色彩和惊奇度等多维度特征解析视觉复杂性的内在机制。该数据集基于视觉基因组(Visual Genome)框架构建,整合了人类评分与计算模型生成的特征,包括SAM分割数量、FC-CLIP语义类别、多尺度索贝尔梯度等21类指标。其核心研究聚焦于视觉认知领域长期存在的关键问题——人类如何感知和理解图像的复杂性,相关成果发表于跨学科期刊《Complexity in Complexity》,为计算机视觉、心理学和神经科学的交叉研究提供了定量分析基准。
当前挑战
SVG数据集面临的挑战主要体现在两个维度:在领域问题层面,视觉复杂性评估存在主观性强、跨文化差异显著等固有难题,现有特征工程难以完全捕捉人类认知的非线性判断过程;在构建过程中,多模态特征融合面临技术瓶颈,如SAM分割的粒度控制、FC-CLIP的语义覆盖完整性,以及大语言模型生成的惊奇度分数与人类评分的对齐问题。此外,传统边缘密度测量与新型多尺度特征之间的相关性建模,仍需突破维度诅咒带来的计算复杂度挑战。
常用场景
经典使用场景
在视觉认知与计算美学领域,SVG数据集为研究者提供了量化视觉复杂度的标准化工具。其多尺度特征提取架构(如MSG梯度、MUC色彩多样性指标)能够精确捕捉图像在结构对称性、色彩分布等方面的非线性特征,特别适用于分析自然场景与人造环境中视觉元素的层级化组织规律。通过整合人类评分与机器生成的特征向量,该数据集已成为验证视觉复杂度认知模型的金标准。
解决学术问题
SVG数据集系统性地解决了视觉复杂度研究中特征表征碎片化的问题。传统研究往往孤立考察边缘密度或色彩对比度等单一特征,而该数据集通过融合SAM分割的语义层级、FC-CLIP的语义类别以及多尺度对称性指标,首次建立了跨模态的复杂度预测框架。其包含的人类惊讶度评分更揭示了认知负荷与视觉信息熵之间的量化关系,为神经美学研究提供了新的计算范式。
衍生相关工作
基于SVG数据集的特征工程方法,MIT媒体实验室开发了ViCoP框架,实现了对抽象绘画复杂度的跨文化预测。其惊讶度指标启发了Google DeepMind的VASER系统,通过关联视觉复杂度与记忆留存率提升广告设计效果。此外,数据集提供的SAM分割数据支撑了UC Berkeley关于场景理解中层级注意力机制的研究,相关成果发表于CVPR 2025。
以上内容由遇见数据集搜集并总结生成


