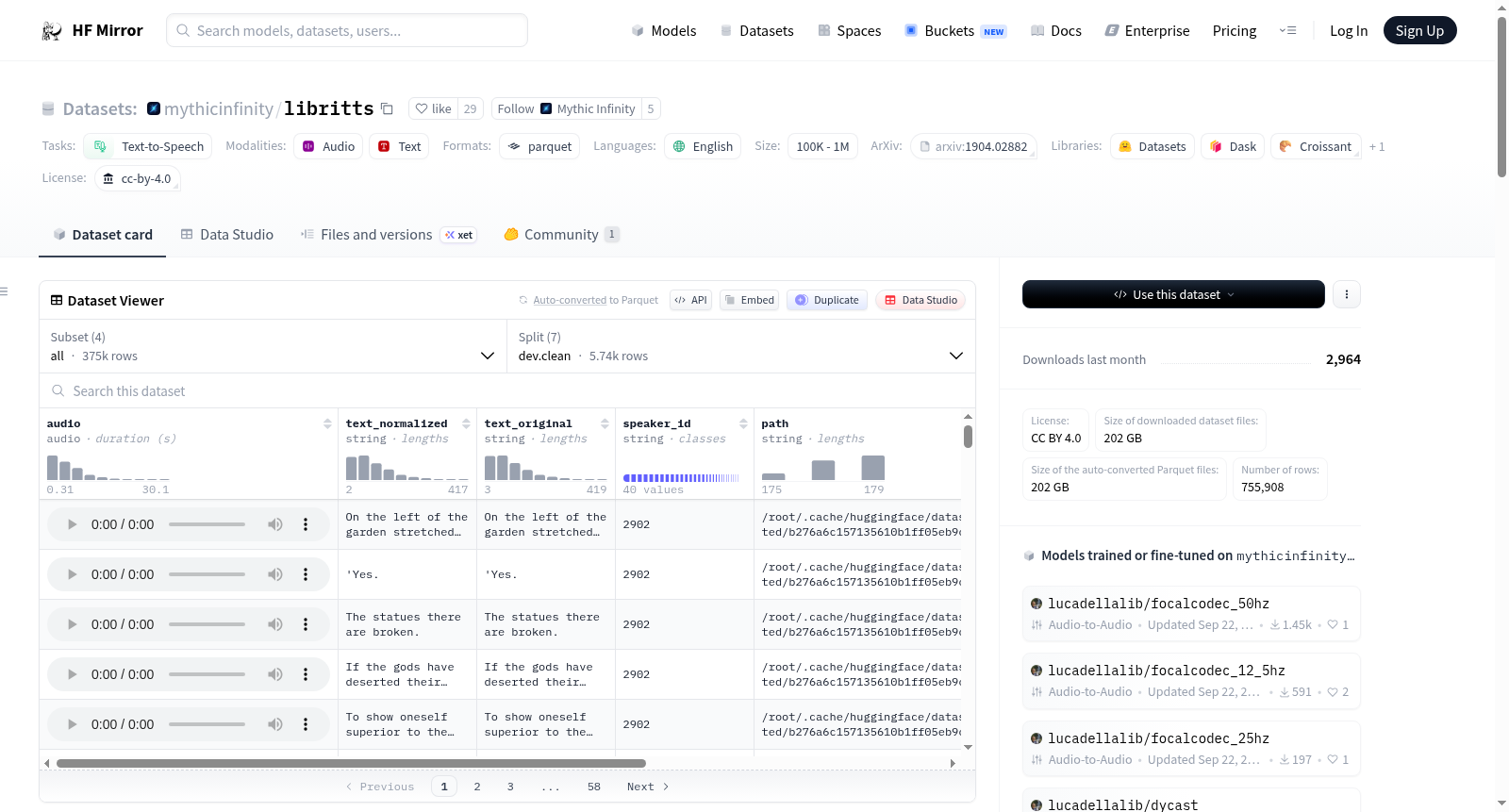
blabble-io/libritts
收藏数据集卡片 for LibriTTS
概述
LibriTTS 是一个多说话者的英语语料库,大约包含 585 小时的 24kHz 采样率的英语朗读语音,由 Heiga Zen 准备,并得到 Google Speech 和 Google Brain 团队成员的协助。LibriTTS 语料库旨在用于 TTS 研究。它源自 LibriSpeech 语料库的原始材料(来自 LibriVox 的 mp3 音频文件和来自 Project Gutenberg 的文本文件)。
使用
分割
数据集包含 7 个分割:
- dev.clean
- dev.other
- test.clean
- test.other
- train.clean.100
- train.clean.360
- train.other.500
配置
数据集有 3 个配置,每个配置限制了 load_dataset() 函数将下载的分割。
默认配置是 "all"。
- "dev": 仅包含 "dev.clean" 分割(适用于快速测试数据集)
- "clean": 仅包含 "clean" 分割
- "other": 仅包含 "other" 分割
- "all": 包含所有分割
示例
加载 clean 配置,仅包含 train.clean.100 分割:
python load_dataset("blabble-io/libritts", "clean", split="train.clean.100")
支持流式加载:
python load_dataset("blabble-io/libritts", streaming=True)
列
数据集包含以下列:
json { "audio": datasets.Audio(sampling_rate=24_000), "text_normalized": datasets.Value("string"), "text_original": datasets.Value("string"), "speaker_id": datasets.Value("string"), "path": datasets.Value("string"), "chapter_id": datasets.Value("string"), "id": datasets.Value("string"), }
示例行
json { audio: { path: /home/user/.cache/huggingface/datasets/downloads/extracted/5551a515e85b9e463062524539c2e1cb52ba32affe128dffd866db0205248bdd/LibriTTS/dev-clean/3081/166546/3081_166546_000028_000002.wav, array: ..., sampling_rate: 24000 }, text_normalized: How quickly he disappeared!", text_original: How quickly he disappeared!", speaker_id: 3081, path: /home/user/.cache/huggingface/datasets/downloads/extracted/5551a515e85b9e463062524539c2e1cb52ba32affe128dffd866db0205248bdd/LibriTTS/dev-clean/3081/166546/3081_166546_000028_000002.wav, chapter_id: 166546, id: 3081_166546_000028_000002 }
数据集详情
数据集描述
- 许可证: CC BY 4.0