joelniklaus/mapa
收藏Hugging Face2022-10-25 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/joelniklaus/mapa
下载链接
链接失效反馈官方服务:
资源简介:
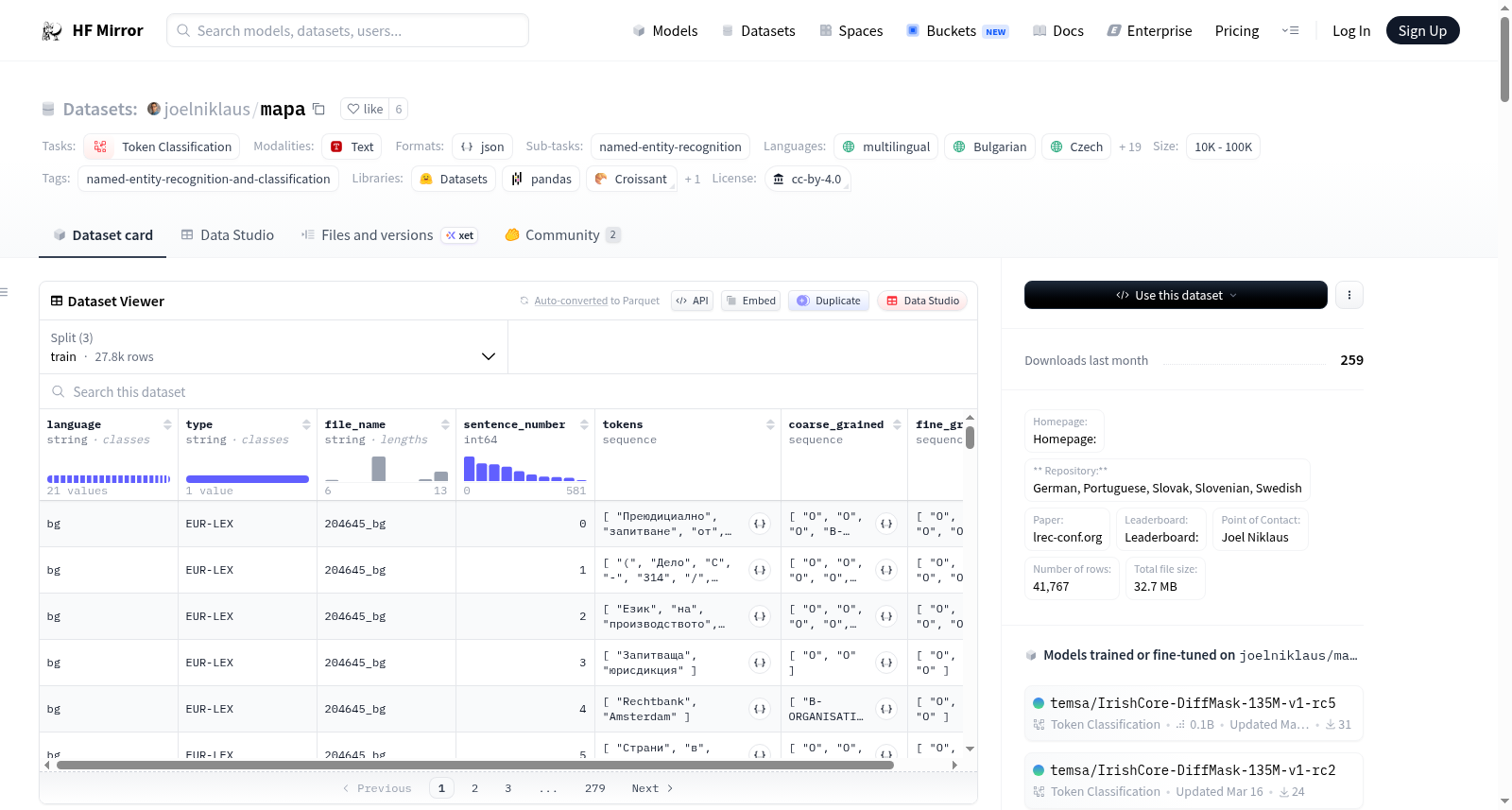
该数据集由来自EUR-Lex的12份文档(西班牙语为9份,由于解析错误)组成,EUR-Lex是一个包含欧盟24种官方语言的法院判决和法律处置的多语言语料库。这些文档已根据MAPA项目的指南进行了命名实体注释,该指南预见了两层注释,一层是通用的,另一层是更细粒度的。注释后的语料库可用于命名实体识别/分类。数据集支持的任务是命名实体识别和分类(NERC),支持的语言包括bg、cs、da、de、el、en、es、et、fi、fr、ga、hu、it、lt、lv、mt、nl、pt、ro、sk、sv。数据集的结构为jsonl格式,包含训练、验证和测试三个数据分割。注释过程分为粗粒度和细粒度两个层次,分别使用了不同的标签集。
提供机构:
joelniklaus
原始信息汇总
数据集概述
数据集描述
数据集摘要
- 名称: Multilingual European Datasets for Sensitive Entity Detection in the Legal Domain
- 内容: 包含12个文档,主要用于西班牙语的敏感实体检测,源自EUR-Lex的多语言法律文件。
- 用途: 用于命名实体识别和分类(NERC)。
- 语言: 支持多种语言,包括bg, cs, da, de, el, en, es, et, fi, fr, ga, hu, it, lt, lv, mt, nl, pt, ro, sk, sv。
支持的任务和排行榜
- 任务: 命名实体识别和分类(NERC)。
语言支持
- 语言列表: bg, cs, da, de, el, en, es, et, fi, fr, ga, hu, it, lt, lv, mt, nl, pt, ro, sk, sv。
数据集结构
数据实例
- 格式: jsonl。
- 分割: 包含训练、验证和测试集。
数据字段
language: 句子语言。type: 文档类型,目前仅支持EUR-LEX。file_name: 文档文件名。sentence_number: 句子在文档中的编号。tokens: 句子中的词列表。coarse_grained: 粗粒度标注。fine_grained: 细粒度标注。
数据分割
- 分割详情: 每个语言的训练、验证和测试文件数量及句子数量。
数据集创建
来源数据
- 数据源: EUR-Lex corpus。
- 语言生产者: 律师。
标注过程
- 标注工具: INCePTION。
- 标注者数量: 1。
- 标注层次: 两级,包括粗粒度和细粒度。
许可证
- 许可证类型: CC-BY-4.0。
引用信息
@article{DeGibertBonet2022, author = {{de Gibert Bonet}, Ona and {Garc{{i}}a Pablos}, Aitor and Cuadros, Montse and Melero, Maite}, journal = {Proceedings of the Language Resources and Evaluation Conference}, number = {June}, pages = {3751--3760}, title = {{Spanish Datasets for Sensitive Entity Detection in the Legal Domain}}, url = {https://aclanthology.org/2022.lrec-1.400}, year = {2022} }
搜集汇总
数据集介绍
背景与挑战
背景概述
该数据集是一个多语言命名实体识别数据集,专注于法律领域,基于EUR-Lex欧盟法律文档构建,支持21种欧盟官方语言。数据集采用双层标注体系,包含粗粒度和细粒度实体标签,旨在用于敏感实体检测和匿名化工具开发。数据以json格式提供,分为训练、验证和测试集,总行数约41.8k。
以上内容由遇见数据集搜集并总结生成


