Huatuo26M-Lite
收藏魔搭社区2026-05-22 更新2025-01-25 收录
下载链接:
https://modelscope.cn/datasets/FreedomIntelligence/Huatuo26M-Lite
下载链接
链接失效反馈官方服务:
资源简介:
# Huatuo26M-Lite 📚
- ## Table of Contents 🗂
- [Dataset Description](#dataset-description) 📝
- [Dataset Information](#dataset-information) ℹ️
- [Data Distribution](#data-distribution) 📊
- [Usage](#usage) 🔧
- [Citation](#citation) 📖
## Dataset Description 📝
Huatuo26M-Lite is a refined and optimized dataset based on the Huatuo26M dataset, which has undergone multiple purification processes and rewrites. It has more data dimensions and higher data quality. We welcome you to try using it.
## Dataset Information ℹ️
- **Dataset Name:** Huatuo26M-Lite
- **Version:** _[0.0.1]_
- **Size:** _[178k]_
- **Language:** _[Chinese]_
### Abstract 📄
We collected 26 million pieces of original QA data in the medical field, but it was not easy to use and had some risks because it was obtained from Common Crawl. Therefore, we took the following steps based on the original 26 million data: deduplication, cleaning, extraction of high-frequency questions, scoring of high-frequency questions using ChatGPT, and filtering only high-scoring questions. We then used ChatGPT to rewrite the answers to the high-scoring questions, resulting in a completely refined dataset. Please refer to our paper for the specific processing methods.
### Data Collection 🕵️♂️
ur question data was collected from the internet, and we extracted the high-frequency portion. The answers were rewritten by ChatGPT based on the original answers as a reference, and their quality was judged to be better than the original answers through manual evaluation. Therefore, please feel free to use our dataset with confidence.
### Preprocessing/Cleaning 🧹
The dataset has been processed to remove duplicates and cleaned to ensure high-quality data. It was then refined using OpenAI's ChatGPT, which helped in enhancing the overall quality of the dataset.
## Data Distribution 📊
This section provides a visual overview of the distribution of data in the Huatuo26M-Lite dataset.
**Data Categories Bar Chart:** 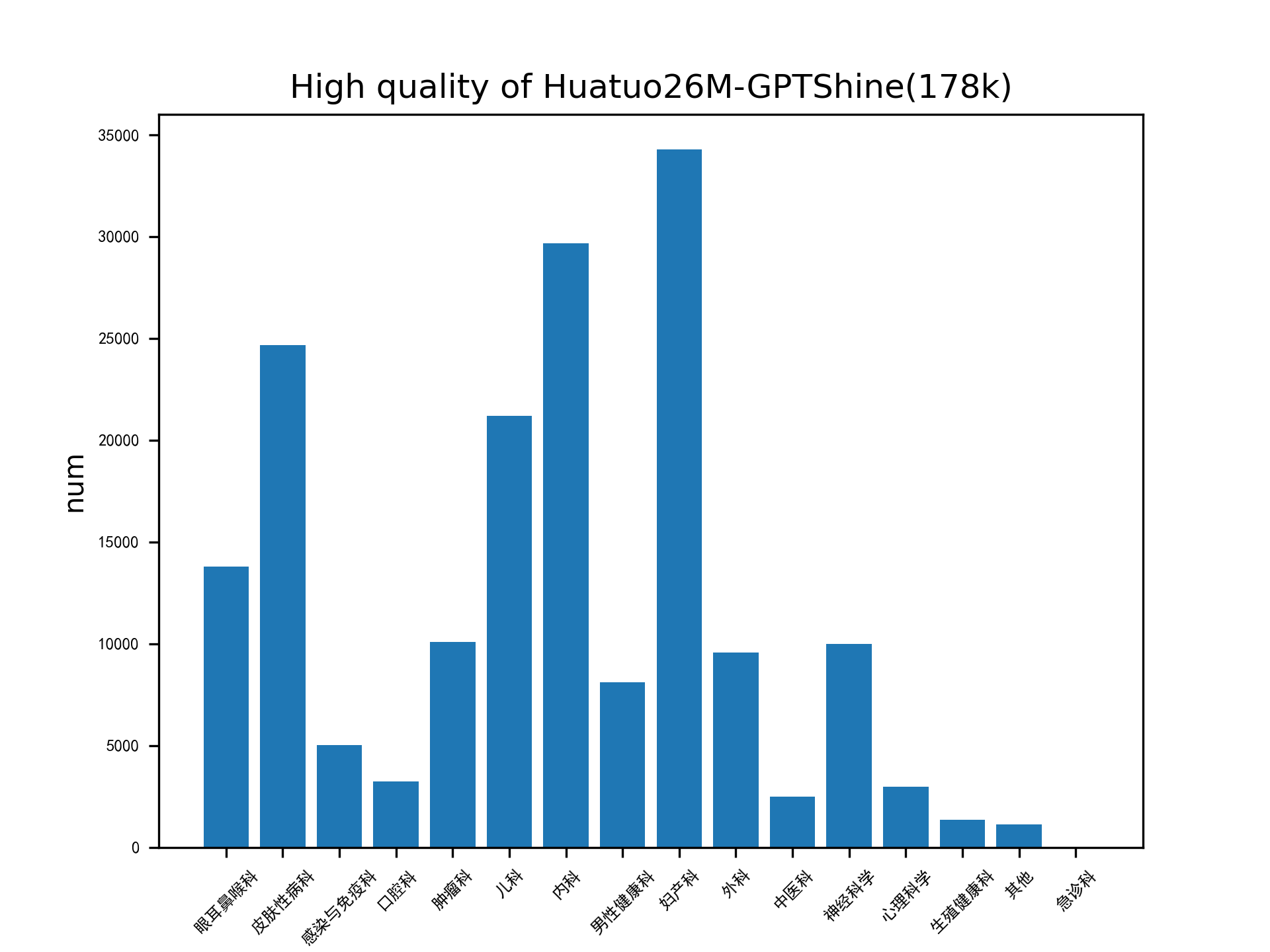
This chart represents the distribution of data categories in the dataset.
**Top 20 Associated Diseases Table:**
| topn | disease | nums | ratio |
| ---- | ---------- | ---- | ------- |
| 1 | 白癜风 | 3308 | 1.8615% |
| 2 | 人流 | 2686 | 1.5115% |
| 3 | 感冒 | 2371 | 1.3342% |
| 4 | 癫痫 | 2217 | 1.2476% |
| 5 | 痔疮 | 2134 | 1.2009% |
| 6 | 疼痛 | 1842 | 1.0366% |
| 7 | 咳嗽 | 1799 | 1.0124% |
| 8 | 前列腺炎 | 1564 | 0.8801% |
| 9 | 尖锐湿疣 | 1516 | 0.8531% |
| 10 | 肺癌 | 1408 | 0.7923% |
| 11 | 出血 | 1400 | 0.7878% |
| 12 | 鼻炎 | 1370 | 0.7709% |
| 13 | 肝癌 | 1354 | 0.7619% |
| 14 | 糖尿病 | 1348 | 0.7586% |
| 15 | 过敏性鼻炎 | 1295 | 0.7287% |
| 16 | 发烧 | 1265 | 0.7119% |
| 17 | 乙肝 | 1232 | 0.6933% |
| 18 | 便秘 | 1214 | 0.6832% |
| 19 | 甲亢 | 1178 | 0.6629% |
| 20 | 脱发 | 1173 | 0.6601% |
This table shows the top 20 diseases associated with the data entries in the dataset, along with their respective data entry counts and proportions.
## Usage 🔧
```python
from datasets import load_dataset
dataset = load_dataset("FreedomIntelligence/Huatuo26M-Lite")
```
## Citation 📖
```
@misc{li2023huatuo26m,
title={Huatuo-26M, a Large-scale Chinese Medical QA Dataset},
author={Jianquan Li and Xidong Wang and Xiangbo Wu and Zhiyi Zhang and Xiaolong Xu and Jie Fu and Prayag Tiwari and Xiang Wan and Benyou Wang},
year={2023},
eprint={2305.01526},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
---
Please note that this dataset is distributed "AS IS" without any warranty, express or implied, from the provider. Users should cite the dataset appropriately and respect any licensing or usage restrictions.
# Huatuo26M-Lite 📚
- ## 目录 🗂
- [数据集描述 📝](#dataset-description)
- [数据集信息 ℹ️](#dataset-information)
- [数据分布 📊](#data-distribution)
- [使用方法 🔧](#usage)
- [引用格式 📖](#citation)
## 数据集描述 📝
Huatuo26M-Lite 是基于 Huatuo26M 数据集优化提纯后的轻量化版本,历经多轮数据净化与重写流程,具备更丰富的数据维度与更高的数据质量,欢迎各位试用。
## 数据集信息 ℹ️
- **数据集名称:** Huatuo26M-Lite
- **版本:** _[0.0.1]_
- **数据规模:** _[178k]_
- **语言:** _[中文]_
### 摘要 📄
我们最初采集了2600万条医疗领域原始问答数据,但由于数据源自通用爬虫(Common Crawl),存在可用性欠佳且带有一定风险的问题。因此,我们针对原始2600万条数据开展了如下处理流程:去重、数据清洗、提取高频问题、使用 ChatGPT 对高频问题进行评分并仅保留高分问题,随后利用 ChatGPT 重写高分问题对应的答案,最终得到经过全面提纯的高质量数据集。具体处理细节可参阅我们的学术论文。
### 数据采集 🕵️♂️
我们的问题数据源自互联网,并从中提取了高频部分。答案以原始回答为参考,由 ChatGPT 重写生成;经人工评估,重写后的答案质量优于原始答案。因此,您可放心使用本数据集。
### 预处理与数据清洗 🧹
本数据集已完成去重与清洗操作,以保障数据质量;随后通过 OpenAI 的 ChatGPT 进行进一步提纯,全面提升了数据集的整体质量。
## 数据分布 📊
本章节将直观展示 Huatuo26M-Lite 数据集的数据分布情况。
**数据类别柱状图:** 
该图表展示了本数据集的数据类别分布。
**关联疾病Top20统计表:**
| 排名 | 疾病名称 | 样本量 | 占比 |
| ---- | -------- | ---- | ------- |
| 1 | 白癜风 | 3308 | 1.8615% |
| 2 | 人流 | 2686 | 1.5115% |
| 3 | 感冒 | 2371 | 1.3342% |
| 4 | 癫痫 | 2217 | 1.2476% |
| 5 | 痔疮 | 2134 | 1.2009% |
| 6 | 疼痛 | 1842 | 1.0366% |
| 7 | 咳嗽 | 1799 | 1.0124% |
| 8 | 前列腺炎 | 1564 | 0.8801% |
| 9 | 尖锐湿疣 | 1516 | 0.8531% |
| 10 | 肺癌 | 1408 | 0.7923% |
| 11 | 出血 | 1400 | 0.7878% |
| 12 | 鼻炎 | 1370 | 0.7709% |
| 13 | 肝癌 | 1354 | 0.7619% |
| 14 | 糖尿病 | 1348 | 0.7586% |
| 15 | 过敏性鼻炎 | 1295 | 0.7287% |
| 16 | 发烧 | 1265 | 0.7119% |
| 17 | 乙肝 | 1232 | 0.6933% |
| 18 | 便秘 | 1214 | 0.6832% |
| 19 | 甲亢 | 1178 | 0.6629% |
| 20 | 脱发 | 1173 | 0.6601% |
该统计表列出了本数据集关联度最高的前20种疾病,以及对应的样本量与占比情况。
## 使用方法 🔧
python
from datasets import load_dataset
dataset = load_dataset("FreedomIntelligence/Huatuo26M-Lite")
## 引用格式 📖
@misc{li2023huatuo26m,
title={Huatuo-26M, a Large-scale Chinese Medical QA Dataset},
author={Jianquan Li and Xidong Wang and Xiangbo Wu and Zhiyi Zhang and Xiaolong Xu and Jie Fu and Prayag Tiwari and Xiang Wan and Benyou Wang},
year={2023},
eprint={2305.01526},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
---
请注意,本数据集按“现状”分发,不提供任何明示或暗示的担保。使用者应正确引用本数据集,并遵守相关许可及使用限制。
提供机构:
maas
创建时间:
2025-01-20
搜集汇总
数据集介绍
背景与挑战
背景概述
Huatuo26M-Lite是一个基于Huatuo26M优化的中文医疗问答数据集,经过去重、清洗和ChatGPT改写处理,以提高数据质量和维度。数据集包含178k个条目,覆盖常见医疗问题如白癜风、感冒和糖尿病等,适用于医疗领域的自然语言处理任务。
以上内容由遇见数据集搜集并总结生成


