SynSQL-2.5M
收藏github2025-03-12 更新2025-03-06 收录
下载链接:
https://github.com/RUCKBReasoning/OmniSQL
下载链接
链接失效反馈官方服务:
资源简介:
SynSQL-2.5M是一个高质量的人工合成的文本到SQL数据集,包含超过250万个多样且高质量的数据样本,涵盖了来自不同领域的16,000多个数据库。数据集包括2,544,390个多样且复杂的文本到SQL样本,每个样本由一个<数据库, 问题, SQL查询, 思维链解决方案>四元组组成。数据集覆盖了16,583个来自现实场景的合成数据库,并涵盖了从简单到高度复杂的SQL查询。
SynSQL-2.5M is a high-quality synthetic text-to-SQL dataset containing over 2.5 million diverse and high-quality data samples, covering more than 16,000 databases from various domains. The dataset includes 2,544,390 diverse and complex text-to-SQL samples, each consisting of a quadruple of <database, question, SQL query, chain-of-thought solution>. It covers 16,583 synthetic databases derived from real-world scenarios, and spans SQL queries ranging from simple to highly complex.
创建时间:
2025-02-27
原始信息汇总
OmniSQL 数据集概述
数据集简介
- 名称: OmniSQL - Synthesizing High-quality Text-to-SQL Data at Scale
- 核心数据集: SynSQL-2.5M
- 规模: 超过250万条多样化的高质量文本到SQL样本
- 覆盖范围: 16,000多个来自不同领域的数据库
- 论文链接: https://arxiv.org/abs/2503.02240
- GitHub链接: https://github.com/RUCKBReasoning/OmniSQL
数据集详情
SynSQL-2.5M
- 样本数量: 2,544,390条
- 样本组成: 每个样本包含
<database, question, SQL query, chain-of-thought solution>四元组 - 数据库数量: 16,583个合成数据库
- SQL复杂度: 涵盖
simple, moderate, complex, highly complex四个级别 - 自然语言问题风格:
formal, colloquial, imperative, interrogative, descriptive, concise, vague, metaphorical, conversational
模型家族
- OmniSQL-7B: ✨ Modelscope, 🤗 HuggingFace
- OmniSQL-14B: ✨ Modelscope, 🤗 HuggingFace
- OmniSQL-32B: ✨ Modelscope, 🤗 HuggingFace
性能评估
- 评估数据集: Spider, BIRD, Spider2.0-SQLite, ScienceBenchmark, EHRSQL, Spider-DK, Spider-Syn, Spider-Realistic
- 评估指标: 测试套件准确率(TS)和执行准确率(EX)
- 性能表现: 显著优于类似规模的基线LLM,并在多个数据集上超过GPT-4o和DeepSeek-V3
快速开始
提示模板
python input_prompt_template = Task Overview: You are a data science expert. Below, you are provided with a database schema and a natural language question. Your task is to understand the schema and generate a valid SQL query to answer the question.
Database Engine: SQLite
Database Schema: {db_details} This schema describes the databases structure, including tables, columns, primary keys, foreign keys, and any relevant relationships or constraints.
Question: {question}
Instructions:
- Make sure you only output the information that is asked in the question. If the question asks for a specific column, make sure to only include that column in the SELECT clause, nothing more.
- The generated query should return all of the information asked in the question without any missing or extra information.
- Before generating the final SQL query, please think through the steps of how to write the query.
Output Format: In your answer, please enclose the generated SQL query in a code block:
-- Your SQL query
Take a deep breath and think step by step to find the correct SQL query.
局限性
- 语言限制: 仅支持英语
- 数据库引擎限制: 仅支持SQLite
搜集汇总
数据集介绍
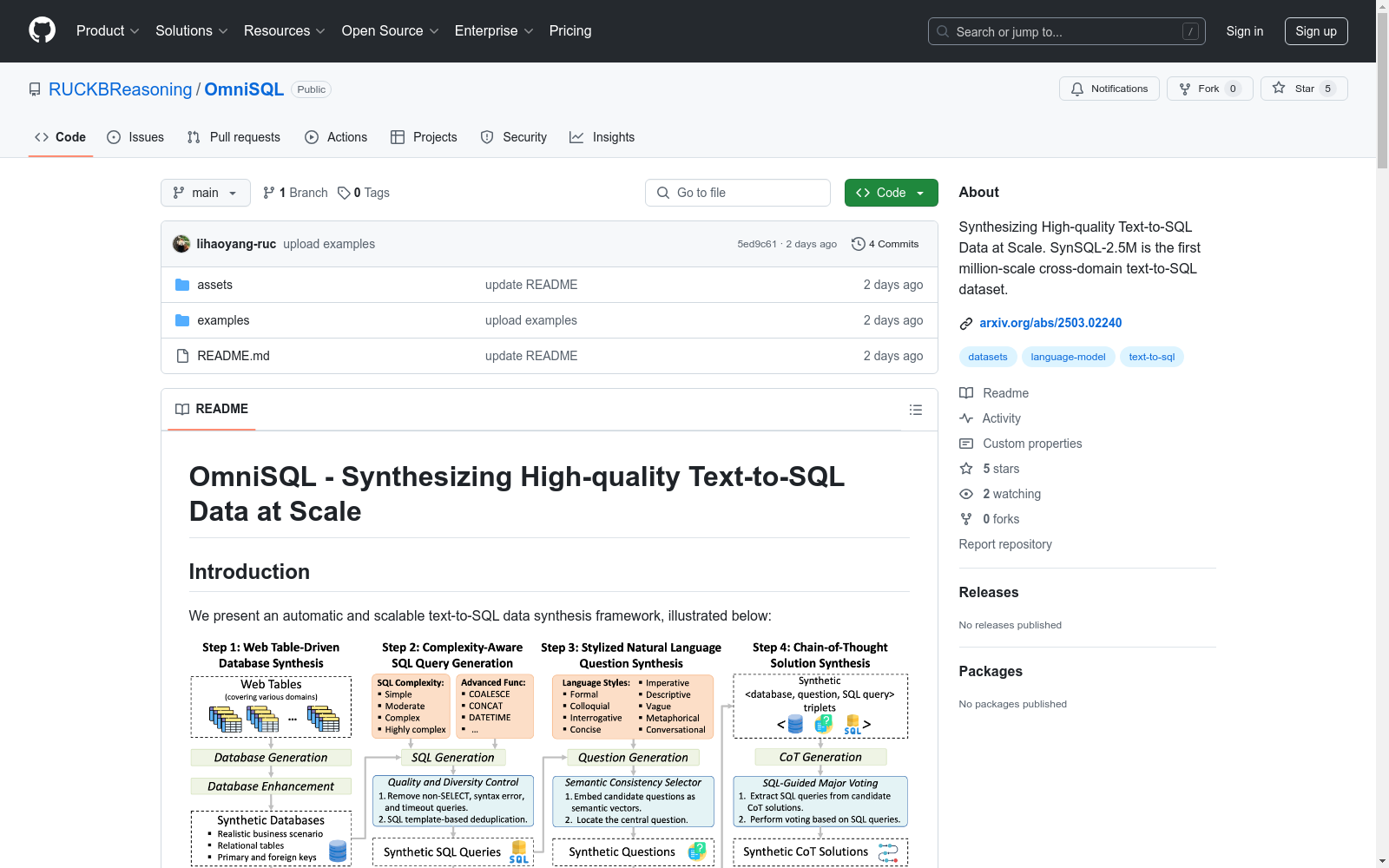
构建方式
SynSQL-2.5M是一个基于自动化和可扩展的text-to-SQL数据合成框架构建的数据集。该框架利用超过16000个来自不同领域的数据库名称和结构信息,自动生成包含250万条以上多样性和高质量数据样本的SQL查询和自然语言描述对。
特点
该数据集的主要特点是涵盖了广泛的主题和数据库结构,支持SQLite数据库引擎。SynSQL-2.5M数据集采用大规模自动合成方法,保证了数据的多样性和丰富性,且所有数据样本均为高质量合成,适用于text-to-SQL模型的训练和评估。
使用方法
用户可以通过Modelscope和HuggingFace平台下载SynSQL-2.5M数据集。数据集的使用涉及将数据库结构和自然语言问题作为输入,通过OmniSQL模型生成相应的SQL查询。数据集支持使用vLLM和Transformers库进行推断,具体使用方法包括准备输入模板、加载预训练模型、配置生成参数,以及执行推断操作。
背景与挑战
背景概述
SynSQL-2.5M是一个大规模的文本到SQL数据合成框架下的产物,由相关研究人员和机构开发,旨在提供高质量、多样化的数据样本。该数据集的创建时间是近期,并且包含了超过250万个数据样本,跨越了超过16000个来自不同领域的数据库名称。SynSQL-2.5M的核心研究问题是提高文本到SQL的转换质量与准确性,对于自然语言处理和数据库研究领域具有显著的影响,推动了相关技术的发展和应用。
当前挑战
SynSQL-2.5M在构建过程中遇到的挑战包括如何保证数据样本的质量和多样性,以及如何处理大规模数据集的生成和存储问题。在所解决的领域问题方面,该数据集面临的挑战是如何有效地将自然语言问题转化为结构化的SQL查询语句,同时保持查询的准确性和效率。此外,SynSQL-2.5M作为一个英语数据集,其在多语言和多SQL方言场景下的性能限制也是一个挑战。
常用场景
经典使用场景
SynSQL-2.5M数据集作为目前最大的文本到SQL数据集,其经典使用场景主要集中于自然语言处理领域,尤其是文本到SQL的语义解析任务。该数据集通过提供大规模、多样化的数据样本,使得研究者能够训练和评估模型在理解和转换自然语言查询到结构化查询语言的能力。
解决学术问题
该数据集解决了学术研究中缺乏大规模、高质量文本到SQL数据样本的问题,有助于推动自然语言处理技术在数据库查询领域的应用。它使得研究者能够训练出更加精准的模型,以应对实际应用中复杂的查询需求,同时为评估模型的性能提供了统一的标准。
衍生相关工作
基于SynSQL-2.5M数据集,衍生了一系列相关工作,包括但不限于OmniSQL模型系列的研发。这些工作进一步探索了模型在处理不同数据库引擎、不同SQL方言以及跨语言查询等方面的能力,为文本到SQL领域的研究和实际应用提供了新的视角和方法论。
以上内容由遇见数据集搜集并总结生成


