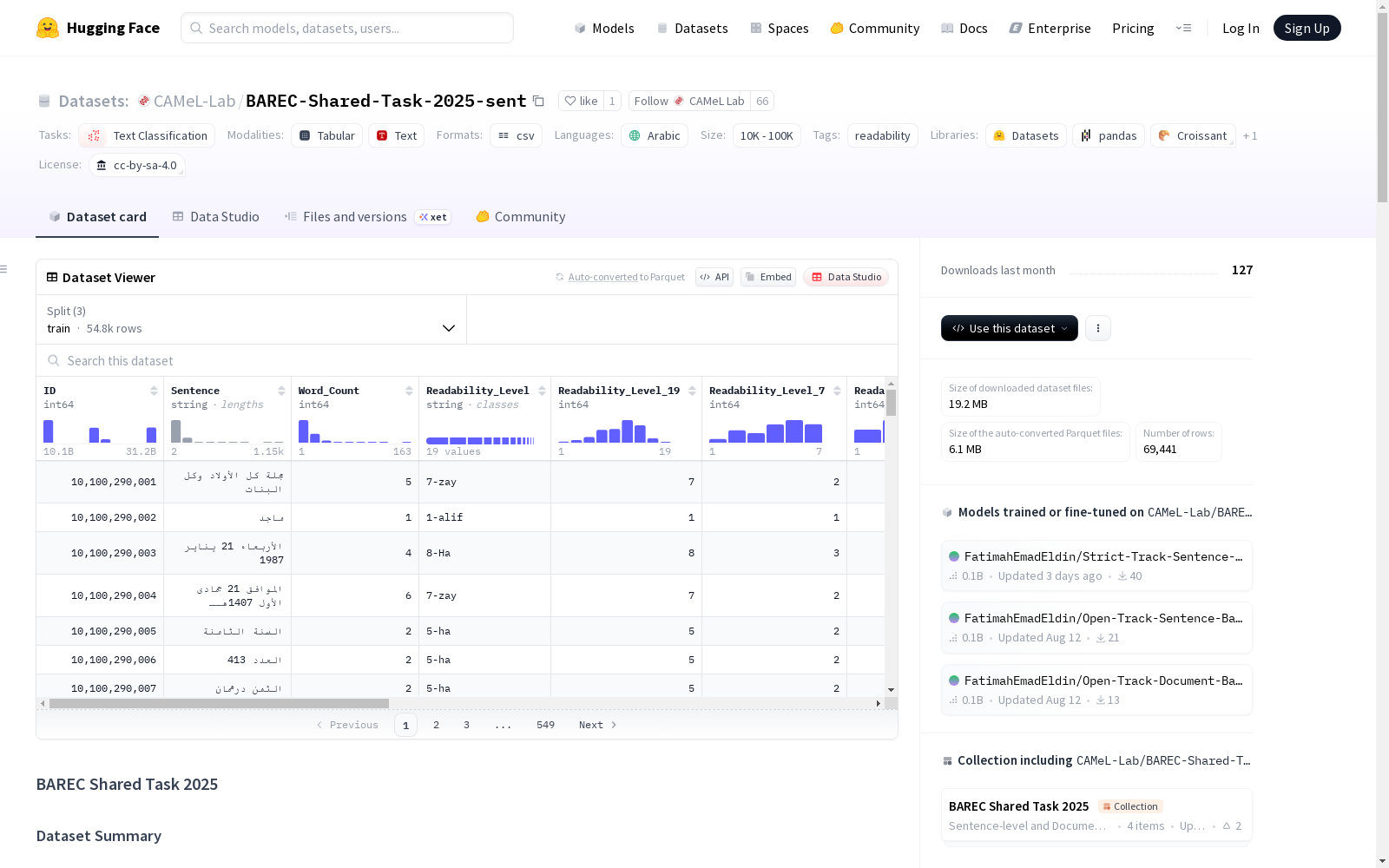
BAREC-Shared-Task-2025-sent
收藏BAREC Shared Task 2025 数据集概述
数据集基本信息
- 名称: BAREC (Balanced Arabic Readability Evaluation Corpus)
- 用途: 阿拉伯语细粒度可读性评估
- 许可证: MIT
- 任务类别: 文本分类
- 语言: 阿拉伯语 (现代标准阿拉伯语)
- 标签: 可读性
- 规模: 10K<n<100K
数据集内容
- 数据量: 超过100万单词
- 标注粒度: 句子级别
- 可读性级别:
- 19级 (默认)
- 7级
- 5级
- 3级
- 文档级别可读性: 基于文档中最难句子的19级可读性级别
数据结构
数据实例
python { ID: 10100010008, Sentence: عيد سعيد, Word_Count: 2, Readability_Level: 2-ba, Readability_Level_19: 2, Readability_Level_7: 1, Readability_Level_5: 1, Readability_Level_3: 1, Annotator: A4, Document: BAREC_Majed_0229_1983_001.txt, Source: Majed, Book: Edition: 229, Author: #, Domain: Arts & Humanities, Text_Class: Foundational }
数据字段
- ID: 唯一句子标识符
- Sentence: 句子文本
- Word_Count: 句子中的单词数
- Readability_Level: 19级可读性级别 (1-alif到19-qaf)
- Readability_Level_19: 19级可读性级别 (1到19)
- Readability_Level_7: 7级可读性级别 (1到7)
- Readability_Level_5: 5级可读性级别 (1到5)
- Readability_Level_3: 3级可读性级别 (1到3)
- Annotator: 标注者ID (A1-A5或IAA)
- Document: 源文档文件名
- Source: 文档来源
- Book: 书名
- Author: 作者名
- Domain: 领域 (Arts & Humanities, STEM或Social Sciences)
- Text_Class: 读者群 (Foundational, Advanced或Specialized)
数据划分
- 训练集: 80%
- 开发集: 10%
- 测试集: 10%
- 划分方式: 文档级别
- 平衡性: 在可读性级别、领域和文本类别上保持平衡
评估指标
- 准确率 (Acc<sup>19</sup>, Acc<sup>7</sup>, Acc<sup>5</sup>, Acc<sup>3</sup>)
- 相邻准确率 (±1 Acc<sup>19</sup>)
- 平均距离 (Dist)
- 二次加权Kappa (QWK)
引用
bibtex @inproceedings{elmadani-etal-2025-readability, title = "A Large and Balanced Corpus for Fine-grained Arabic Readability Assessment", author = "Elmadani, Khalid N. and Habash, Nizar and Taha-Thomure, Hanada", booktitle = "Findings of the Association for Computational Linguistics: ACL 2025", year = "2025", address = "Vienna, Austria", publisher = "Association for Computational Linguistics" }
@inproceedings{habash-etal-2025-guidelines, title = "Guidelines for Fine-grained Sentence-level Arabic Readability Annotation", author = "Habash, Nizar and Taha-Thomure, Hanada and Elmadani, Khalid N. and Zeino, Zeina and Abushmaes, Abdallah", booktitle = "Proceedings of the 19th Linguistic Annotation Workshop (LAW-XIX)", year = "2025", address = "Vienna, Austria", publisher = "Association for Computational Linguistics" }