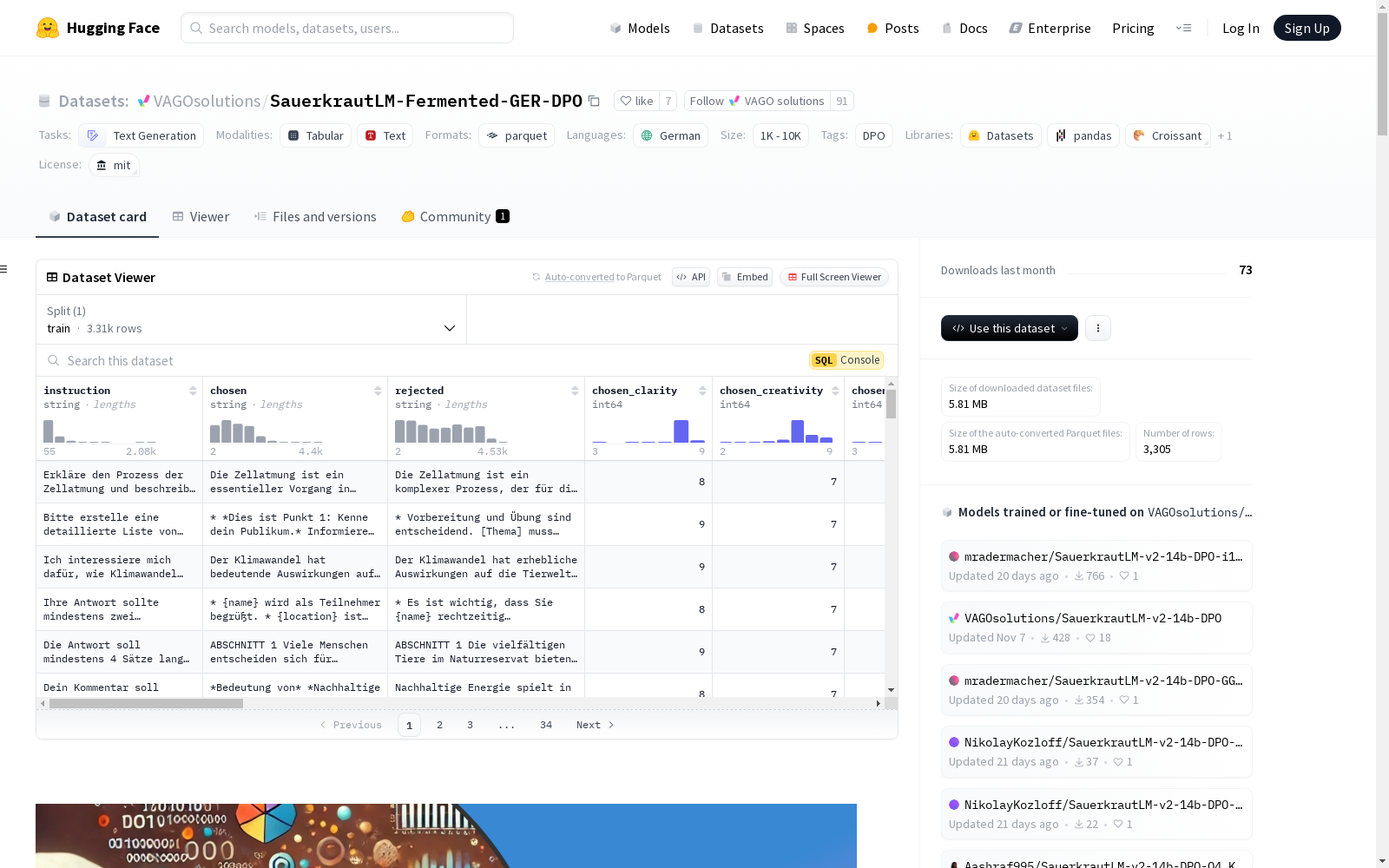
SauerkrautLM-Fermented-GER-DPO
收藏SauerkrautLM-Fermented-GER-DPO 数据集概述
概述
SauerkrautLM-Fermented-GER-DPO 是一个高质量的德语指令-响应数据集,专门为直接偏好优化(DPO)训练设计。该数据集包含 3,305 个指令-响应对,通过复杂的增强过程将精选的英语指令和响应转换为文化适应的德语内容。每个对包括全面的质量指标和用于 DPO 训练的拒绝响应。
数据集创建过程
1. 初始数据创建与增强
- 源数据:精选的英语指令-响应对
- 高级增强过程:将英语内容转换为德语
- 文化适应与语境化:针对德语区进行文化适应和语境化
- 质量控制转换:确保德语表达的地道性
- 保留指令意图:在适应文化语境的同时保留指令意图
2. 质量评估
每个选定的响应在九个不同的质量维度上进行评估,评分范围为 1-10:
- 清晰度:评估表达的清晰度和可理解性(平均:8.05)
- 创造力:衡量原创性和创新思维(平均:7.29)
- 文化适应性:评估对德语文化语境的适应性(平均:7.58)
- 语言质量:评估整体语言质量(平均:7.99)
- 语法:衡量语法正确性(平均:9.00)
- 连贯性:评估逻辑流程和结构(平均:8.04)
- 任务完成度:评估响应如何完成指令(平均:8.13)
- 指令-响应匹配度:衡量与指令的对齐程度(平均:8.55)
- 指令-响应连贯性:评估主题一致性(平均:7.96)
3. DPO 增强
- 生成替代响应:使用受控生成过程为每个指令生成替代的“拒绝”响应
- 质量差异评估:评估选定和拒绝响应之间的质量差异
- 保留原始质量指标:为参考保留原始质量指标
4. 差异评估
每个选定-拒绝对在所有指标上进行质量差异评估,评分范围为 1-10:
- 10:选定响应显著更好
- 5:两个响应质量相等
- 1:拒绝响应显著更好
数据集格式
json { "instruction": "德语指令/提示", "chosen": "高质量选定响应", "rejected": "DPO 替代响应", "chosen_clarity": float, "chosen_creativity": float, "chosen_cultural_fit": float, "chosen_language_quality": float, "chosen_grammar": float, "chosen_coherence": float, "chosen_task_completion": float, "chosen_prompt_response_match": float, "chosen_prompt_response_coherence": float, "chosen_overall_score": float, "clarity_diff": float, "creativity_diff": float, "cultural_fit_diff": float, "language_quality_diff": float, "grammar_diff": float, "coherence_diff": float, "task_completion_diff": float, "prompt_response_match_diff": float, "prompt_response_coherence_diff": float, "overall_difference": float }
质量指标
选定响应质量分布
- 优秀(90-100):20 个示例(0.61%)
- 良好(79-89):3,020 个示例(91.38%)
- 可接受(60-78):69 个示例(2.09%)
- 需改进(<60):33 个示例(1.00%)
质量阈值
- 高质量(≥80):2,668 个示例(80.73%)
- 中等质量(60-79):604 个示例(18.28%)
- 低质量(<60):33 个示例(1.00%)
选定 vs. 拒绝分析
选定和拒绝响应之间的平均质量差异:
- 总体差异:78.85(中位数:83.0)
- 分布:
- 选定显著更好(>75):2,631 对(79.61%)
- 选定更好(60-75):395 对(11.95%)
- 相似质量(40-59):144 对(4.36%)
- 拒绝更好(<40):135 对(4.08%)
详细指标差异(选定 vs. 拒绝)
- 清晰度:+7.82
- 创造力:+6.92
- 文化适应性:+6.86
- 语言质量:+8.12
- 语法:+8.14
- 连贯性:+7.85
- 任务完成度:+8.32
- 指令-响应匹配度:+8.23
- 指令-响应连贯性:+7.97
统计亮点
语法和语言质量
- 语法显示最高平均分(9.00),最低标准差(0.27)
- 语言质量保持一致的高标准(平均:7.99,标准差:0.35)
任务对齐
- 指令-响应匹配度显示强劲表现(平均:8.55,中位数:9.0)
- 任务完成度显示高可靠性(平均:8.13,标准差:0.72)
许可证
MIT 许可证
引用
@dataset{SauerkrautLM-Fermented-GER-DPO, title={SauerkrautLM-Fermented-GER-DPO: A Quality-Evaluated German Instruction Dataset for DPO Training}, year={2024}, publisher={VAGO Solutions}, version={1.0} }
预期用途
- 使用 DPO 微调德语语言模型
- 研究德语指令跟随能力
- 基准测试德语语言模型性能
- 研究直接偏好优化技术
局限性
- 质量指标为模型评估,应视为指导
- 数据集规模中等(3,305 对)
- 专注于一般指令跟随场景
- 数据集通过自动化和手动过滤程序进行质量保证,尽管经过彻底预处理,仍可能存在异常,鼓励用户在使用过程中报告任何发现的问题,以促进数据集的持续改进和质量提升。