CelebV-Text
收藏arXiv2023-03-26 更新2024-06-21 收录
下载链接:
https://celebv-text.github.io
下载链接
链接失效反馈官方服务:
资源简介:
CelebV-Text是由新加坡南洋理工大学S-Lab创建的大规模面部文本-视频数据集,包含70,000个野生面部视频片段,每个视频片段配以20个文本描述。数据集旨在促进面部文本到视频生成任务的研究,涵盖了从静态到动态的多种面部属性描述,如外观、动作和情感。创建过程包括数据收集、处理、标注和半自动文本生成,确保了文本与视频之间的高度相关性。该数据集适用于开发和评估面部文本到视频生成的先进模型,解决视频生成中缺乏高质量和相关文本描述的问题。
CelebV-Text is a large-scale facial text-video dataset developed by S-Lab at Nanyang Technological University, Singapore. It contains 70,000 unconstrained facial video clips, with each clip paired with 20 textual descriptions. This dataset aims to advance research on facial text-to-video generation tasks, covering diverse facial attribute descriptions ranging from static to dynamic types such as appearance, actions and emotions. Its construction workflow includes data collection, processing, annotation and semi-automatic text generation, which ensures a high degree of alignment between the textual descriptions and corresponding videos. This dataset is applicable to developing and evaluating state-of-the-art models for facial text-to-video generation, addressing the problem of insufficient high-quality and relevant textual descriptions in video generation research.
提供机构:
新加坡南洋理工大学S-Lab
创建时间:
2023-03-26
搜集汇总
数据集介绍
构建方式
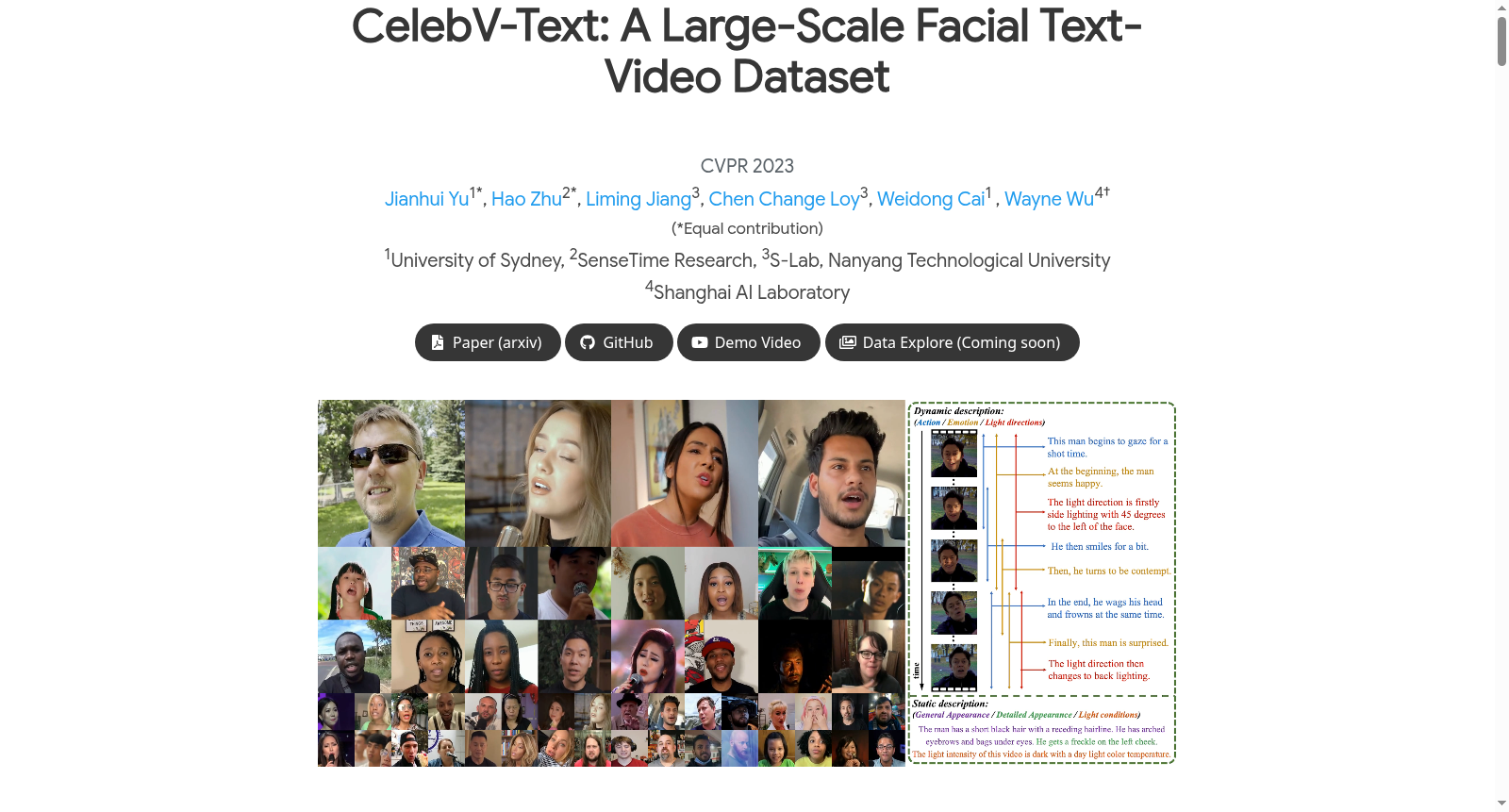
在面部文本-视频生成领域,高质量数据集的构建面临视频样本采集与文本描述关联性的双重挑战。CelebV-Text通过精心设计的数据构建流程应对这些挑战,其构建过程涵盖数据收集与处理、数据标注以及半自动文本生成三个核心环节。数据收集阶段借鉴CelebV-HQ的有效策略,从开放世界检索包含丰富面部属性与动态状态变化的人脸视频,并过滤低分辨率、短时长及重复样本。视频处理环节优化了剪辑策略,通过避免分辨率重采样以保持视频质量,并依据背景变化进行视频分割,从而提升时序连贯性。数据标注方面,该数据集系统性地定义了静态与动态属性:静态属性涵盖一般外观、细节外观及光照条件;动态属性则包括动作、情感与光照方向,且所有动态属性均带有密集的时间戳标注。标注过程结合自动与人工方法,对可自动标注的属性采用准确率超过85%的算法,其余属性则由训练有素的人工标注员完成,确保了标注的精确性与一致性。
特点
CelebV-Text作为大规模面部文本-视频数据集,其显著特点体现在规模、质量与多样性三个维度。该数据集包含70,000个野外采集的人脸视频片段,总时长约279小时,每个视频均配有20条文本描述,总计1,400,000条,形成了丰富的文本-视频对资源。视频样本分辨率均不低于512×512,其中超过半数达到1024×512以上,通过优化的处理流程保障了高视觉质量。在属性覆盖上,CelebV-Text超越了现有数据集,不仅包含40类一般外观属性,还引入了细节外观(如痣、雀斑)、光照条件以及动态的动作、情感与光照方向属性,实现了对面部视频静态特征与时序变化的全面描述。文本描述通过半自动模板生成策略,结合概率上下文无关语法与同义词替换,确保了语言的自然性、多样性与复杂性,使其在词汇丰富度与句法结构上均表现出色。
使用方法
CelebV-Text专为促进面部文本-视频生成研究而设计,其使用方法紧密围绕模型训练、评估与基准测试展开。研究人员可利用该数据集训练生成模型,如基于文本的面部视频合成模型,通过输入描述静态与动态属性的文本,生成与之对应的高质量人脸视频。数据集中提供的密集时间戳标注支持对时序动态的精细建模,例如情感变化或头部动作的连贯生成。在评估方面,该数据集支持多种量化指标,包括FVD(视频时序一致性)、FID(帧质量)与CLIPSIM(文本-视频相关性),可用于系统性地衡量生成模型的性能。此外,CelebV-Text还构建了面部文本-视频生成的基准测试,整合了代表性方法在不同文本描述场景下的性能比较,为领域内标准化评估提供了框架。数据集所有标注、视频链接与处理工具均公开,便于后续研究进行复现与拓展。
背景与挑战
背景概述
CelebV-Text数据集由悉尼大学、商汤科技、南洋理工大学S-Lab及上海人工智能实验室的研究团队于2023年联合创建,旨在解决人脸中心文本到视频生成领域的数据匮乏问题。该数据集包含70,000个高质量野外人脸视频片段及140万条文本描述,覆盖静态外观、动态动作、情感变化及光照条件等多维度属性。其核心研究在于通过半自动文本生成策略构建高相关性文本-视频对,推动生成模型在面部细节与时间动态建模方面的进展,为计算机视觉与图形学领域的可控视频合成提供了关键数据基础。
当前挑战
CelebV-Text面临的挑战主要体现在两方面:其一,在领域问题层面,人脸文本到视频生成需克服生成视频质量低、文本与视频内容相关性弱等难题,现有方法常因缺乏精准的时空对齐描述而难以建模细微的面部动态变化;其二,在数据集构建过程中,需平衡视频采集的规模与质量,确保自然分布与运动平滑性,同时设计兼顾多样性、自然度与相关性的文本标注方案,避免自动生成文本的机械性与人工标注的高成本局限。
常用场景
经典使用场景
在计算机视觉与多媒体生成领域,CelebV-Text数据集为面部文本到视频生成任务提供了关键支持。该数据集通过结合高分辨率视频片段与精细的文本描述,成为训练生成对抗网络和扩散模型等先进算法的核心资源。其经典应用场景包括基于文本描述生成具有特定静态属性(如发型、配饰)和动态行为(如表情变化、头部运动)的面部视频,推动了可控视频合成技术的发展。
实际应用
在实际应用中,CelebV-Text为虚拟角色生成、个性化视频内容创作以及增强现实中的面部动画合成提供了数据支撑。例如,在影视制作或游戏开发中,可通过文本指令快速生成符合特定外观与行为特征的面部视频序列。此外,该数据集还可用于开发深伪检测工具,通过提供高质量的真实数据以训练鉴别模型,助力应对数字内容安全挑战。
衍生相关工作
基于CelebV-Text数据集,研究者们已衍生出多项经典工作,如MMVID模型的改进版本MMVID-interp,通过文本插值技术提升了动态属性生成的时序连贯性。同时,该数据集被广泛用于构建面部文本到视频生成的基准测试,推动了TFGAN、CogVideo等模型在面部领域的性能评估与优化。这些工作进一步拓展了文本驱动视频编辑、细粒度面部属性控制等研究方向。
以上内容由遇见数据集搜集并总结生成


