MAmmoTH-VL-Instruct-12M
收藏Hugging Face2024-12-09 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/MAmmoTH-VL/MAmmoTH-VL-Instruct-12M
下载链接
链接失效反馈官方服务:
资源简介:
MAmmoTH-VL-Instruct-12M数据集是一个用于视觉指令调优的数据集,包含1200万条数据。该数据集的创建过程包括手动数据源收集、使用多模态大型语言模型(MLLMs)和大型语言模型(LLMs)进行重写,并通过相同的MLLM进行过滤。数据集主要用于数学和科学类别的指令调优,展示了详细的逐步响应。
MAmmoTH-VL-Instruct-12M is a dataset tailored for visual instruction tuning, comprising 12 million data instances. Its development workflow includes three core stages: manual data source collection, rewriting with Multimodal Large Language Models (MLLMs) and Large Language Models (LLMs), and filtering via the same MLLMs used in the rewriting step. This dataset is primarily designed for instruction tuning tasks in the mathematics and science domains, featuring detailed step-by-step responses.
创建时间:
2024-11-30
原始信息汇总
MAmmoTH-VL-Instruct-12M
简介
MAmmoTH-VL-Instruct-12M 是一个简单且可扩展的视觉指令数据重写管道,包含三个步骤:手动数据源收集、使用MLLMs/LLMs进行重写,以及通过相同的MLLM进行过滤。该数据集展示了数学和科学类别中的详细、逐步的响应。
数据分布
MAmmoTH-VL-Instruct (12M) 的数据分布展示了项目的框架。
引用
@article{guo2024mammothvlelicitingmultimodalreasoning, title={MAmmoTH-VL: Eliciting Multimodal Reasoning with Instruction Tuning at Scale}, author={Jarvis Guo and Tuney Zheng and Yuelin Bai and Bo Li and Yubo Wang and King Zhu and Yizhi Li and Graham Neubig and Wenhu Chen and Xiang Yue}, year={2024}, eprint={2412.05237}, archivePrefix={arXiv}, primaryClass={cs.CL}, url={https://arxiv.org/abs/2412.05237}, }
搜集汇总
数据集介绍
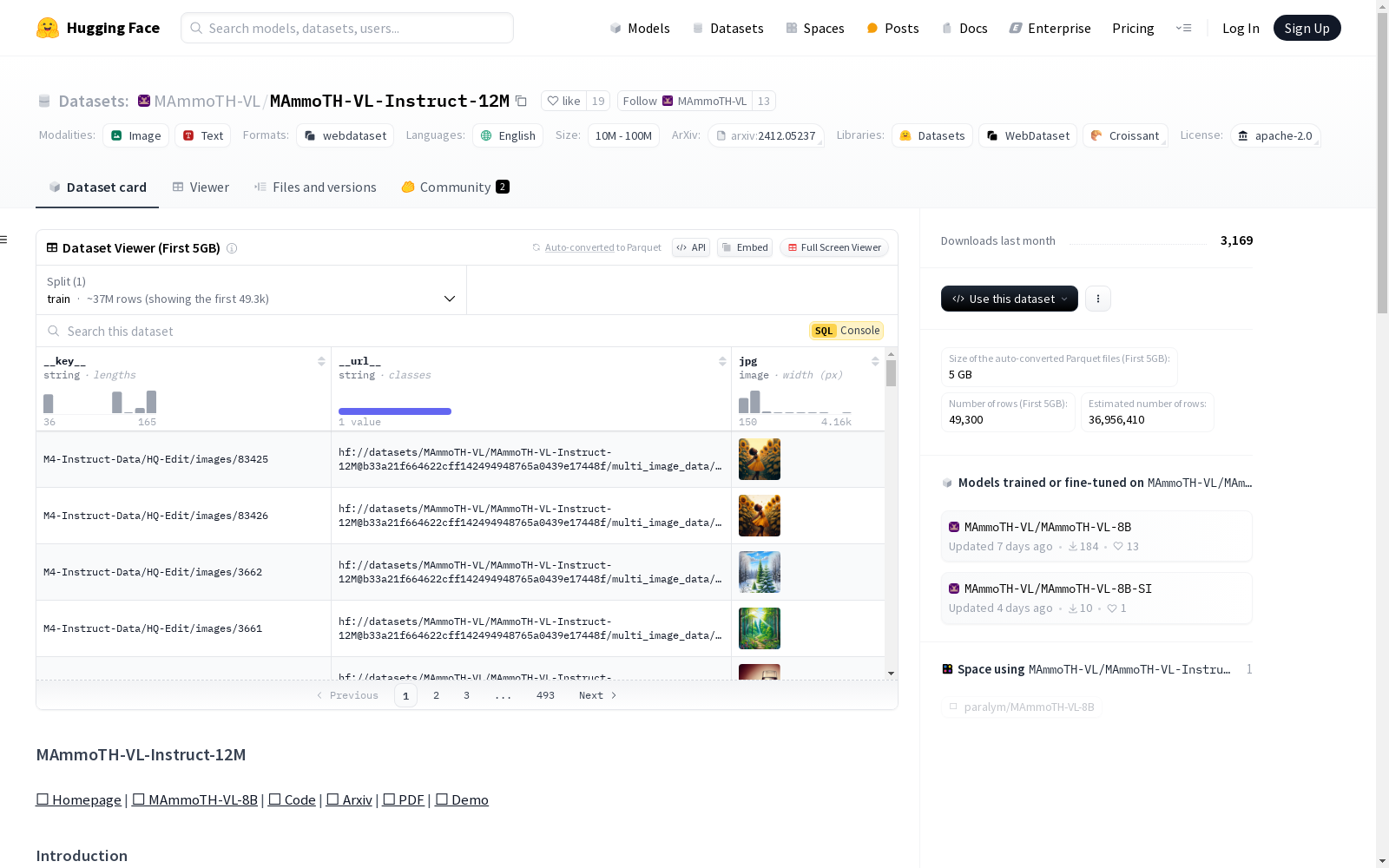
构建方式
MAmmoTH-VL-Instruct-12M数据集的构建过程采用了简单而可扩展的视觉指令数据重写管道,主要包括三个步骤:首先,通过人工收集数据源;其次,利用多模态大语言模型(MLLMs)或大语言模型(LLMs)进行数据重写;最后,通过相同的MLLM作为评判标准进行数据过滤。这一流程确保了数据集在数学和科学等领域的详细、逐步响应的指令重写质量。
特点
该数据集的显著特点在于其大规模的指令重写能力,涵盖了1200万条数据,且在多模态推理任务中表现出色。通过MLLMs/LLMs的重写和过滤机制,数据集不仅保持了高质量的指令响应,还展示了在复杂问题上的详细解答能力,特别适用于需要多步推理的科学和数学问题。
使用方法
MAmmoTH-VL-Instruct-12M数据集适用于多模态推理任务的训练和评估,尤其适合需要详细步骤解答的应用场景。用户可以通过HuggingFace平台直接访问该数据集,并结合MLLMs或LLMs进行模型训练和微调。此外,数据集的结构化指令重写方式也为研究者提供了在多模态学习领域进行深入探索的丰富资源。
背景与挑战
背景概述
MAmmoTH-VL-Instruct-12M数据集由Jarvis Guo等研究人员于2024年创建,旨在通过大规模指令调优激发多模态推理能力。该数据集的核心研究问题是如何通过视觉指令数据的重写和过滤,提升多模态语言模型(MLLMs)的推理能力。其研究背景源于多模态学习领域的快速发展,尤其是在科学和数学等复杂领域中,模型需要具备更强的推理和解释能力。MAmmoTH-VL-Instruct-12M通过手动数据源收集、重写和过滤三个步骤,构建了一个包含1200万条数据的多样化数据集,为多模态推理研究提供了重要的资源。
当前挑战
MAmmoTH-VL-Instruct-12M数据集在构建过程中面临多项挑战。首先,数据源的多样性和质量控制是关键问题,如何确保从不同领域收集的数据能够有效支持多模态推理任务是一个重要挑战。其次,重写过程中如何保持指令的准确性和一致性,同时避免引入偏差或错误,也是一项技术难题。此外,过滤步骤中使用MLLMs作为评判标准,虽然提高了数据质量,但也增加了计算复杂性和时间成本。最后,如何在大规模数据集上进行有效的指令调优,以确保模型能够泛化到未见过的任务和场景,是该数据集面临的另一大挑战。
常用场景
经典使用场景
MAmmoTH-VL-Instruct-12M数据集在视觉指令调优领域展现了其卓越的应用潜力。该数据集通过手动收集数据源、利用多模态大型语言模型(MLLMs/LLMs)进行重写,并通过同一MLLM进行过滤,形成了一个高效且可扩展的视觉指令数据重写流程。这一流程特别适用于数学和科学领域的详细、逐步响应生成,为多模态推理任务提供了丰富的训练和测试数据。
实际应用
在实际应用中,MAmmoTH-VL-Instruct-12M数据集被广泛用于开发和优化多模态智能系统。这些系统在教育、科研辅助、自动化问题解答等领域展现了强大的应用潜力。例如,在教育领域,该数据集支持的模型能够提供详细的数学和科学问题解答,极大地提升了学习效率和教学质量。
衍生相关工作
基于MAmmoTH-VL-Instruct-12M数据集,许多相关研究工作得以展开。这些工作包括但不限于多模态大型语言模型的进一步优化、视觉指令调优技术的深入研究,以及在特定领域(如数学和科学教育)中的应用探索。这些衍生工作不仅丰富了多模态学习的理论体系,还推动了相关技术的实际应用和产业化进程。
以上内容由遇见数据集搜集并总结生成


