DyCodeEval
收藏arXiv2025-03-06 更新2025-03-08 收录
下载链接:
https://codekaleidoscope.github.io/ dycodeeval.html
下载链接
链接失效反馈官方服务:
资源简介:
DyCodeEval是一个用于评估代码大型语言模型在数据污染情况下的推理能力的动态基准测试套件。该数据集通过多个代理在保持核心逻辑不变的情况下提取和修改上下文,生成语义等价的变体,旨在解决静态基准测试方案在数据污染和模型训练过程缺乏透明度的问题。DyCodeEval能够生成多样化的编程问题集,确保在数据污染风险下的评估一致性可靠性。
DyCodeEval is a dynamic benchmark suite for evaluating the reasoning capabilities of large code language models (LLMs) under data contamination scenarios. This dataset generates semantically equivalent variants by extracting and modifying contextual information while preserving core logic via multiple agents, aiming to resolve the lack of transparency in static benchmark schemes during data contamination and model training processes. DyCodeEval can generate diverse sets of programming problems, ensuring consistent and reliable evaluation under the risk of data contamination.
提供机构:
哥伦比亚大学
创建时间:
2025-03-06
搜集汇总
数据集介绍
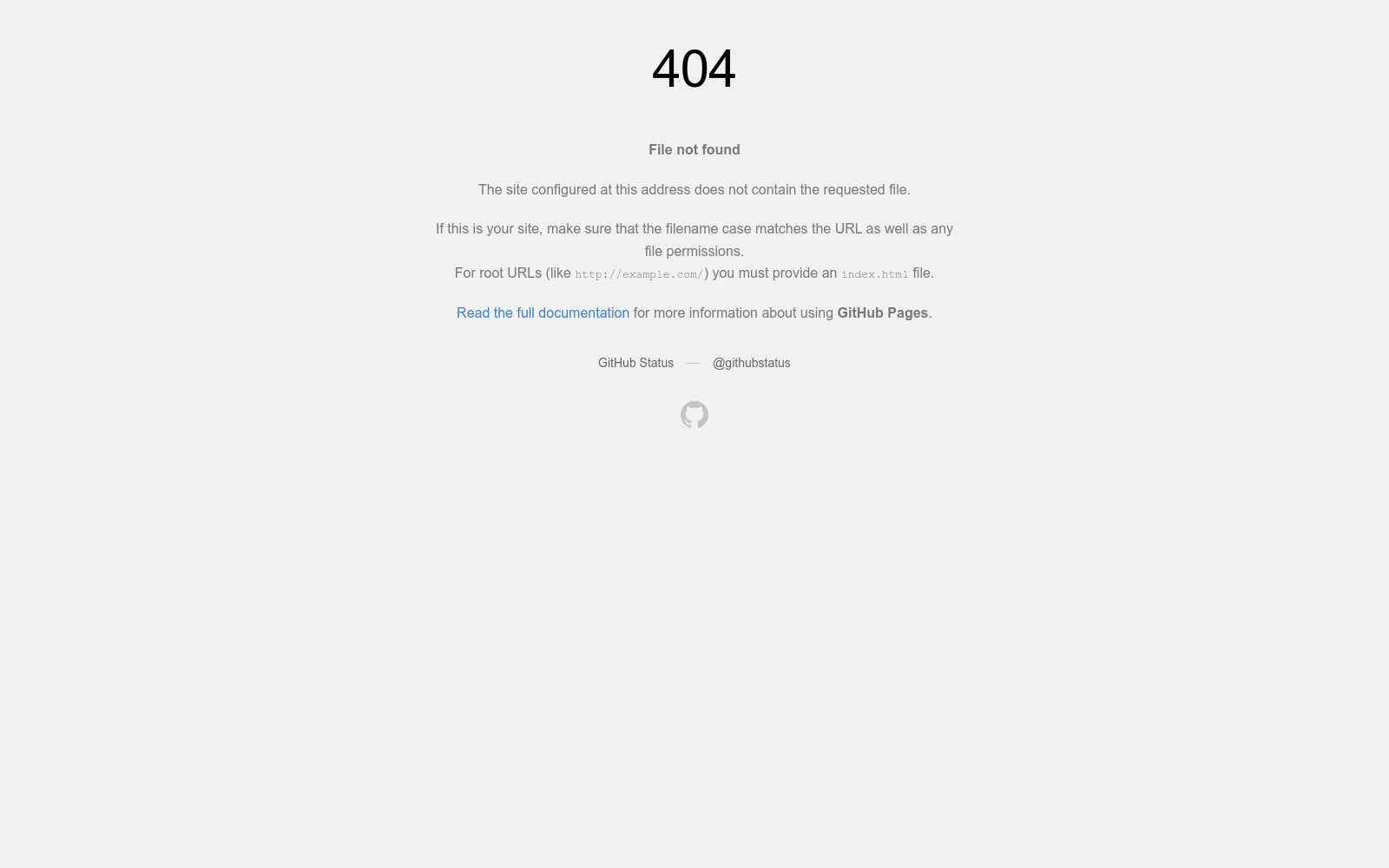
构建方式
DyCodeEval通过引入多个智能体来动态地生成编程问题,从而为代码大型语言模型(LLMs)提供一个动态的基准测试套件。首先,DyCodeEval从一个种子编程问题出发,然后使用多个智能体提取和修改上下文,生成语义等价的变化。这种方法可以有效地评估LLMs在潜在数据污染下的推理能力,同时生成多样化的问题集,以确保评估的一致性和可靠性。
特点
DyCodeEval数据集的特点在于其动态性和多样性。它通过修改编程问题的上下文来生成语义等价的变化,而不会改变问题的核心逻辑。这种设计使得DyCodeEval能够有效地评估LLMs在潜在数据污染下的推理能力,同时生成多样化的编程问题,以确保评估的一致性和可靠性。
使用方法
DyCodeEval的使用方法主要包括以下几个步骤:首先,选择一个种子编程问题;其次,使用DyCodeEval的智能体来提取和修改问题的上下文,生成语义等价的变化;然后,使用这些变化的问题来评估LLMs的推理能力;最后,根据评估结果来改进LLMs。DyCodeEval的使用可以有效地评估LLMs在潜在数据污染下的推理能力,同时生成多样化的编程问题,以确保评估的一致性和可靠性。
背景与挑战
背景概述
代码大型语言模型(LLMs)的快速发展凸显了对评估其推理能力有效性和透明性的需求。然而,现有的基准评估方法严重依赖于公开可用的、由人类创建的数据集。这些固定基准数据集的广泛使用使得基准评估过程变得静态,因此特别容易受到数据污染的影响——这是用于训练代码LLMs的广泛数据收集过程的不可避免结果。现有解决数据污染的方法通常受限于人类努力,并且问题复杂性不平衡。为了应对这些挑战,我们提出了DyCodeEval,这是一个新颖的基准评估套件,用于评估在潜在数据污染下代码LLMs的推理能力。给定一个种子编程问题,DyCodeEval采用多个代理来提取和修改上下文,而不改变其核心逻辑,从而生成语义等价的变体。我们引入了动态数据生成方法,并在两个种子数据集上对21个代码LLMs进行了实证研究。结果表明,DyCodeEval在污染风险下有效地评估了推理能力,同时生成了多样化的问题集,以确保一致和可靠的评估。我们的项目网页可以在此链接找到。
当前挑战
现有的代码LLMs基准评估套件由于静态的基准评估模式而不足,这可能导致来自意外数据爬取的数据污染。研究表明,这种污染可能已经存在于当前的LLMs中。尽管一些方法旨在为代码LLMs提供无污染的基准评估,但它们仍然依赖于手动努力。为了应对这一局限性,我们旨在开发一种自动化的方法来动态评估代码LLMs。然而,设计这样的方法提出了两个关键挑战:(1)生成语义多样化且复杂性可控的问题;(2)提供全面的基准评估。一个合适的基准编程问题必须包括细粒度的测试用例和规范解决方案,以严格评估正确性。为了应对这些挑战,我们从软件测试中广泛使用的方法——变形测试中汲取灵感,这是一种解决自动测试中的 oracle 问题。在我们的情况下,我们利用变形测试的原理来自动化全面的基准评估。具体来说,我们定义了编程问题的变形关系。一个编程问题包括与复杂性相关的算法抽象和与复杂性无关的上下文描述。修改与复杂性无关的上下文描述会改变问题的语义,而不改变其固有的复杂性。基于这种关系,DyCodeEval采用基于LLM的代理为种子问题生成多样化的上下文,自动将现有问题转换为语义多样化但复杂性保持不变的版本。此外,DyCodeEval集成了一个验证代理作为概率性oracle,以验证新生成问题的正确性和一致性,确保可靠性。
常用场景
经典使用场景
在评估代码大型语言模型(Code LLMs)的推理能力时,DyCodeEval数据集被广泛采用。它通过动态生成与原始问题语义等价但复杂度控制的问题变体,有效地避免了数据污染问题。DyCodeEval适用于评估Code LLMs在数据污染环境下的推理能力,确保了评估的透明性和可靠性。
解决学术问题
DyCodeEval解决了现有静态基准测试方案在评估Code LLMs推理能力方面的不足,特别是当数据污染发生时。它通过自动化的方法动态生成问题变体,减少了手动输入的需求,并确保了生成的问题在语义上与原始问题等价,从而为模型开发者提供了更有意义的改进方向。
衍生相关工作
基于DyCodeEval的研究成果,衍生出了一些相关的经典工作,如LiveCodeBench和PPM等。这些工作都试图为Code LLMs提供无污染的基准测试,但仍然存在一些局限性,如手动输入需求大、语义复杂度不平衡等。DyCodeEval通过动态生成问题变体的方法,有效地解决了这些问题,为Code LLMs的基准测试提供了新的思路。
以上内容由遇见数据集搜集并总结生成


