MANIPUR-MEITEILON-TTS
收藏Hugging Face2025-07-26 更新2025-07-27 收录
下载链接:
https://huggingface.co/datasets/DayanandaThokchom/MANIPUR-MEITEILON-TTS
下载链接
链接失效反馈官方服务:
资源简介:
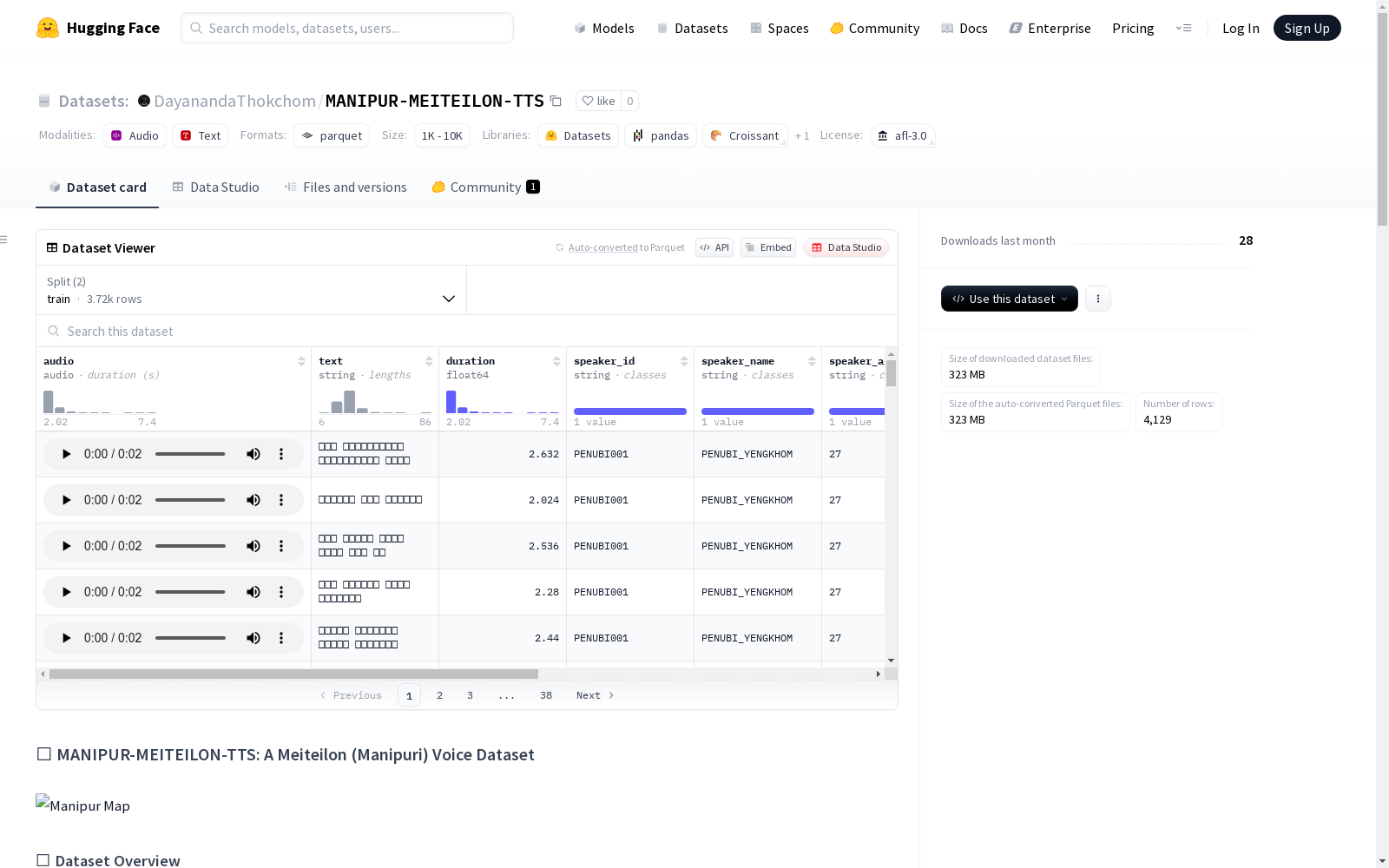
MANIPUR-MEITEILON-TTS是一个由 Manipuri(Meiteilon)母语者收集的干净且注释良好的文本到语音(TTS)数据集。该数据集是开源N7Lab计划的一部分,旨在保存东北印度低资源语言。数据集包含4129个样本,每个样本的时长范围大约为2.5秒到8秒,总时长约5.2小时,数据格式为.wav和.parquet。所有样本均由单个女性说话者录制,并且经过了手动清理验证。数据集分为训练集和测试集,包含音频波形、文本转录、样本时长、说话人ID、说话人姓名、说话人年龄、说话人城市、语言代码和验证状态等特征。
创建时间:
2025-07-26
原始信息汇总
MANIPUR-MEITEILON-TTS 数据集概述
📌 基本信息
- 数据集名称: MANIPUR-MEITEILON-TTS
- 语言: Meiteilon (Manipuri)
- ISO 639-3代码:
mni - 语系: 汉藏语系
- 地区: 印度东北部曼尼普尔邦
- 脚本: Meitei Mayek (ꯃꯤꯇꯩ ꯃꯌꯦꯛ)、孟加拉文、拉丁文
- 许可证: CC BY 4.0
📊 数据集统计
- 总样本数: 4,129
- 训练集样本数: 3,716
- 测试集样本数: 413
- 总时长: ≈5.2小时
- 单样本时长范围: ~2.5秒 – 8.0秒
- 格式:
.wav+.parquet - 采样率: 16kHz
� 数据集结构
- 特征:
audio: 音频波形及路径信息text: Meitei Mayek文本转录duration: 样本时长(秒)speaker_id: 说话者唯一标识符speaker_name: 说话者姓名speaker_age: 说话者年龄(可选)speaker_city: 说话者所在城市(如Imphal)language: 语言代码(mni-Mtei)verified: 是否经过人工验证(True/False)
🧑🎤 说话者信息
- 说话者数量: 1(女性)
- 说话者特点: 自然表达、语境多样
🚀 使用示例
python from datasets import load_dataset
dataset = load_dataset("DayanandaThokchom/MANIPUR-MEITEILON-TTS", split="train") sample = dataset[0] print(sample["text"]) sample["audio"] # 在HF Hub上自动播放
🎯 应用场景
- TTS模型训练(VITS、Tacotron2、FastSpeech2)
- 多语言ASR + TTS流水线
- 脚本到语音实验
- 濒危语言技术研究
- 口音和韵律建模
🤝 引用
bibtex @misc{manipur2025tts, title = {MANIPUR-MEITEILON-TTS: A Voice Dataset for Manipuri (Meiteilon) TTS Research}, author = {Thokchom Dayananda, N7Lab}, year = {2025}, publisher = {Hugging Face Datasets} }
🌏 背景信息
- 目的: 通过AI为当地社区提供数字工具,使其声音被听到
- 发起方: N7Lab(印度东北部AI计划)
搜集汇总
数据集介绍
构建方式
在语言资源稀缺的背景下,MANIPUR-MEITEILON-TTS数据集通过系统化采集曼尼普尔邦(印度东北部)母语者的语音数据构建而成。该数据集采用标准化流程,由单一女性发音人录制4129条语音样本,每条样本时长严格控制在2.5至8秒区间,并以16kHz采样率保存为WAV格式。所有文本转录均使用梅泰文(Meitei Mayek)书写系统标注,并经过人工校验确保准确性,最终以Apache Parquet格式组织训练集(3716条)与测试集(413条)的分割。
使用方法
研究者可通过Hugging Face数据集库直接加载该资源,标准接口支持自动解析音频与文本字段。典型应用场景包括:基于VITS或FastSpeech2框架的语音合成模型训练、濒危语言数字保护项目、以及跨文字系统的语音合成研究。数据加载时自动划分的训练/测试集便于快速验证模型性能,而内置的发音人元数据则为语音风格迁移等进阶研究提供支持。使用示例代码已明确展示如何访问音频波形和对应文本转录,确保研究可复现性。
背景与挑战
背景概述
MANIPUR-MEITEILON-TTS数据集由N7Lab团队于2025年发布,旨在为印度东北部曼尼普尔邦的梅泰语(Meiteilon)提供高质量的文本转语音(TTS)研究资源。该数据集由Thokchom Dayananda主导构建,收录了单一女性母语者的4129条语音样本,总时长约5.2小时,采用16kHz采样的.wav格式及标准化文本标注。作为濒危语言技术研究的重要载体,数据集严格遵循ISO 639-3语言编码标准(mni),涵盖梅泰文(Meitei Mayek)、孟加拉文和拉丁文三种文字体系,为汉藏语系低资源语言的数字化保护提供了范式。其学术价值体现在推动跨脚本语音合成、韵律建模等前沿研究,并支持VITS、Tacotron2等主流TTS模型的训练。
当前挑战
该数据集面临的核心挑战体现在两个维度:在领域问题层面,梅泰语作为使用者不足200万的低资源语言,存在方言变体复杂、标注专家稀缺等问题,导致跨方言泛化性研究和多说话人建模难以开展;在构建过程中,团队需克服母语者地域分布集中导致的声学多样性不足,以及非标准文字转写(如拉丁化梅泰文)与音素对齐的技术难题。此外,濒危语言特有的口语传统与书面语差异,要求构建者通过人工验证(verified字段)确保412条测试集样本的发音-文本严格对应,这种质量控制机制虽提升数据可靠性,却显著增加了时间与经济成本。
常用场景
经典使用场景
在语音合成技术领域,MANIPUR-MEITEILON-TTS数据集为研究者提供了高质量的曼尼普尔语(Meiteilon)语音样本。该数据集通过包含多样化的发音、语调和语境,成为训练文本到语音(TTS)模型的理想资源,尤其适用于VITS、Tacotron2和FastSpeech2等先进模型的开发与优化。
解决学术问题
该数据集有效解决了低资源语言在语音合成研究中数据匮乏的难题。曼尼普尔语作为一种濒危语言,其数字化工具的开发长期受限。通过提供经过人工验证的语音样本,该数据集不仅支持语言技术的学术研究,还为保护和传承这一文化遗产提供了技术基础。
实际应用
在实际应用中,MANIPUR-MEITEILON-TTS数据集被广泛应用于开发多语言语音助手、教育工具和本地化服务。例如,基于该数据集训练的TTS模型可用于曼尼普尔地区的公共服务、媒体内容生成以及语言学习应用,显著提升了当地社区的数字包容性。
数据集最近研究
最新研究方向
随着全球对低资源语言保护意识的增强,MANIPUR-MEITEILON-TTS数据集的推出为梅泰语(Manipuri)的语音合成研究提供了重要资源。该数据集不仅填补了梅泰语在语音技术领域的空白,还为跨语言语音合成和低资源语言处理提供了新的研究视角。当前,前沿研究主要集中在利用该数据集开发高效的端到端语音合成模型,如VITS和FastSpeech2,以提升梅泰语语音合成的自然度和表现力。此外,结合多语言自动语音识别(ASR)技术,研究者们正在探索梅泰语与其他语言之间的语音转换和跨语言迁移学习。这些研究不仅推动了梅泰语在数字时代的应用,也为其他濒危语言的保护和技术开发提供了借鉴。
以上内容由遇见数据集搜集并总结生成


