有没有相关的论文或文献参考?
这个数据集是基于什么背景创建的?
数据集的作者是谁?
能帮我联系到这个数据集的作者吗?
这个数据集如何下载?
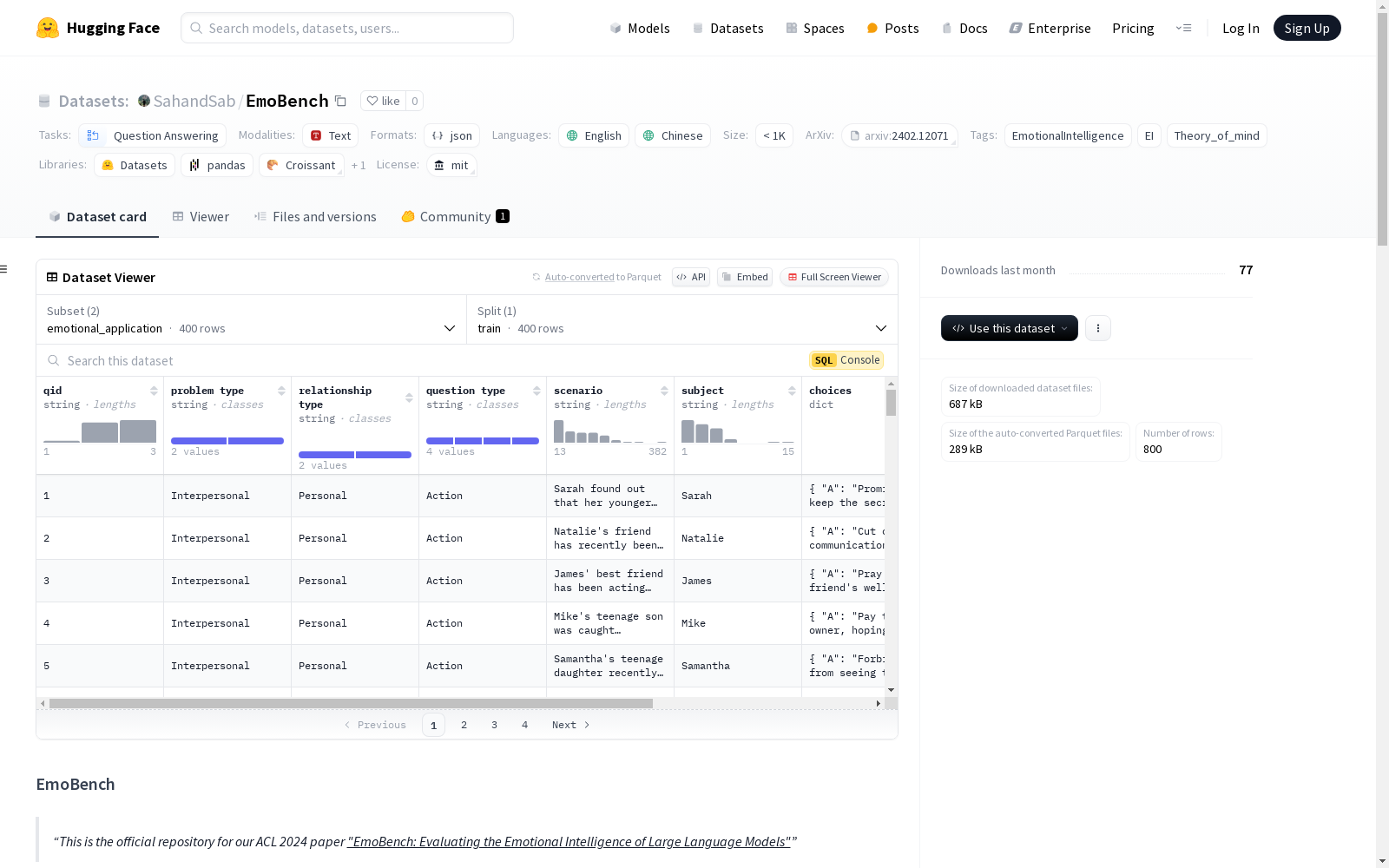
EmoBench 是一个综合且具有挑战性的基准测试,旨在评估大型语言模型(LLMs)的情感智能(EI)。该数据集不仅关注情感识别,还涵盖了情感推理和应用等高级情感智能能力。
数据集包含 400 个手工制作的场景,分为两个主要评估任务:
有关评估代码,请访问 GitHub 仓库。
如果该数据集对您的研究有用,请引用以下论文:
@inproceedings{sabour-etal-2024-emobench, title = "{E}mo{B}ench: Evaluating the Emotional Intelligence of Large Language Models", author = "Sabour, Sahand and Liu, Siyang and Zhang, Zheyuan and Liu, June and Zhou, Jinfeng and Sunaryo, Alvionna and Lee, Tatia and Mihalcea, Rada and Huang, Minlie", editor = "Ku, Lun-Wei and Martins, Andre and Srikumar, Vivek", booktitle = "Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)", month = aug, year = "2024", address = "Bangkok, Thailand", publisher = "Association for Computational Linguistics", url = "https://aclanthology.org/2024.acl-long.326", doi = "10.18653/v1/2024.acl-long.326", pages = "5986--6004", abstract = "Recent advances in Large Language Models (LLMs) have highlighted the need for robust, comprehensive, and challenging benchmarks. Yet, research on evaluating their Emotional Intelligence (EI) is considerably limited. Existing benchmarks have two major shortcomings: first, they mainly focus on emotion recognition, neglecting essential EI capabilities such as emotion management and thought facilitation through emotion understanding; second, they are primarily constructed from existing datasets, which include frequent patterns, explicit information, and annotation errors, leading to unreliable evaluation. We propose EmoBench, a benchmark that draws upon established psychological theories and proposes a comprehensive definition for machine EI, including Emotional Understanding and Emotional Application. EmoBench includes a set of 400 hand-crafted questions in English and Chinese, which are meticulously designed to require thorough reasoning and understanding. Our findings reveal a considerable gap between the EI of existing LLMs and the average human, highlighting a promising direction for future research. Our code and data are publicly available at https://github.com/Sahandfer/EmoBench.", }
中国食物成分数据库
食物成分数据比较准确而详细地描述农作物、水产类、畜禽肉类等人类赖以生存的基本食物的品质和营养成分含量。它是一个重要的我国公共卫生数据和营养信息资源,是提供人类基本需求和基本社会保障的先决条件;也是一个国家制定相关法规标准、实施有关营养政策、开展食品贸易和进行营养健康教育的基础,兼具学术、经济、社会等多种价值。 本数据集收录了基于2002年食物成分表的1506条食物的31项营养成分(含胆固醇)数据,657条食物的18种氨基酸数据、441条食物的32种脂肪酸数据、130条食物的碘数据、114条食物的大豆异黄酮数据。
国家人口健康科学数据中心 收录
中国1km分辨率逐月降水量数据集(1901-2023)
该数据集为中国逐月降水量数据,空间分辨率为0.0083333°(约1km),时间为1901.1-2023.12。数据格式为NETCDF,即.nc格式。该数据集是根据CRU发布的全球0.5°气候数据集以及WorldClim发布的全球高分辨率气候数据集,通过Delta空间降尺度方案在中国降尺度生成的。并且,使用496个独立气象观测点数据进行验证,验证结果可信。本数据集包含的地理空间范围是全国主要陆地(包含港澳台地区),不含南海岛礁等区域。为了便于存储,数据均为int16型存于nc文件中,降水单位为0.1mm。 nc数据可使用ArcMAP软件打开制图; 并可用Matlab软件进行提取处理,Matlab发布了读入与存储nc文件的函数,读取函数为ncread,切换到nc文件存储文件夹,语句表达为:ncread (‘XXX.nc’,‘var’, [i j t],[leni lenj lent]),其中XXX.nc为文件名,为字符串需要’’;var是从XXX.nc中读取的变量名,为字符串需要’’;i、j、t分别为读取数据的起始行、列、时间,leni、lenj、lent i分别为在行、列、时间维度上读取的长度。这样,研究区内任何地区、任何时间段均可用此函数读取。Matlab的help里面有很多关于nc数据的命令,可查看。数据坐标系统建议使用WGS84。
国家青藏高原科学数据中心 收录
Breast Cancer Dataset
该项目专注于清理和转换一个乳腺癌数据集,该数据集最初由卢布尔雅那大学医学中心肿瘤研究所获得。目标是通过应用各种数据转换技术(如分类、编码和二值化)来创建一个可以由数据科学团队用于未来分析的精炼数据集。
github 收录
Ansh007/Jellyfish-Image-Dataset
该数据集包含900张水母图像,分为六个不同的类别和物种:紫水母、月亮水母、桶水母、蓝水母、罗盘水母和狮鬃水母。这些图像可用于机器学习技术,以获得水母分类、物种识别和颜色分析的洞察。每个物种都有详细的描述,包括其特征和食物来源。此外,数据集还提供了使用案例,如水母分类、物种识别和颜色分析。
hugging_face 收录
CliMedBench
CliMedBench是一个大规模的中文医疗大语言模型评估基准,由华东师范大学等机构创建。该数据集包含33,735个问题,涵盖14个核心临床场景,主要来源于顶级三级医院的真实电子健康记录和考试练习。数据集的创建过程包括专家指导的数据选择和多轮质量控制,确保数据的真实性和可靠性。CliMedBench旨在评估和提升医疗大语言模型在临床决策支持、诊断和治疗建议等方面的能力,解决医疗领域中模型性能评估的不足问题。
arXiv 收录