ywxia/fold_combined_gt
收藏Hugging Face2026-04-10 更新2026-04-12 收录
下载链接:
https://hf-mirror.com/datasets/ywxia/fold_combined_gt
下载链接
链接失效反馈官方服务:
资源简介:
---
license: apache-2.0
task_categories:
- robotics
tags:
- LeRobot
- custom_eef
configs:
- config_name: default
data_files: data/*/*.parquet
---
This dataset was created using [LeRobot](https://github.com/huggingface/lerobot).
## Dataset Description
## Data Distribution Overview

This figure summarizes the data distribution of the **ywxia/fold_combined_gt** dataset, auto-generated after each conversion via `analysis/postprocess_with_overview.py`. It shows episode-length distribution, the 3-D EEF workspace, per-dimension state histograms, per-arm action magnitudes, and a sample of frames from each camera.
**Task:** fold the box on the desk
**Episodes:** 333 | **Frames:** 57490 | **FPS:** 15 | **Robot:** custom_eef
## Gripper Data Distribution
Raw exported action-space gripper channels:
| Arm | Action dim | Mean | Std | Min | Max | Median | P99 | Exact zero |
| --- | ---: | ---: | ---: | ---: | ---: | ---: | ---: | ---: |
| left | 6 | 1.0000 | 0.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 0.0% |
| right | 13 | 1.0000 | 0.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 0.0% |
These numbers are computed from the raw dataset action channels before any ACT delta or rot6d transforms.
- **Homepage:** [More Information Needed]
- **Paper:** [More Information Needed]
- **License:** apache-2.0
## Dataset Structure
[meta/info.json](meta/info.json):
```json
{
"codebase_version": "v2.1",
"robot_type": "custom_eef",
"total_episodes": 333,
"total_frames": 57490,
"total_tasks": 1,
"total_videos": 0,
"total_chunks": 1,
"chunks_size": 1000,
"fps": 15,
"splits": {
"train": "0:333"
},
"data_path": "data/chunk-{episode_chunk:03d}/episode_{episode_index:06d}.parquet",
"video_path": "videos/chunk-{episode_chunk:03d}/{video_key}/episode_{episode_index:06d}.mp4",
"features": {
"left_wrist_cam_0": {
"dtype": "image",
"shape": [
224,
224,
3
],
"names": [
"height",
"width",
"channel"
]
},
"left_wrist_cam_1": {
"dtype": "image",
"shape": [
224,
224,
3
],
"names": [
"height",
"width",
"channel"
]
},
"right_wrist_cam_0": {
"dtype": "image",
"shape": [
224,
224,
3
],
"names": [
"height",
"width",
"channel"
]
},
"right_wrist_cam_1": {
"dtype": "image",
"shape": [
224,
224,
3
],
"names": [
"height",
"width",
"channel"
]
},
"state": {
"dtype": "float32",
"shape": [
7
],
"names": [
"state"
]
},
"eef_state": {
"dtype": "float32",
"shape": [
14
],
"names": [
"eef_state"
]
},
"actions": {
"dtype": "float32",
"shape": [
14
],
"names": [
"actions"
]
},
"timestamp": {
"dtype": "float32",
"shape": [
1
],
"names": null
},
"frame_index": {
"dtype": "int64",
"shape": [
1
],
"names": null
},
"episode_index": {
"dtype": "int64",
"shape": [
1
],
"names": null
},
"index": {
"dtype": "int64",
"shape": [
1
],
"names": null
},
"task_index": {
"dtype": "int64",
"shape": [
1
],
"names": null
}
}
}
```
## Citation
**BibTeX:**
```bibtex
[More Information Needed]
```
提供机构:
ywxia
搜集汇总
数据集介绍
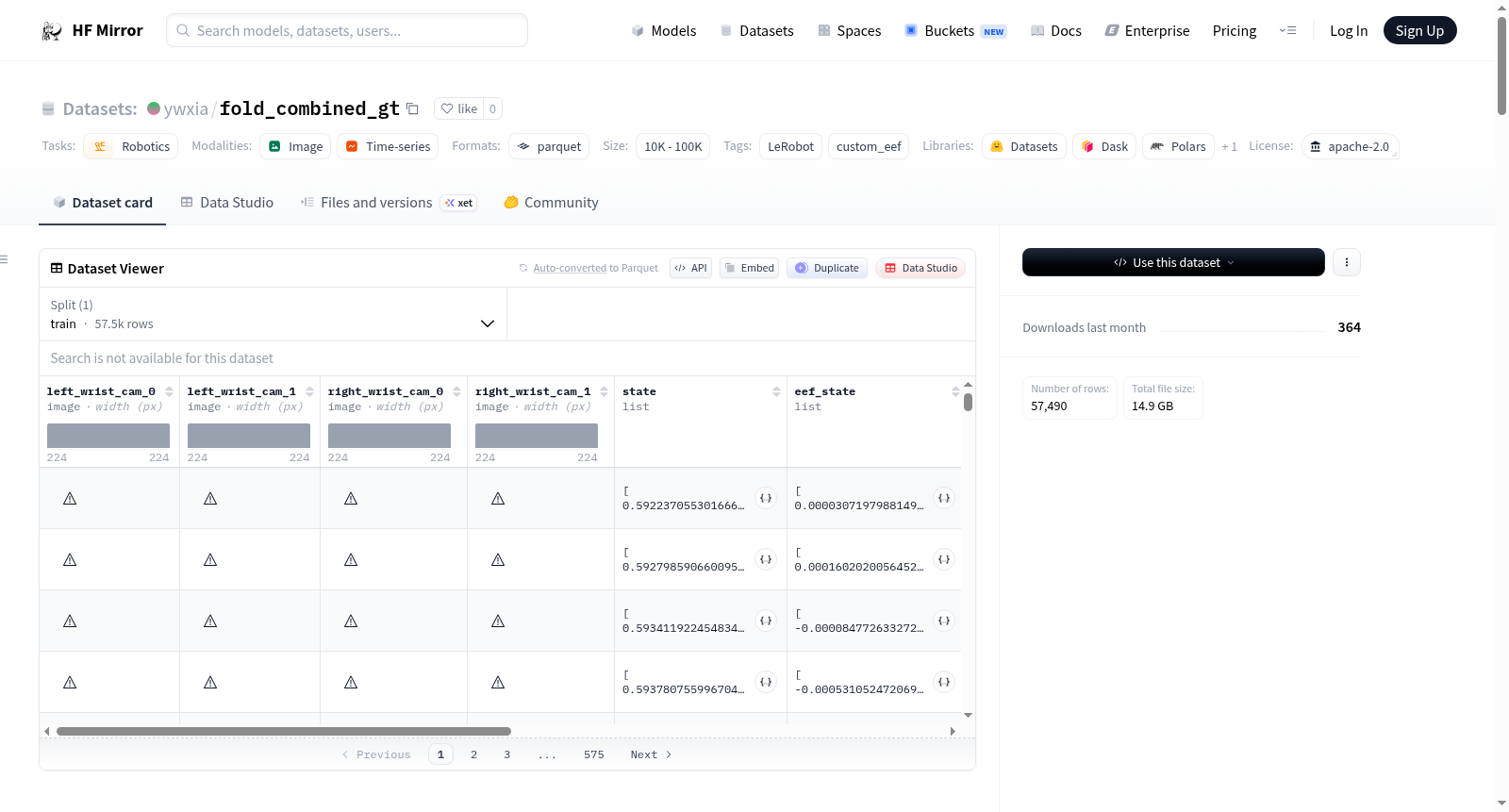
构建方式
在机器人操作领域,数据集的构建对于推动模仿学习与强化学习算法的发展至关重要。fold_combined_gt数据集依托LeRobot平台精心构建,专注于桌面折叠纸盒这一具体任务。该数据集通过采集333个完整操作片段,总计57490帧数据,并以每秒15帧的速率记录,确保了时序动作的连贯性与真实性。数据以Parquet格式存储,每个片段包含多模态信息,如左右腕部摄像头的视觉图像、机器人末端执行器状态以及精确的动作指令,这些元素共同构成了一个层次分明、结构严谨的数据集合。
特点
该数据集在机器人操作数据集中展现出鲜明的特色,其多模态融合的设计尤为突出。数据集不仅提供了高分辨率的双腕摄像头视觉流,每帧图像尺寸统一为224x224像素,还同步记录了14维的末端执行器状态与动作向量,以及7维的机器人本体状态。这种视觉与状态信息的紧密结合,为算法提供了丰富的上下文感知能力。此外,数据分布经过严格统计分析,动作通道的均值与标准差均保持稳定,确保了数据的一致性与可靠性,适用于复杂的策略学习与行为克隆研究。
使用方法
利用fold_combined_gt数据集进行机器人学习研究时,研究者可依据meta/info.json中的结构化描述轻松访问数据。数据集已预分为训练集,涵盖全部333个片段,用户可通过指定数据路径加载Parquet文件,提取视觉特征、状态序列及动作标签。该数据集兼容主流机器人学习框架,支持端到端的策略训练或视觉-动作映射模型的开发。通过分析提供的统计图表,如末端执行器工作空间分布与动作幅度直方图,研究者能够深入理解数据特性,进而优化模型架构与训练流程,推动折叠任务自主操作技术的进步。
背景与挑战
背景概述
在机器人操作领域,模仿学习与强化学习的发展亟需高质量、任务特定的真实世界交互数据集。fold_combined_gt数据集应运而生,它专注于桌面环境下的纸盒折叠任务,由Hugging Face的LeRobot项目支持构建。该数据集收录了333个完整操作序列,包含超过5.7万帧的多模态数据,融合了双腕部摄像头视觉信息、机器人末端执行器状态及精确动作指令。其核心研究问题在于如何通过大规模示教数据,推动机器人对复杂灵巧操作任务的理解与泛化能力,为后续的离线强化学习与行为克隆算法提供了宝贵的实证基础。
当前挑战
fold_combined_gt数据集所针对的机器人折叠任务,本身涉及高维状态空间下的时序决策与精确的末端轨迹控制,要求模型能从视觉观察中推断物体的几何形变与物理交互。数据构建过程中,挑战主要体现在多传感器数据的精确同步与标定、长周期操作序列的连续采集稳定性,以及真实环境中动作执行误差所导致的数据噪声问题。此外,如何保证示教数据在动作空间与状态空间中的分布均匀性,避免过拟合于特定抓取姿态或折叠路径,亦是该数据集构建与使用中需克服的关键难点。
常用场景
经典使用场景
在机器人操作学习领域,fold_combined_gt数据集以其丰富的多视角视觉与状态动作序列,为模仿学习与强化学习算法提供了关键基准。该数据集聚焦于桌面环境下的纸盒折叠任务,通过双腕摄像头捕捉高分辨率图像,并同步记录末端执行器状态与动作向量,使得研究者能够训练模型从视觉输入中推断出精确的机械臂控制策略,从而在复杂操作任务中实现端到端的行为生成。
解决学术问题
该数据集有效应对了机器人学中视觉-动作映射的挑战,为解决高维观察空间下的策略优化问题提供了实证基础。通过提供大量真实世界交互数据,它支持了模仿学习中的行为克隆、离线强化学习中的价值函数估计,以及多模态感知融合方法的研究,显著促进了在非结构化环境中机器人灵巧操作能力的理论进展与实际算法验证。
衍生相关工作
围绕fold_combined_gt数据集,已衍生出一系列基于LeRobot框架的机器人学习研究。例如,利用其多摄像头视觉流进行时空特征提取的视觉编码器设计,以及结合状态-动作对训练端到端策略网络的经典工作。这些研究进一步拓展了数据驱动方法在机器人操作中的边界,为后续大规模机器人数据集构建与算法评估设立了重要参照。
以上内容由遇见数据集搜集并总结生成


