Health-Bench-Eval-OSS-2025-07
收藏Hugging Face2025-05-17 更新2025-05-18 收录
下载链接:
https://huggingface.co/datasets/Tonic/Health-Bench-Eval-OSS-2025-07
下载链接
链接失效反馈官方服务:
资源简介:
HealthBench是一个用于评估健康相关对话场景中AI系统的标准数据集,由OpenAI与全球医生合作开发,包含5000个多轮对话,对话内容涉及用户与AI模型之间的互动,并由医生制定的评分标准进行评估。数据集分为两个子集,分别为HealthBench Consensus和HealthBench Hard。
HealthBench is a benchmark dataset for evaluating AI systems in healthcare-related conversational scenarios. Developed by OpenAI in collaboration with global physicians, it contains 5000 multi-turn dialogues centered on interactions between users and AI models, with evaluations conducted using scoring criteria formulated by physicians. The dataset is divided into two subsets, namely HealthBench Consensus and HealthBench Hard.
创建时间:
2025-05-15
原始信息汇总
HealthBench数据集概述
数据集基本信息
- 名称: HealthBench
- 发布机构: OpenAI
- 发布日期: 2025年
- 许可证: MIT
- 语言: 主要英语,含49种语言的多语言提示
- 主页: https://openai.com/index/healthbench/
- 论文: HealthBench: An Evaluation for AI Systems and Human Health
- GitHub仓库: https://github.com/openai/simple-evals
数据集内容
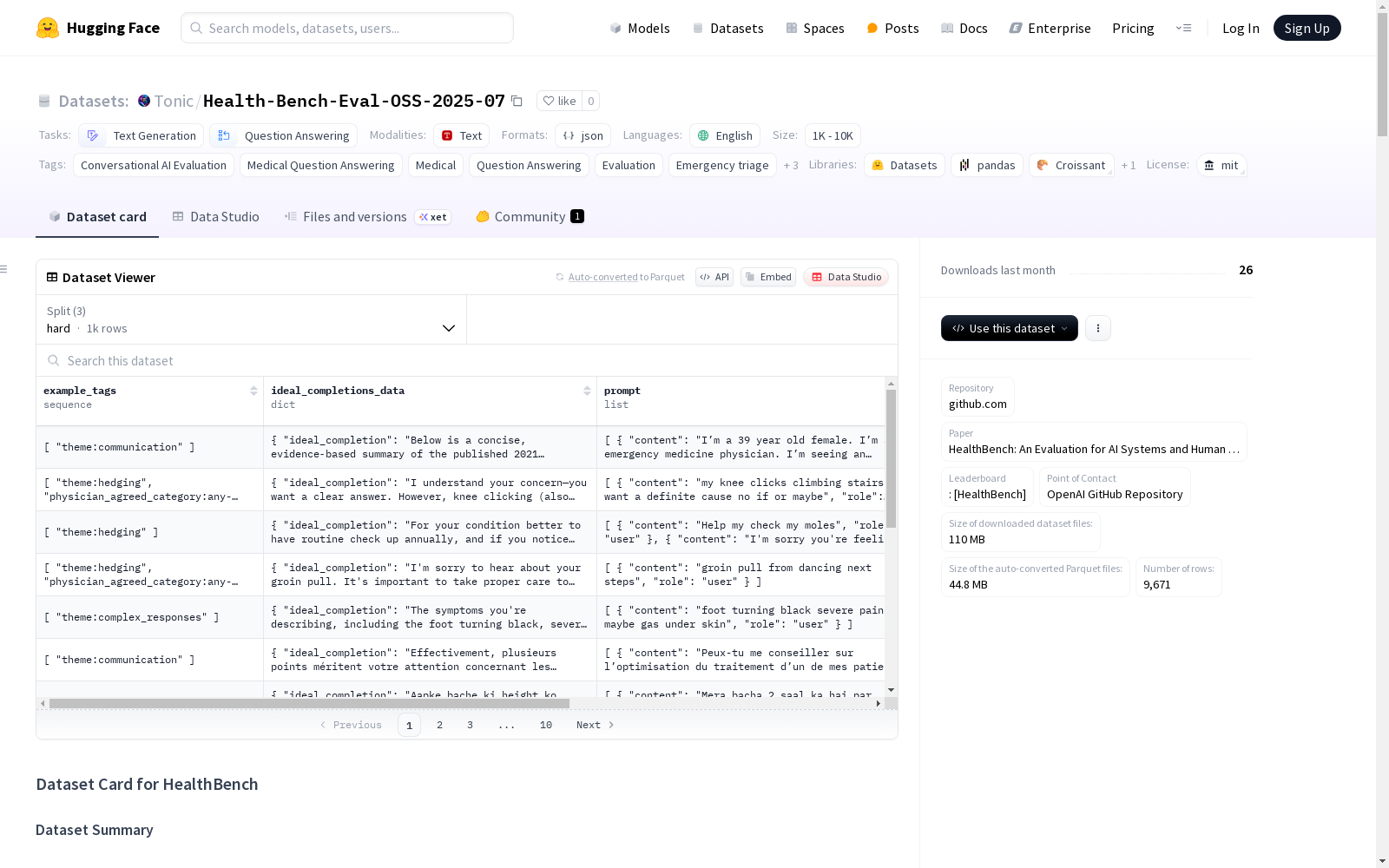
- 总实例数: 9,671(三个子集总和)
- 数据格式: JSONL
- 主要任务:
- 对话式AI评估
- 医疗问答
- 紧急分诊
- 护理升级
- 临床指南遵循
数据集结构
数据子集
| 子集名称 | 文件名称 | 实例数 | 文件大小 |
|---|---|---|---|
| oss_eval | 2025-05-07-06-14-12_oss_eval.jsonl | 5,000 | 57.47 MB |
| consensus | consensus_2025-05-09-20-00-46.jsonl | 3,671 | 35.21 MB |
| hard | hard_2025-05-08-21-00-10.jsonl | 1,000 | 12.00 MB |
数据字段
| 字段名 | 类型 | 描述 |
|---|---|---|
| example_tags | List[String] | 示例标签 |
| ideal_completions_data | Object/Null | 理想完成数据 |
| prompt | List[Object] | 对话内容 |
| prompt_id | String | 唯一标识符 |
| rubrics | List[Object] | 评估标准 |
| canary | String | 防泄漏标识 |
数据集特点
- 多轮对话: 模拟真实医患交互
- 评估标准: 48,562条独特标准
- 评估维度:
- 准确性
- 完整性
- 上下文感知
- 沟通质量
- 指令遵循
创建信息
- 合作机构: 来自60个国家的262名医师
- 数据来源: 合成生成和人类对抗测试
- 注释: 医师验证的评估标准
使用注意事项
- 社会影响: 需在医疗监督下使用
- 偏见:
- 西方医学指南偏向
- 英语语言偏向
- 限制:
- 医学场景覆盖有限
- 指南可能更新
引用信息
bibtex @article{healthbench_2025_paper, author = {OpenAI and Arora, Rahul K. and Wei, Jason and Hicks, Rebecca Soskin and others}, title = {HealthBench: A Benchmark for Evaluating Health-Related Conversational AI}, year = {2025}, publisher = {OpenAI}, url = {https://openai.com/paper/healthbench} }
bibtex @dataset{healthbench_2025_dataset, author = {OpenAI and Arora, Rahul K. and Wei, Jason and Hicks, Rebecca Soskin and others}, title = {HealthBench Dataset}, year = {2025}, publisher = {Hugging Face}, url = {https://huggingface.co/datasets/Tonic/Health-Bench-Eval-OSS-2025-07} }
模型性能
- 最佳表现模型: o3 (0.598)
- 医师基线: ~0.480
搜集汇总
数据集介绍
构建方式
HealthBench数据集由OpenAI联合来自60个国家的262名医师共同开发,旨在评估AI系统在健康相关对话场景中的表现。该数据集包含5,000个多轮健康对话,采用JSONL格式存储,模拟AI模型与用户(普通用户或临床医生)之间的交互。每个对话包括用户提示、候选模型响应以及医师制定的评分标准,共48,562条独特标准,涵盖准确性、完整性、上下文意识、沟通质量和指令遵循等多个维度。数据集分为两个子集:HealthBench Consensus(3,671个经过多重验证的示例)和HealthBench Hard(1,000个具有挑战性的示例)。数据集的构建结合了合成生成和人类对抗测试,以确保其真实性和难度。
特点
HealthBench数据集的特点在于其高度专业化和实用性。数据集涵盖了多种医疗场景,包括紧急分诊、护理升级、上下文感知响应生成、处理医学查询中的不确定性等。每个对话实例均包含详细的评分标准和理想完成数据,便于定量评估。数据集的多样性和复杂性使其成为评估AI系统在医疗领域表现的重要工具。此外,数据集还支持多语言提示,涵盖49种语言,进一步增强了其全球适用性。
使用方法
使用HealthBench数据集时,研究人员可通过加载JSONL文件获取对话实例及其评分标准。数据集支持多种任务,包括对话AI评估和医学问答。用户可根据prompt_id或example_tags创建自定义分割,以适应不同的研究需求。评估时,建议结合医师制定的评分标准,重点关注准确性、完整性和上下文意识等维度。此外,数据集的使用需遵循MIT许可证,并避免在线共享示例以防止数据泄露。
背景与挑战
背景概述
HealthBench-Eval-OSS-2025-07数据集由OpenAI联合来自60个国家的262名医师共同开发,旨在评估人工智能系统在健康相关对话场景中的表现。该数据集包含5000个多轮健康对话,模拟了AI模型与用户(包括普通人和临床医生)之间的交互。每个对话均包含用户提示、候选模型响应以及由医师制定的评估标准,涵盖准确性、完整性、情境意识、沟通质量和指令遵循等多个维度。数据集分为两个子集:HealthBench Consensus(3671个经过多重验证的示例)和HealthBench Hard(1000个具有挑战性的示例)。该数据集的开发旨在为对话式AI、医疗决策支持和医疗应用研究提供支持,特别强调安全性和可靠性。
当前挑战
HealthBench-Eval-OSS-2025-07数据集面临多方面的挑战。在领域问题方面,该数据集旨在解决医疗问答和对话式AI评估中的复杂问题,如紧急分诊、护理升级、情境感知响应生成等。这些任务要求模型具备高度的专业知识和情境理解能力,同时需处理医疗领域的不确定性和多样性。在构建过程中,数据集开发团队需克服合成数据与真实患者交互之间的差距,确保对话场景的真实性和代表性。此外,数据集的标注依赖于医师的专业判断,可能存在指南偏见(如依赖西方医疗指南)和语言偏见(以英语为主)。动态变化的医疗标准和多样化的全球医疗实践也为数据集的构建和评估带来了额外的复杂性。
常用场景
经典使用场景
在医疗对话人工智能领域,HealthBench数据集作为评估基准,主要用于测试和优化AI系统在健康相关对话场景中的表现。该数据集通过模拟真实世界中的医患交互,包括多轮对话和复杂医疗问题,为研究人员提供了丰富的测试案例。其经典使用场景包括评估AI模型在紧急分诊、护理升级和临床指南遵循等方面的能力,确保模型能够生成准确、完整且符合医学标准的回答。
实际应用
在实际应用中,HealthBench数据集被广泛用于开发和优化医疗辅助AI系统。例如,医疗机构可以利用该数据集训练模型,以提供初步的医疗建议或辅助分诊决策。此外,该数据集还能帮助开发面向患者的健康咨询工具,确保其回答符合临床指南。通过这种方式,数据集不仅提升了AI在医疗领域的实用性,还为全球范围内的医疗资源分配提供了技术支持。
衍生相关工作
围绕HealthBench数据集,已衍生出多项经典研究工作。例如,基于其评估框架,研究者开发了针对特定医疗场景的专用模型,如急诊分诊AI和心理健康辅助工具。此外,该数据集还启发了多语言医疗对话系统的研究,进一步扩展了其应用范围。这些工作不仅验证了数据集的广泛适用性,也为医疗AI的未来发展奠定了坚实基础。
以上内容由遇见数据集搜集并总结生成


