AVSpeech
收藏arXiv2025-09-30 收录
官方服务:
资源简介:
该数据集名为AVSpeech,包含了来自不同来源的数千小时视频片段,精心挑选以展现丰富多样的面部表情和头部姿势。该数据集被用于训练和测试MorphGAN模型,同时也用于评估面部识别网络对于姿势和表情变化的敏感性。其规模包括用于训练的13,000个视频子集,以及用于测试的150个视频。这项任务旨在进行面部识别及其鲁棒性评估。
This dataset, named AVSpeech, consists of thousands of hours of video clips collected from diverse sources, carefully curated to showcase a wide range of facial expressions and head poses. It has been used for training and testing the MorphGAN model, as well as for evaluating the sensitivity of facial recognition networks to variations in pose and expression. In terms of scale, it includes a 13,000-video training subset and 150 videos for testing. The task centered on this dataset focuses on facial recognition and the evaluation of its robustness.
提供机构:
AVSpeech搜集汇总
数据集介绍
背景与挑战
背景概述
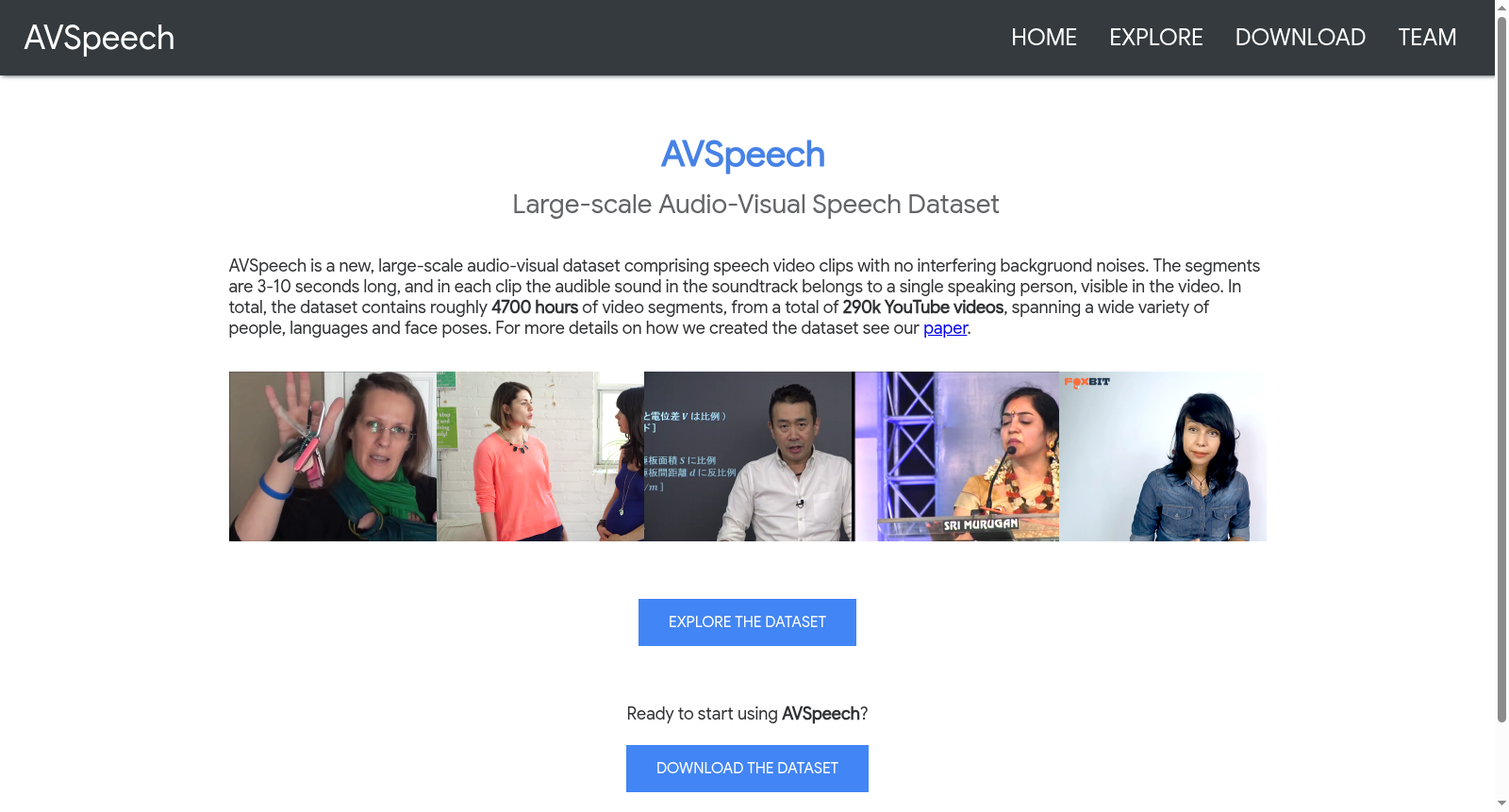
AVSpeech是一个大规模音频-视觉语音数据集,包含约4700小时、来自29万个YouTube视频的纯净语音片段,每个片段时长3-10秒且无背景噪音干扰。该数据集覆盖多样化的人物、语言和面部姿态,专门用于音频与视觉结合的语音研究。
以上内容由遇见数据集搜集并总结生成


