Sympatheia-18k
收藏Hugging Face2026-05-06 更新2026-05-07 收录
下载链接:
https://huggingface.co/datasets/anonymous2222/Sympatheia-18k
下载链接
链接失效反馈官方服务:
资源简介:
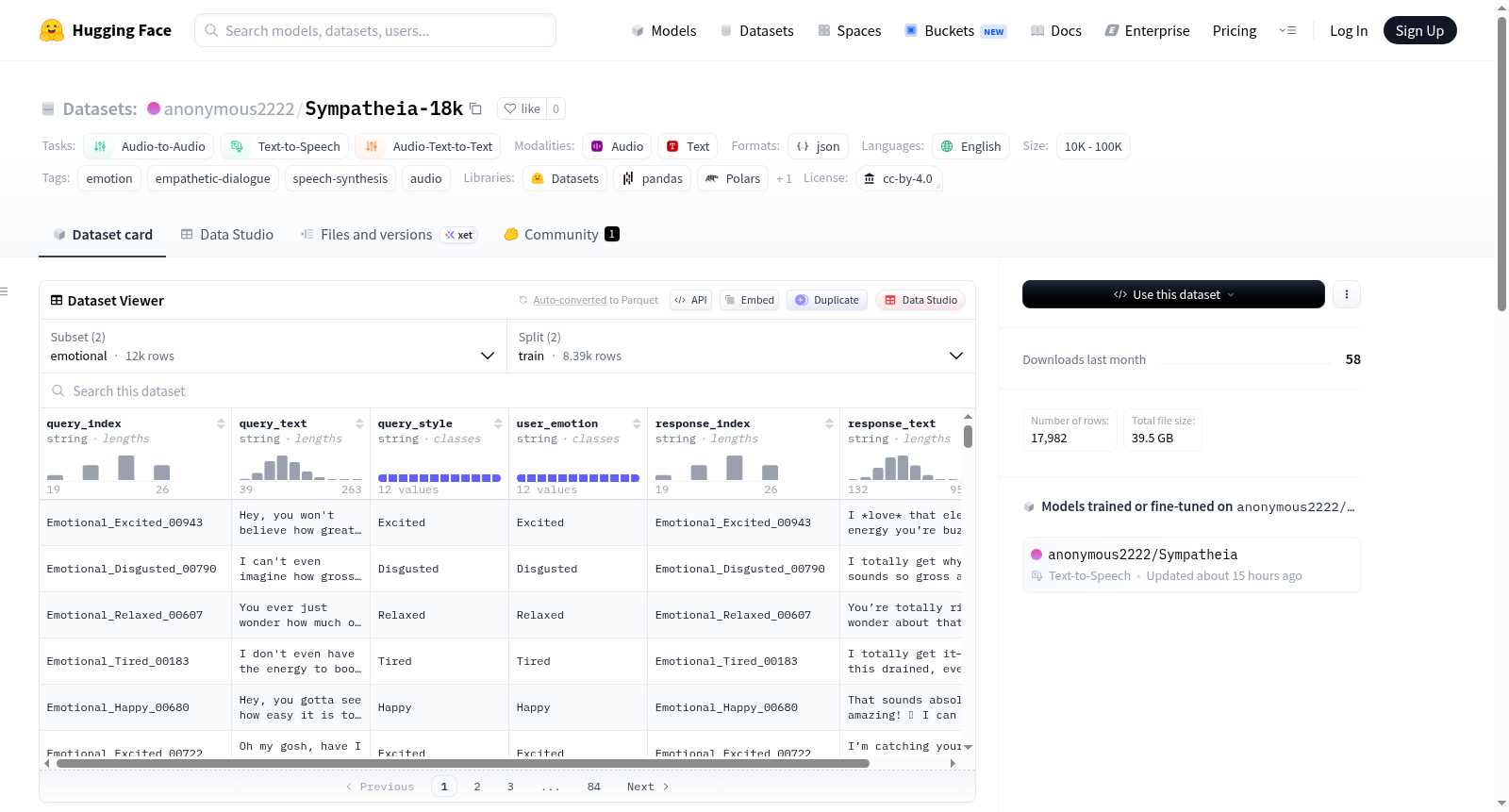
Sympatheia-18k 是一个用于共情语音合成研究的情感感知口语对话数据集。该数据集包含 18,000 个查询-响应对,涵盖 12 种情感类别,每个对都配有合成音频和文本转录。数据集分为两个子集:情感子集和中性子集。情感子集包含情感查询与情感匹配的响应,中性子集则包含中性查询,每个查询与 12 种情感目标的响应配对。数据集文件包括音频文件(WAV 格式)、元数据文件(包含文本对和情感标签的 JSONL 文件)、预编码表示文件(包含音频标记、情感标签和每个情感类别的效价-唤醒值)以及情感到效价-唤醒的映射文件。数据集适用于音频到音频、文本到语音和音频-文本到文本等任务,语言为英语。
Sympatheia-18k is an emotion-aware spoken dialogue dataset designed for empathetic speech synthesis research. The dataset contains 18,000 query-response pairs covering 12 emotion categories, each paired with synthetic audio and text transcriptions. The dataset is divided into two subsets: an emotion subset and a neutral subset. The emotion subset contains emotional queries paired with emotionally matched responses, while the neutral subset contains neutral queries, each paired with responses targeting all 12 emotion categories. The dataset files include audio files (in WAV format), metadata files (JSONL files containing text pairs and emotion labels), pre-encoded representation files (containing audio tokens, emotion labels, and valence-arousal values for each emotion category), and an emotion-to-valence-arousal mapping file. The dataset is suitable for tasks such as audio-to-audio, text-to-speech, and audio-text-to-text, and the language is English.
创建时间:
2026-05-01
原始信息汇总
Sympatheia-18k 数据集概述
基本信息
- 许可证:CC-BY-4.0
- 语言:英语
- 数据集大小:10K < n < 100K(共18,000对查询-回复)
- 任务类别:音频到音频、文本到语音、音频文本到文本
- 标签:情感、共情对话、语音合成、音频
数据集描述
Sympatheia-18k 是一个情感感知的口语对话数据集,专为共情语音合成研究设计。数据集包含18,000对查询-回复,覆盖12种情感类别,每对都配有合成的音频和文本转录。
数据集结构
| 子集 | 唯一查询数 | 回复数 | 描述 |
|---|---|---|---|
| Emotional | 训练8,400 / 评估3,600 | 训练8,400 / 评估3,600 | 情感查询配以情感匹配的回复 |
| Neutral | 训练350 / 评估150 | 训练4,200 / 评估1,800 | 中性查询每对配以12种情感目标回复 |
文件组成
- 音频文件:
{Emotional,Neutral}/audio/{train,eval}/目录下的WAV文件,命名格式为{LABEL}_{INDEX}_{EMOTION}.wav - 文本元数据:
{Emotional,Neutral}/metadata/text_pairs_{train,eval}.jsonl,包含查询-回复文本对,带有query_style和user_emotion标签 - 预编码音频令牌:
encoded_{train,eval}.jsonl,使用GLM-4-Voice解码器预编码,包含情感标签和每类情感的效价-唤醒值 - 情感映射文件:
{Emotional,Neutral}/metadata/emotion_va_mapping.json,每类情感到效价-唤醒的程序化映射
关键列说明
- query_style:合成查询音频时使用的TTS渲染风格。Emotional子集中反映说话者的情感表达;Neutral子集中始终为Neutral
- user_emotion:归属于用户的潜在情感,决定回复的语气和内容。Emotional子集中与query_style相同;Neutral子集中为推断的用户情感(尽管语音中性),是生成共情回复的主要信号
情感类别
包含12种离散情感:Angry(愤怒)、Anxious(焦虑)、Content(满足)、Disgusted(厌恶)、Excited(兴奋)、Frustrated(沮丧)、Happy(快乐)、Neutral(中性)、Relaxed(放松)、Sad(悲伤)、Surprised(惊讶)、Tired(疲惫)
相关项目
该数据集是为Sympatheia(情感感知共情语音对话系统)创建的。
搜集汇总
数据集介绍
构建方式
Sympatheia-18k数据集专为共情语音合成研究而设计,其构建方式融合了情感标签与语音数据的双重标注。数据集包含18,000组查询-回答对,覆盖12种情感类别,并细分为Emotional和Neutral两个子集。Emotional子集中,每条查询均由带有特定情感的语音合成,回答与之情感匹配;Neutral子集则以中性语态的查询为基础,为每条查询生成12种不同情感目标的回答。所有音频均以WAV格式存储,并配有文本转录JSONL元数据文件,同时提供基于GLM-4-Voice解码器预编码的音频token文件,便于直接用于模型训练。情感到价态-唤醒度的映射由程序定义,确保了情感维度的系统化标注。
使用方法
使用Sympatheia-18k数据集时,研究者可通过Hugging Face Datasets库加载配置,指定emotional或neutral子集,分别对应训练与评估分割。加载的JSONL元数据文件包含文本对及其情感标签,可直接用于训练文本到语音或语音到语音模型。对于需要音频特征的任务,预编码的encoded JSONL文件提供了GLM-4-Voice解码器输出的音频token,便于接入Sympatheia模型或其他语音生成框架。情感-价态映射文件则支持研究者将离散情感转换为连续维度,用于情感调节或多模态分析。数据集的标准化结构和情感标签体系,使其易于集成到现有共情对话研究流水线中。
背景与挑战
背景概述
Sympatheia-18k数据集由清华大学GLM团队创建于2024年,专注于共情语音对话系统中的情感感知研究。该数据集包含18,000组查询-响应对,覆盖12种离散情感类别,每个样本均配有合成语音和文本转录。通过情感子集与中性子集的对比设计,数据集揭示了用户隐式情感与显式表达之间的差异,为构建能够理解并回应用户深层情感状态的对话系统提供了基础资源。该数据集与Sympatheia系统紧密关联,推动了情感感知语音交互领域的发展,尤其在多模态共情对话生成方面具有重要影响力。
当前挑战
该数据集的核心挑战在于解决情感语音合成中的情感表达准确性与一致性难题。具体包括:1) 如何从中性语音中准确推断用户隐藏的深层情感,避免因情感误判导致不恰当的共情响应;2) 构建过程中需确保12种情感类别的语义区分度与自然度,避免合成语音过于夸张或模糊;3) 情感标签与声音风格的映射依赖程序化定义,缺乏人工标注校准,可能导致情感强度与真实场景偏差。此外,系统需在保持响应内容共情性的同时,实现情感与语义的严格对齐,这对模型的多层次理解能力提出了严苛要求。
常用场景
经典使用场景
Sympatheia-18k作为情感感知对话数据集,为共情语音合成研究提供了核心基准平台。该数据集精心设计了18,000组查询-响应对,覆盖12种离散情感类别,并附带合成音频与文本转录。其独特的两子集结构——情感匹配子集(Emotional)与中性查询多情感响应子集(Neutral)——使得研究者能够探索情感一致性对话生成与情感推断两种经典范式。尤其是Neutral子集中,相同中性语句被赋予不同用户情感标签,为训练模型从语言内容中捕捉隐性情感线索提供了理想训练素材,推动了共情语音交互领域标准化研究的发展。
解决学术问题
该数据集直面共情语音合成中情感理解与表达的关键挑战。传统语音合成多聚焦于文本内容的清晰度与自然度,而Sympatheia-18k通过细粒度的情感标签与多样化对话情景,使模型得以学习情感状态与语音韵律之间的映射关系。它有效解决了如何从用户中性表达中推断潜在情感状态这一学术难题,并支持探究响应语音中的情感匹配度与共情表达质量。该数据集的发布填补了多情感类别下共情对话数据稀缺的空白,为开发情感感知的端到端语音对话系统奠定了数据基础,推动了人机交互中情感智能的理论研究。
实际应用
在现实应用层面,Sympatheia-18k助力构建更具人文关怀的语音交互系统。该数据集可直接应用于情感客服对话生成,使智能助手不仅理解用户的语言内容,更能感知其愤怒、焦虑或难过等情绪状态,并以匹配的共情语气回应。在心理健康支持场景中,系统可利用该数据学习如何对用户的沮丧与疲惫做出温暖回应,提供初步的情感疏导。此外,该数据集还可用于虚拟角色对话、教育辅导助手以及面向老年用户的情感陪伴机器人,提升人机对话的情感真实性与用户满意度,推动情感计算技术从实验室走向日常生活。
数据集最近研究
最新研究方向
Sympatheia-18k数据集聚焦于情感感知的共情对话语音合成,代表了人机交互中情感计算与语音生成技术的交叉前沿。该数据集通过精心构建的18,000对查询-响应样本,覆盖12种离散情绪类别,并创新性地引入中性查询与多重情绪响应配对机制,为细粒度情感语音对话系统的训练提供了坚实基础。当前,该领域的核心研究方向在于如何利用此类高质量情感标注数据,驱动预训练语音模型(如GLM-4-Voice)实现更自然、更具情感传染力的共情交互。这一工作直接响应了智能语音助手向“情感无障碍”迈进的热点需求,其意义在于弥合机器语音表达与人类情感共鸣之间的鸿沟,推动共情计算从文本领域向多模态语音交互的实质性跨越。
以上内容由遇见数据集搜集并总结生成


