derek-thomas/ScienceQA|科学问答数据集|多模态推理数据集
收藏hugging_face2023-02-25 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/derek-thomas/ScienceQA
下载链接
链接失效反馈资源简介:
ScienceQA数据集是一个多模态的科学问答数据集,涵盖了多个学科领域,如化学、生物、物理、地球科学、工程、地理、历史、公民学、经济学、全球研究、语法、写作、词汇、自然科学、语言科学和社会科学等。数据集包含图像、问题、选择题选项、答案、提示、任务描述、年级、学科、主题、类别、技能、讲座和解决方案等多个字段。数据集主要用于多模态多项选择任务,支持的任务包括多选问答、封闭域问答、开放域问答、视觉问答和多类分类。数据集的创建目的是为了诊断AI系统的多跳推理能力和可解释性,特别是在科学问题回答中的应用。数据集的语言为英语,规模在10K到100K之间,分为训练集、验证集和测试集。
提供机构:
derek-thomas
原始信息汇总
数据集概述
数据集名称: ScienceQA
数据集大小: 27263474 字节
下载大小: 0 字节
语言: 英语
多语言性: 单语
许可: CC-BY-SA-4.0
任务类别:
- 多项选择
- 问答
- 其他
- 视觉问答
- 文本分类
任务ID:
- 多项选择QA
- 封闭领域QA
- 开放领域QA
- 视觉问答
- 多类分类
标签:
- 多模态QA
- 科学
- 化学
- 生物学
- 物理学
- 地球科学
- 工程
- 地理
- 历史
- 世界历史
- 公民学
- 经济学
- 全球研究
- 语法
- 写作
- 词汇
- 自然科学
- 语言科学
- 社会科学
数据集结构
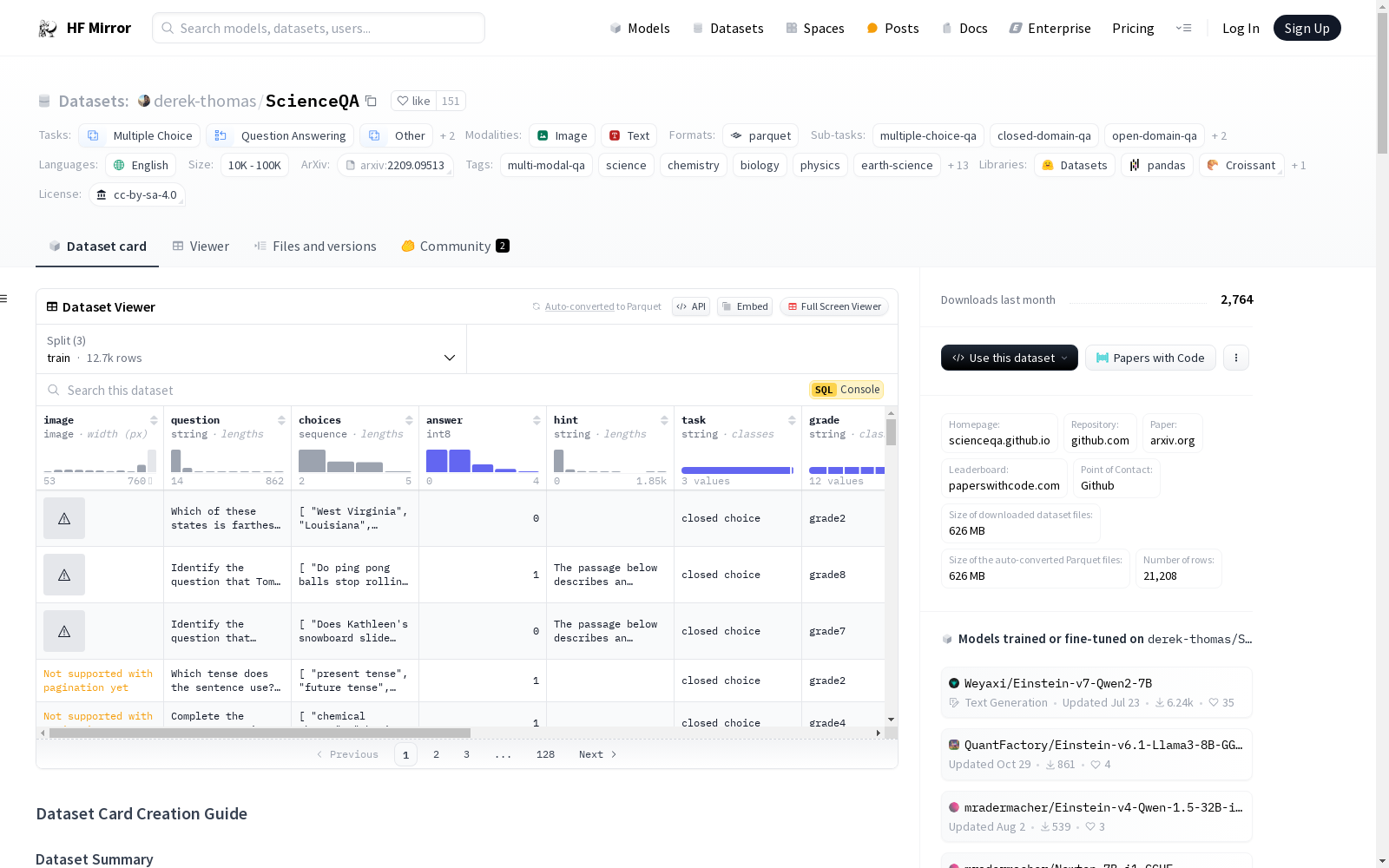
数据实例: 每个实例包含以下字段:
image:上下文图像question:与lecture相关的提示choices:与question相关的多选项答案,其中1个正确answer:对应正确答案的选项索引hint:帮助回答question的提示task:任务描述grade:K-12年级水平subject:高级别科目topic:自然科学、社会科学或语言科学category:topic的子类别skill:任务要求的描述lecture:question生成相关的讲座solution:解决question的说明
数据分割:
train:12726个实例,16416902字节validation:4241个实例,5404896字节test:4241个实例,5441676字节
数据集创建
来源数据: 数据集收集自小学和高中的科学课程。
注释过程: 问题来自IXL Learning的开放资源,由K-12教育领域的专家管理。数据集包括符合加州共同核心内容标准的问题。通过下载原始科学问题并根据启发式规则提取各个组件(如问题、提示、图像、选项、答案、讲座和解决方案)来构建ScienceQA。手动删除无效问题,如只有一个选项的问题、包含错误数据的问题和重复问题,以遵守公平使用和转换使用的法律。如果适用多个正确答案,则只保留一个正确答案。还对每个问题的答案选项进行洗牌,以确保选项不遵循任何特定模式。使用半自动脚本重新格式化讲座和解决方案,使文本中的特殊结构(如表格和列表)易于与简单文本段落区分。
注释者: 专家生成和发现。
AI搜集汇总
数据集介绍
构建方式
ScienceQA数据集的构建基于小学和高中科学课程,通过从IXL Learning等在线学习平台收集开放资源,并由K-12教育领域的专家进行筛选和整理。数据集包括与加州共同核心内容标准对齐的问题。构建过程中,原始科学问题被下载并根据启发式规则提取出各个组件,如问题、提示、图像、选项、答案、讲座和解决方案。无效问题,如只有一个选项或包含错误数据的问题,被手动移除以确保数据质量。答案选项经过随机排列,以避免特定模式。数据集通过半自动化脚本重新格式化讲座和解决方案,使其易于使用。
特点
ScienceQA数据集的主要特点在于其多模态性质,结合了图像和文本信息,涵盖了广泛的科学领域,包括化学、生物学、物理学、地球科学、工程学、地理学、历史、世界历史、公民学、经济学、全球研究、语法、写作、词汇、自然科学、语言科学和社会科学。数据集设计用于多选题、问答和其他任务,支持多种任务类别,如多选题问答、封闭领域问答、开放领域问答、视觉问答和多类分类。此外,数据集提供了详细的讲座和解决方案,帮助用户理解和解决科学问题。
使用方法
ScienceQA数据集适用于多种科学问答任务,包括多选题、问答和视觉问答。用户可以通过加载数据集的训练、验证和测试分割来训练和评估模型。数据集的特征包括图像、问题、选项、答案、提示、任务描述、年级、学科、主题、类别、技能、讲座和解决方案。用户可以根据需要选择和使用这些特征,以开发和测试多模态问答系统。数据集的许可证为CC BY-NC-SA 4.0,适用于非商业研究目的。
背景与挑战
背景概述
ScienceQA数据集由Pan Lu等研究人员于2022年创建,旨在通过多模态推理链解决科学问题回答中的复杂性。该数据集汇集了来自小学和高中科学课程的开放资源,由IXL Learning平台管理,并符合加州共同核心内容标准。ScienceQA的核心研究问题在于如何通过多模态数据(如图像、文本等)来增强AI系统的多跳推理能力和可解释性。其对科学教育领域的贡献在于提供了一个高质量、多领域、多模态的数据集,有助于推动AI在教育领域的应用和发展。
当前挑战
ScienceQA数据集在构建过程中面临多项挑战。首先,数据集需要从开放资源中提取和整合多模态信息,如图像、文本等,这要求高度的数据处理和整合能力。其次,确保数据集的多样性和覆盖广泛的教育领域,以避免偏见和局限性,是一项重要任务。此外,数据集的标注过程需要专家参与,以确保答案的准确性和解释的合理性。最后,数据集的使用需遵守非商业研究目的的限制,这可能限制其在商业应用中的推广和使用。
常用场景
经典使用场景
在科学教育领域,ScienceQA数据集被广泛用于开发和评估多模态问答系统。该数据集结合了图像和文本信息,为模型提供了丰富的上下文,使其能够处理复杂的科学问题。通过这种方式,研究人员可以构建能够解释和推理科学概念的智能系统,从而提升教育工具的互动性和有效性。
实际应用
在实际应用中,ScienceQA数据集被用于开发智能教育平台和辅助学习工具。例如,它可以用于构建个性化学习系统,根据学生的学习进度和理解能力提供定制化的科学问题和解答。此外,该数据集还可用于评估和改进现有教育软件的智能问答功能,从而提高教育资源的利用效率和学习效果。
衍生相关工作
基于ScienceQA数据集,研究人员开发了多种多模态问答模型,这些模型在科学教育、智能辅导系统和AI教育工具等领域取得了显著成果。例如,一些研究工作利用该数据集训练模型,使其能够生成详细的答案解释,从而增强模型的解释性和教育价值。此外,还有工作探索了如何将多模态信息融合到问答系统中,以提高其对复杂科学问题的处理能力。
以上内容由AI搜集并总结生成


