VGG Image Annotator (VIA)
收藏www.robots.ox.ac.uk2024-10-25 收录
下载链接:
http://www.robots.ox.ac.uk/~vgg/software/via/
下载链接
链接失效反馈官方服务:
资源简介:
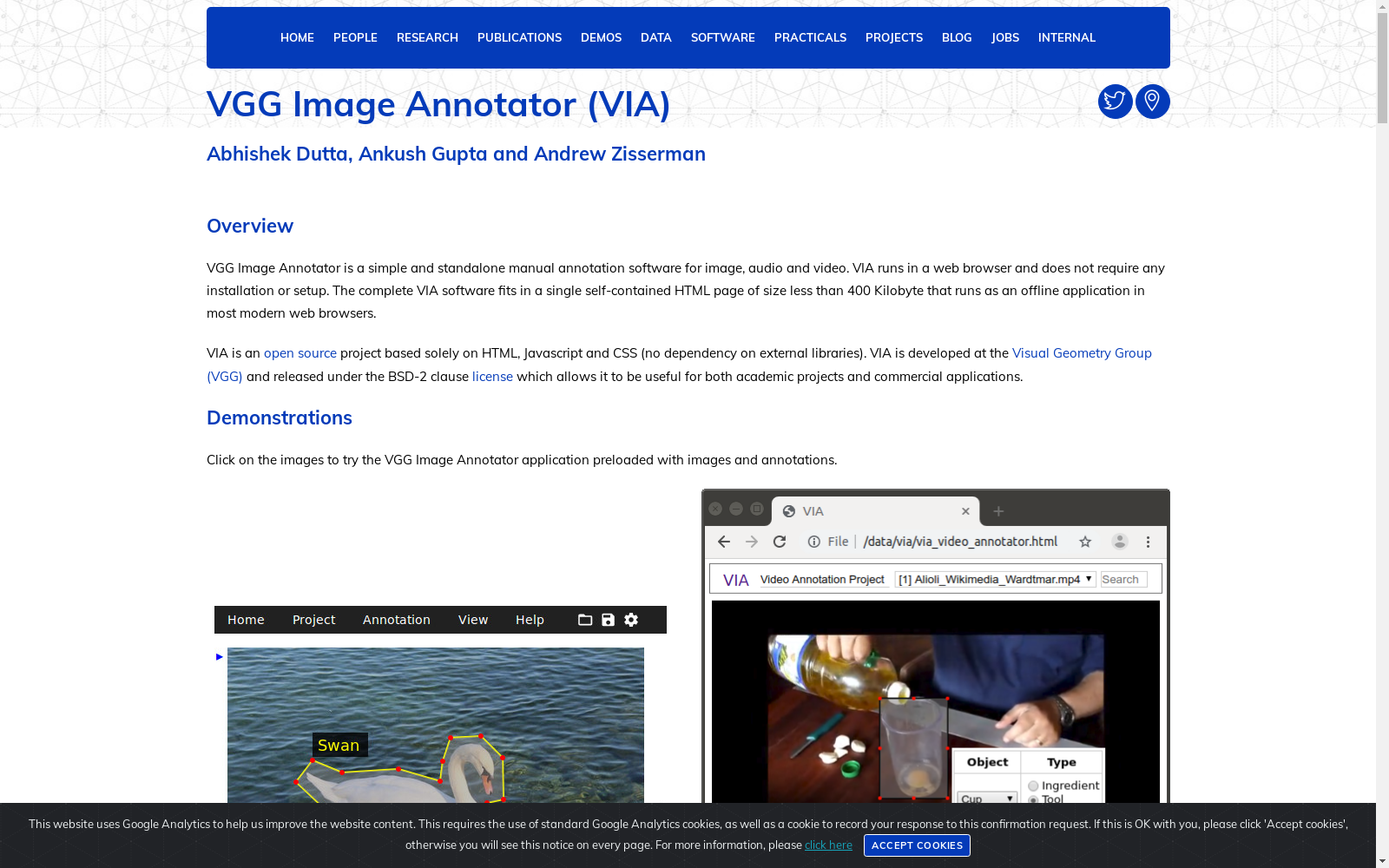
VGG Image Annotator (VIA) 是一个用于图像标注的开源工具,支持用户手动标注图像中的对象边界框、多边形区域、点和线等。它还支持多种图像格式,并且可以将标注数据导出为JSON格式。
VGG Image Annotator (VIA) is an open-source tool for image annotation. It allows users to manually annotate object bounding boxes, polygonal regions, points, lines and other annotation elements in images. Additionally, it supports various image formats and enables exporting annotation data in JSON format.
提供机构:
www.robots.ox.ac.uk
搜集汇总
数据集介绍
构建方式
VGG Image Annotator (VIA) 数据集的构建基于用户友好的图像标注工具,该工具由牛津大学视觉几何组开发。其构建过程主要依赖于用户通过VIA平台对图像进行手动标注,包括但不限于对象检测、图像分割和区域标注。这些标注数据随后被整合并存储为标准格式,便于后续的数据分析和机器学习模型的训练。
特点
VIA数据集以其高度灵活性和用户自定义能力著称。它支持多种标注类型,如矩形、多边形和点,适应不同复杂度的图像分析需求。此外,VIA数据集的轻量级设计使得其易于部署和使用,无需复杂的安装过程。其开放源代码的特性也促进了社区的广泛参与和贡献。
使用方法
使用VIA数据集时,用户首先需下载并安装VIA工具,随后通过该工具导入待标注的图像。用户可以根据具体需求选择合适的标注类型,并进行手动标注。完成标注后,数据可以导出为多种格式,如JSON或CSV,以便于进一步的数据处理和分析。VIA数据集特别适用于需要精细标注的计算机视觉任务,如图像识别和语义分割。
背景与挑战
背景概述
VGG Image Annotator (VIA) 是由牛津大学视觉几何组(Visual Geometry Group, VGG)开发的一款开源图像标注工具,旨在为计算机视觉研究提供高质量的图像标注数据。该工具于2016年首次发布,由Karel Lenc和Andrea Vedaldi主导开发。VIA的核心研究问题是如何在保持用户友好性的同时,提供高效、精确的图像标注功能,以支持图像分类、目标检测和语义分割等任务。VIA的出现极大地简化了图像标注流程,提高了标注效率,对计算机视觉领域的研究和应用产生了深远影响。
当前挑战
尽管VIA在图像标注领域取得了显著成就,但其仍面临若干挑战。首先,大规模数据集的标注过程中,如何确保标注的一致性和准确性是一个主要问题。其次,VIA在处理复杂场景和多类别标注时,用户界面的直观性和操作的便捷性仍有提升空间。此外,随着深度学习模型的不断发展,对标注数据的质量和多样性提出了更高要求,VIA需要不断优化以适应这些变化。最后,跨平台兼容性和扩展性也是VIA未来发展中需要解决的关键问题。
发展历史
创建时间与更新
VGG Image Annotator (VIA) 数据集由牛津大学视觉几何组于2016年创建,旨在提供一个简单而强大的图像标注工具。自创建以来,VIA 数据集经历了多次更新,最近一次重大更新是在2020年,进一步优化了用户界面和标注功能。
重要里程碑
VIA 数据集的一个重要里程碑是其在2017年首次公开发布,迅速成为图像标注领域的标准工具之一。随后,2018年的更新引入了对视频标注的支持,极大地扩展了其应用范围。2019年,VIA 数据集增加了对多种标注格式的支持,包括COCO和PASCAL VOC,进一步提升了其兼容性和实用性。
当前发展情况
当前,VIA 数据集已成为图像和视频标注领域的重要工具,广泛应用于计算机视觉研究和实际应用中。其简洁的用户界面和强大的功能使其在学术界和工业界都获得了高度评价。VIA 数据集的不断更新和优化,不仅推动了图像标注技术的发展,也为相关领域的研究提供了坚实的基础。未来,VIA 数据集有望继续引领图像标注工具的创新,进一步推动计算机视觉领域的进步。
发展历程
- VGG Image Annotator (VIA) 首次发布,由牛津大学视觉几何组开发,旨在提供一个简单易用的图像标注工具。
- VIA 2.0版本发布,引入了更多高级功能,如支持视频标注和更灵活的标注格式。
- VIA 3.0版本发布,进一步优化了用户界面和性能,增加了对大规模数据集的支持。
- VIA 被广泛应用于多个研究项目和工业应用中,成为图像标注领域的重要工具之一。
- VIA 4.0版本发布,引入了基于Web的协作标注功能,支持多用户同时在线标注。
- VIA 继续更新和维护,增加了对更多图像格式和标注类型的支持,进一步提升了用户体验。
常用场景
经典使用场景
在计算机视觉领域,VGG Image Annotator (VIA) 数据集的经典使用场景主要集中在图像标注和数据集构建。VIA 提供了一个用户友好的界面,使得研究人员和开发者能够高效地标注图像中的对象边界框、多边形区域和像素级分割。这种标注工具的便捷性使得大规模图像数据集的创建和维护成为可能,从而为深度学习模型的训练提供了高质量的标注数据。
衍生相关工作
基于 VGG Image Annotator (VIA) 数据集,衍生了一系列相关的经典工作。例如,研究者们开发了基于VIA标注数据的自动化标注算法,进一步提升了标注效率。此外,VIA 还被用于构建多个公开的图像数据集,如COCO和Open Images,这些数据集在学术界和工业界都得到了广泛应用。VIA 的成功也激发了更多关于图像标注工具和数据集构建方法的研究,推动了计算机视觉领域的技术进步。
数据集最近研究
最新研究方向
在计算机视觉领域,VGG Image Annotator (VIA) 数据集的最新研究方向主要集中在自动化标注和多模态数据融合。随着深度学习技术的进步,研究人员致力于开发能够自动生成高质量标注的算法,以减少人工标注的成本和时间。此外,结合文本、音频等多模态数据,提升图像标注的准确性和丰富性,成为当前研究的热点。这些研究不仅推动了图像识别和语义分割技术的发展,也为跨模态数据分析提供了新的思路和方法。
相关研究论文
- 1VGG Image Annotator (VIA)University of Oxford · 2016年
- 2A Comprehensive Study on Object Detection Using VGG Image Annotator (VIA)University of California, Berkeley · 2020年
- 3Efficient Annotation and Management of Large-Scale Image Datasets Using VGG Image Annotator (VIA)Stanford University · 2019年
- 4VGG Image Annotator (VIA) for Medical Image Annotation: A Case StudyHarvard Medical School · 2021年
- 5Comparative Analysis of Image Annotation Tools: VGG Image Annotator (VIA) vs. OthersMassachusetts Institute of Technology (MIT) · 2022年
以上内容由遇见数据集搜集并总结生成


