KET-QA
收藏arXiv2024-05-14 更新2024-06-21 收录
下载链接:
https://ketqa.github.io/
下载链接
链接失效反馈官方服务:
资源简介:
KET-QA是首个结合知识库作为外部知识源的表格问答数据集,由香港大学和微软共同创建。该数据集包含9421个问题,每个问题都需要结合表格和知识库子图来回答。数据集通过重新标注HybridQA中的自然人类创建问题,并替换外部知识源为Wikidata来构建。KET-QA旨在解决由于表格信息不完整或缺失导致的问答挑战,通过提供细粒度的黄金证据标注,推动对表格问答中外部知识需求的深入研究。
KET-QA is the first tabular question answering (QA) dataset that incorporates a knowledge base as an external knowledge source, jointly created by The University of Hong Kong and Microsoft. This dataset contains 9,421 questions, each of which requires answering by combining both tabular data and knowledge base subgraphs. It is constructed by re-annotating naturally human-generated questions from the HybridQA dataset and replacing the external knowledge source with Wikidata. KET-QA aims to address QA challenges caused by incomplete or missing tabular information, and promote in-depth research on the demand for external knowledge in tabular QA by providing fine-grained golden evidence annotations.
提供机构:
香港大学, 微软
创建时间:
2024-05-14
搜集汇总
数据集介绍
构建方式
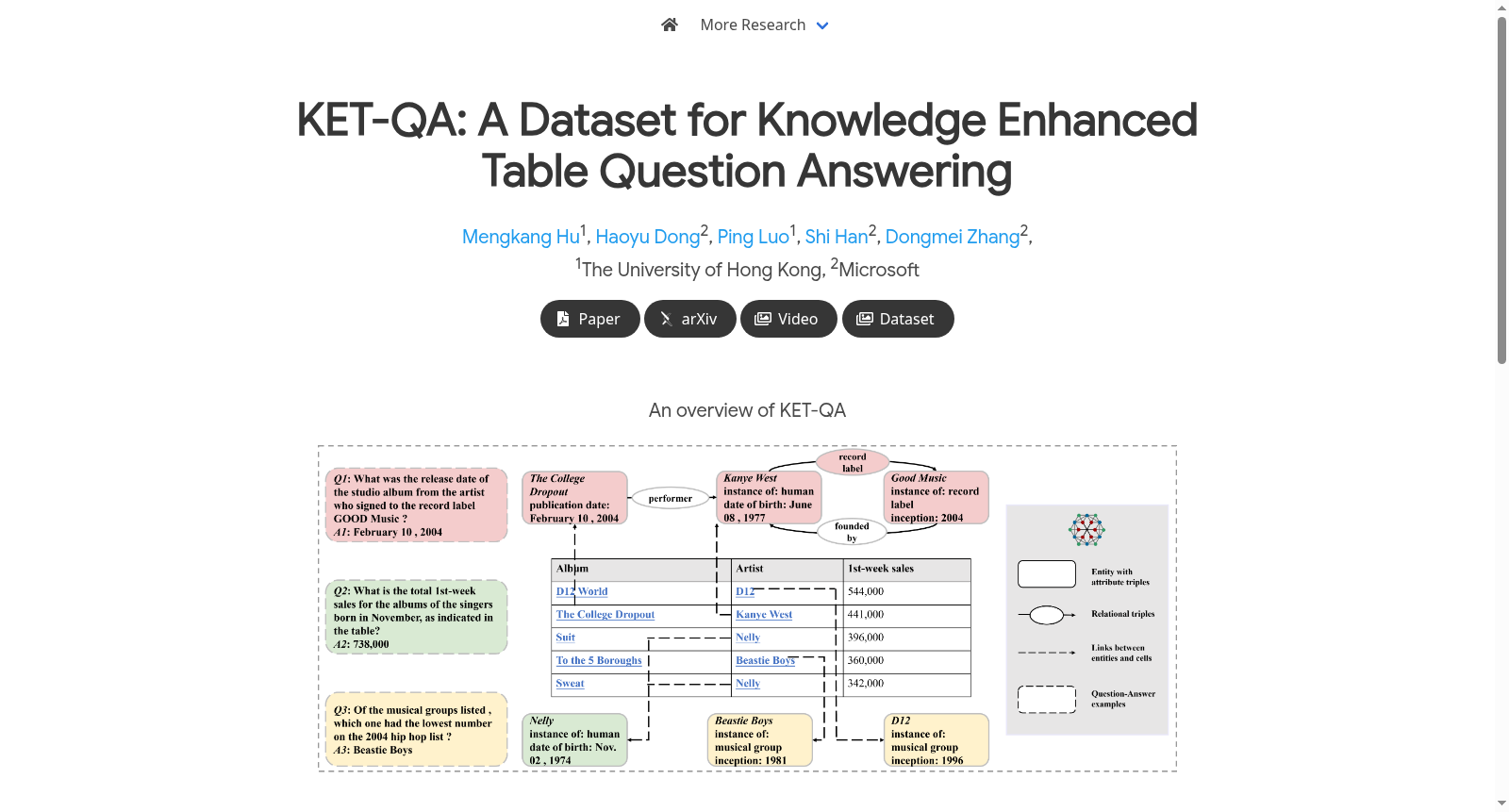
在表格问答领域,表格因其简洁结构常蕴含信息缺失,KET-QA数据集通过引入知识库作为外部知识源应对这一挑战。其构建始于HybridQA中的表格与问题对,利用维基百科页面与Wikidata实体间的映射关系,将表格超链接转换为知识库实体,进而为每个表格提取一跳子图作为补充信息。随后采用两阶段标注流程:首先筛选需结合表格与知识库方能解答的问题,确保样本自包含性;其次由标注者精细标注问题所需的黄金证据,即关联表格单元格与知识库三元组,最终通过专家审核与质量过滤,形成包含9,421个问题与5,721个表格的高质量数据集。
使用方法
为有效利用KET-QA,研究者通常采用检索器-推理器管道模型框架。检索器阶段,设计多阶段知识库检索器,先通过双编码器快速筛选候选三元组,再利用交叉编码器精细重排,以兼顾效率与精度,从庞大子图中提取问题相关证据。推理器阶段,将序列化的问题、表格及检索所得三元组联合输入预训练语言模型,生成最终答案。该流程支持微调、零样本和少样本等多种实验设置,显著提升模型性能,同时数据集的黄金证据标注可用于优化检索器训练,推动表格与知识库异构信息融合技术的前沿探索。
背景与挑战
背景概述
KET-QA数据集由香港大学与微软研究院于2024年联合推出,旨在解决表格问答(TableQA)中因表格信息高度结构化而导致的语义缺失问题。该数据集创新性地引入知识图谱作为外部知识源,通过将维基百科表格与Wikidata知识库实体对齐,构建了包含9421个问题与5721个表格的标注资源。其核心研究聚焦于如何融合半结构化表格与结构化知识图谱,以支持需要多源推理的复杂问答场景,为知识增强的表格理解研究提供了首个基准测试平台。
当前挑战
KET-QA面临的挑战主要体现在两方面:在领域问题层面,需解决表格与知识图谱的异构信息融合难题,包括从海量知识子图中精准检索相关三元组,并对文本、表格、图谱三类数据结构进行联合推理;在构建过程中,需克服表格与知识库实体映射的复杂性,以及人工标注高质量、需外部知识的问题-答案对时的高成本与一致性维护问题。当前最佳模型仅达到60.23%的精确匹配率,显著低于人类表现,凸显了该任务对问答系统的持续挑战性。
常用场景
经典使用场景
在表格问答研究领域,KET-QA数据集被广泛用于评估和开发需要外部知识增强的表格问答系统。其经典使用场景涉及模型必须同时理解半结构化表格内容与结构化知识图谱中的实体关系,以回答那些仅凭表格信息无法解决的复杂问题。例如,模型需结合表格中的艺术家姓名与知识图谱中的唱片公司签约信息,才能推断某专辑的发行日期。
解决学术问题
KET-QA主要解决了表格问答中因表格信息缺失或不完整而导致的推理瓶颈问题。传统数据集往往忽视外部知识的必要性,或仅以非结构化文本作为补充,而该数据集首次系统性地引入知识图谱作为外部知识源,并提供了细粒度的黄金证据标注。这使研究者能够深入探索如何有效检索与融合异构信息,推动了对知识增强型表格问答模型架构与训练方法的创新。
实际应用
在实际应用中,KET-QA可支撑智能数据分析系统、企业报表查询工具以及开放域问答平台,这些场景常需整合数据库表格与外部知识库以提供精准答案。例如,在金融分析中,系统可结合公司财报表格与行业知识图谱,回答关于企业股权结构或市场趋势的复合查询;在文化娱乐领域,它能协助从音乐榜单表格中关联艺人背景信息,满足用户对作品发布细节的深度追问。
数据集最近研究
最新研究方向
在表格问答领域,KET-QA数据集的推出标志着知识增强型表格理解研究迈入新阶段。该数据集首次将知识图谱作为外部知识源引入表格问答任务,通过精细标注的黄金证据,为模型融合结构化表格与知识图谱信息提供了基准。前沿研究聚焦于设计高效的检索-推理架构,以应对异构数据整合的挑战,例如多阶段知识检索器在提升召回率的同时优化了时间效率。热点探索涉及对比不同知识源(如大模型生成知识与非结构化文本)的效能,凸显了结构化知识在提升推理精确性与可解释性方面的优势。这一进展不仅推动了表格问答系统向更深层次的语义理解演进,也为跨模态信息融合研究提供了关键范式,对智能数据分析与决策支持系统具有深远影响。
相关研究论文
- 1KET-QA: A Dataset for Knowledge Enhanced Table Question Answering香港大学, 微软 · 2024年
以上内容由遇见数据集搜集并总结生成


