LiveXiv
收藏arXiv2024-10-15 更新2024-10-16 收录
下载链接:
https://huggingface.co/datasets/LiveXiv/LiveXiv
下载链接
链接失效反馈官方服务:
资源简介:
LiveXiv是一个基于arXiv论文内容的多模态实时基准数据集,由美国密歇根大学统计系等机构创建。该数据集通过自动生成视觉问答对(VQA)来测试大型多模态模型(LMMs)的能力,避免了传统数据集的污染问题。数据集的内容包括从arXiv论文中提取的图表、表格等多模态数据,并通过GPT-4o等模型生成问答对。创建过程中,数据集通过结构化文档解析和多模态模型过滤,确保了数据的质量和多样性。LiveXiv主要应用于评估和提升LMMs在科学领域的性能,旨在解决现有基准数据集的污染和更新问题。
LiveXiv is a real-time multimodal benchmark dataset built on arXiv paper content, developed by institutions including the Department of Statistics at the University of Michigan, USA, and other affiliated organizations. This dataset automatically generates visual question-answer pairs (VQA) to evaluate the capabilities of Large Multimodal Models (LMMs), thereby avoiding the dataset contamination problem plaguing traditional datasets. The dataset comprises multimodal data such as charts and tables extracted from arXiv papers, with question-answer pairs generated via models like GPT-4o. During its construction, the dataset underwent structured document parsing and multimodal model-based filtering to guarantee data quality and diversity. Primarily designed to assess and improve the performance of LMMs in scientific domains, LiveXiv aims to resolve the contamination and staleness issues associated with current benchmark datasets.
提供机构:
美国密歇根大学统计系
创建时间:
2024-10-15
搜集汇总
数据集介绍
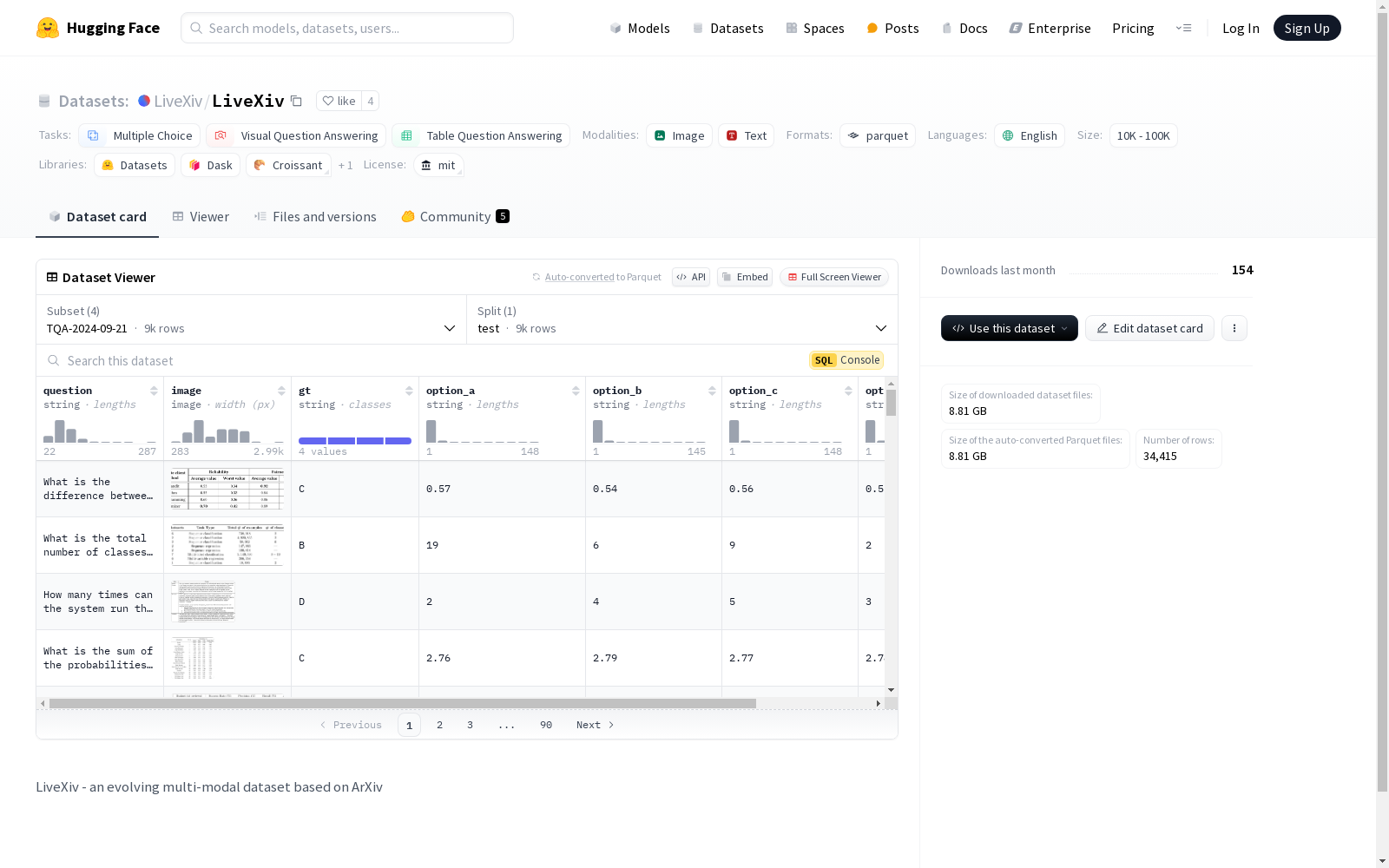
构建方式
LiveXiv数据集的构建基于ArXiv论文内容,采用多模态方式生成实时基准。该数据集通过自动抓取特定领域的科学手稿,利用多模态内容(如图表、表格等)生成视觉问答对(VQA)。整个过程无需人工干预,通过结构化文档解析管道提取相关信息,并使用GPT-4o模型生成问题和答案。为确保数据集的质量,还引入了广泛的过滤阶段,通过大型语言模型(LLM)和多模态模型(LMM)的协同验证,减少错误和幻觉。
特点
LiveXiv数据集的主要特点在于其全自动、实时更新的特性,能够有效避免测试数据污染问题。数据集不仅涵盖了广泛的科学领域,还通过高效的评估方法,显著降低了整体评估成本。此外,数据集的构建过程中采用了多模态内容生成和严格的过滤机制,确保了数据集的高质量和挑战性,能够真实反映多模态模型的能力。
使用方法
LiveXiv数据集适用于评估大型多模态模型(LMMs)在科学领域的性能。用户可以通过HuggingFace平台访问该数据集,并使用提供的代码进行模型评估。数据集的评估方法包括对模型的视觉问答(VQA)和表格问答(TQA)能力进行测试,通过多选题形式评估模型的准确性。此外,数据集还提供了一种高效的评估框架,通过重新评估一小部分模型来推断整体性能,从而节省计算资源。
背景与挑战
背景概述
在多模态模型的大规模训练中,从网络抓取的数据展现出卓越的实用性,使这些模型能够在多个下游任务中表现出色。然而,这种数据抓取的一个潜在缺点是可能牺牲了用于评估模型能力的基准的纯净性。为应对测试数据污染问题,并真实检验这些基础模型的能力,我们提出了LiveXiv:一个基于科学ArXiv论文内容的可扩展、不断演进的实时基准。LiveXiv通过自动生成视觉问答对(VQA)来实现这一目标,无需人工介入,利用手稿中的多模态内容,如图表和表格。此外,我们引入了一种高效的评估方法,通过仅评估模型子集来估算所有模型在不断演进的基准上的表现,从而显著降低了整体评估成本。
当前挑战
LiveXiv面临的主要挑战包括:1) 设计一个能够频繁、一致且自动更新的实时基准,即能够从网络抓取数据并将其转化为自动化评估的基准;2) 由于基准的不断演进,每次新版本发布时,所有参与模型都需要重新评估,这使得更新过程在时间和计算资源上都变得昂贵。这要求我们开发一种高效的评估方法,以减轻对所有模型在每个新版本数据集上进行评估的计算负担,并减少维护不可访问旧模型的物流开销。
常用场景
经典使用场景
LiveXiv数据集的经典使用场景在于评估多模态模型在科学领域文献中的视觉问答(VQA)能力。通过自动生成基于ArXiv论文内容的视觉问答对,LiveXiv提供了一个动态、不断更新的基准,用于测试模型在处理科学图表、图形和表格时的表现。这种自动化的数据生成和评估方法不仅减少了人工干预,还确保了测试数据的新鲜度和多样性,从而更准确地反映模型的实际能力。
解决学术问题
LiveXiv数据集解决了多模态模型在科学文献处理中的关键学术问题,即测试数据污染和模型能力的真实评估。传统的静态基准由于数据重复使用,容易导致模型在训练和测试数据之间出现重叠,从而高估模型的性能。LiveXiv通过持续更新和自动生成测试数据,有效避免了这一问题,为学术界提供了一个更为公正和准确的评估平台,有助于推动多模态模型在科学领域的应用和发展。
衍生相关工作
LiveXiv数据集的提出催生了一系列相关研究工作,特别是在多模态模型的评估和改进方面。例如,研究者们基于LiveXiv开发了新的评估方法,如基于项目反应理论(IRT)的模型性能预测,这些方法显著提高了评估效率。此外,LiveXiv还激发了对多模态模型在不同科学领域适应性的研究,推动了模型在处理特定类型科学数据时的优化和改进。这些衍生工作不仅丰富了多模态模型的研究内容,也为实际应用提供了更多可能性。
以上内容由遇见数据集搜集并总结生成


