Qwen-summarize-dataset-train
收藏Hugging Face2024-07-01 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/thepowerfuldeez/Qwen-summarize-dataset-train
下载链接
链接失效反馈官方服务:
资源简介:
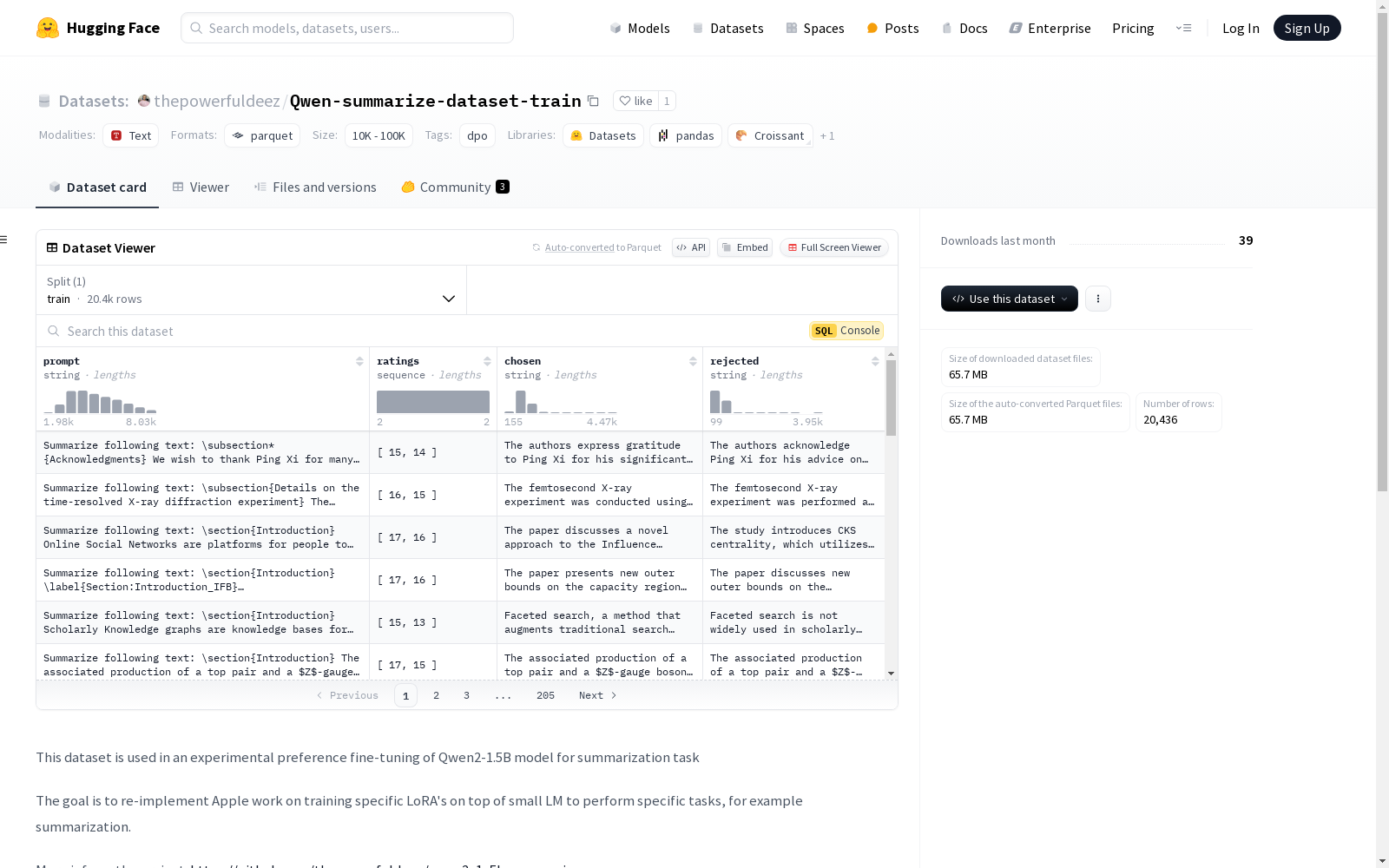
该数据集用于Qwen2-1.5B模型的偏好微调实验,特别是在摘要任务中。数据集包含四个主要特征:prompt(字符串类型),ratings(整数序列),chosen(字符串类型),和rejected(字符串类型)。数据集分为训练集,包含20436个样本,总大小为127692621字节。数据集的生成基于RedPajamaV2数据集的子集,筛选出特定长度的样本,并使用Qwen2-72B-Instruct模型生成合成偏好数据集,适用于DPO训练。数据集的生成遵循特定流程,包括文本摘要、提供两种不同长度的摘要、解释和评分,最终返回最佳摘要。
This dataset is intended for preference fine-tuning experiments of the Qwen2-1.5B model, particularly in the summarization task. It includes four core features: prompt (string type), ratings (integer sequence), chosen (string type), and rejected (string type). The dataset is split into a training set containing 20,436 samples with a total size of 127,692,621 bytes. It is generated based on a subset of the RedPajamaV2 dataset, where samples with specific lengths are filtered out. The Qwen2-72B-Instruct model is utilized to produce a synthetic preference dataset suitable for DPO training. The dataset generation follows a specific workflow, which consists of text summarization, providing two summaries of different lengths, conducting explanation and scoring, and finally returning the optimal summary.
创建时间:
2024-06-18
原始信息汇总
数据集概述
数据集信息
- 特征:
prompt: 字符串类型ratings: 整数序列类型chosen: 字符串类型rejected: 字符串类型
- 分割:
train: 包含127692621字节,20436个样本
- 下载大小: 65683578字节
- 数据集大小: 127692621字节
配置
- 默认配置:
- 数据文件路径:
data/train-*
- 数据文件路径:
标签
dpo
数据生成方法
- 数据来源: 从RedPajamaV2数据集中抽取1%的数据,筛选长度在900到1800个token之间的样本。
- 测试集: 文档长度在16000到100000个字符之间。
- 模型使用: 使用Qwen2-72B-Instruct生成合成偏好数据集,适用于DPO训练。
- 任务描述: 模型任务为总结文本摘录,提供两个不同长度的总结,解释,评分,并返回最佳总结。
- 数据筛选: 使用正则表达式解析模型输出,过滤掉总结过于相似(Levenshtein距离>0.75)和评分差异过小的样本。
- 提示标准: 部分提示标准来自GEval套件。
- 生成提示: 生成提示的链接为generation_prompt.txt。
搜集汇总
数据集介绍
构建方式
Qwen-summarize-dataset-train数据集的构建基于RedPajamaV2数据集中的Arxiv、Wikipedia和StackExchange文档,筛选出长度在900至1800个token之间的样本。通过使用Qwen2-72B-Instruct模型在Together.ai平台上生成适合DPO训练的合成偏好数据集。生成过程中,模型被要求对文本进行摘要,并提供两个不同长度的摘要,随后通过正则表达式解析输出,并过滤掉相似度过高或评分差异过小的样本。测试集则包含更长的文档,以确保数据集的多样性和挑战性。
使用方法
Qwen-summarize-dataset-train数据集主要用于文本摘要任务的模型微调,特别是基于DPO(Direct Preference Optimization)的实验。用户可以通过加载数据集中的train分割,获取包含prompt、ratings、chosen和rejected的样本,用于训练和评估模型。数据集的设计使其能够直接应用于偏好学习任务,帮助模型在生成摘要时更好地理解用户偏好。此外,测试集中的长文档样本可用于验证模型在处理复杂文本时的性能,进一步提升模型的泛化能力。
背景与挑战
背景概述
Qwen-summarize-dataset-train数据集是为Qwen2-1.5B模型在摘要任务中的偏好微调而设计的实验性数据集。该数据集的创建灵感来源于苹果公司在小型语言模型上训练特定LoRA(低秩适应)以实现特定任务的研究工作。数据集的主要目标是通过生成合成偏好数据,支持直接偏好优化(DPO)训练,从而提升模型在文本摘要任务中的表现。数据集的构建基于RedPajamaV2数据集中的Arxiv、Wikipedia和StackExchange文档,经过筛选和处理后,使用Qwen2-72B-Instruct模型生成合成数据。这一研究为小型语言模型在特定任务上的优化提供了新的思路和方法。
当前挑战
Qwen-summarize-dataset-train数据集在构建过程中面临多重挑战。首先,生成合成偏好数据需要确保输入文本的长度在模型的最大输入限制(32k tokens)内,同时保证生成的摘要具有足够的多样性和质量。其次,数据过滤过程中需通过Levenshtein距离和评分差异等指标,剔除过于相似或评分差异过小的样本,以确保数据的有效性和多样性。此外,数据集的构建依赖于外部模型和计算资源,成本控制和技术实现的复杂性也是不可忽视的挑战。这些挑战不仅影响了数据集的生成效率,也对后续模型的训练和优化提出了更高的要求。
常用场景
经典使用场景
Qwen-summarize-dataset-train数据集在自然语言处理领域中的经典使用场景是用于文本摘要任务的模型微调。通过该数据集,研究人员可以训练和优化语言模型,使其能够生成高质量的文本摘要。数据集中的样本经过精心筛选和处理,确保了摘要的多样性和质量,适用于各种文本摘要任务。
解决学术问题
该数据集解决了文本摘要任务中模型生成摘要质量不一致的问题。通过提供带有评分和选择的摘要对,数据集帮助研究人员更好地理解和优化模型在生成摘要时的偏好和决策过程。这不仅提升了摘要的准确性,还增强了模型在不同文本类型上的泛化能力。
实际应用
在实际应用中,Qwen-summarize-dataset-train数据集被广泛用于新闻摘要、学术论文摘要以及技术文档摘要等领域。通过使用该数据集训练的模型,企业和研究机构能够自动化生成高质量的摘要,极大地提高了信息处理的效率和准确性。
数据集最近研究
最新研究方向
在自然语言处理领域,Qwen-summarize-dataset-train数据集的最新研究方向聚焦于基于偏好微调的小型语言模型在文本摘要任务中的应用。该数据集通过从RedPajamaV2数据集中筛选特定长度的文档,并利用Qwen2-72B-Instruct模型生成合成偏好数据,旨在优化直接偏好优化(DPO)训练过程。这一研究方向不仅推动了小型语言模型在特定任务上的性能提升,还为文本摘要领域提供了新的数据生成方法。通过结合GEval套件的评价标准,该数据集在生成高质量摘要的同时,确保了数据的多样性和差异性,为未来的文本摘要研究提供了重要的数据支持。
以上内容由遇见数据集搜集并总结生成


