CODP-1200
收藏github2024-01-31 更新2024-05-31 收录
下载链接:
https://github.com/Leng-bingo/Chinese-Child-Captions
下载链接
链接失效反馈官方服务:
资源简介:
目前已知最大的儿童图像描述数据集,共有1200张图片,每张图片对应五个中文描述,每两张图片为一组,描述文字总数为3000。
The largest known dataset of image descriptions for children, comprising a total of 1,200 images. Each image is accompanied by five Chinese descriptions, with every two images forming a pair, resulting in a total of 3,000 descriptive texts.
创建时间:
2023-05-31
原始信息汇总
CODP-1200数据集概述
数据集名称
CODP-1200:Children Oral Description of Picture(Chinese-Child-Captions)
数据集描述
- 规模:目前已知最大的儿童图像描述数据集。
- 图片数量:共有1200张图片。
- 描述内容:每张图片对应五个中文描述,每两张图片为一组。
- 描述文字总量:3000条。
数据集用途
用于辅助儿童语言学习的AIGC基准。
引用信息
若使用此数据集,请引用以下文章: latex @article{LENG2024102627, title = {CODP-1200: An AIGC based benchmark for assisting in child language acquisition}, journal = {Displays}, volume = {82}, pages = {102627}, year = {2024}, issn = {0141-9382}, doi = {https://doi.org/10.1016/j.displa.2023.102627}, url = {https://www.sciencedirect.com/science/article/pii/S0141938223002615}, author = {Leng, Guannan and Zhang, Guowei and Xiong, Yu-Jie and Chen, Jue} }
搜集汇总
数据集介绍
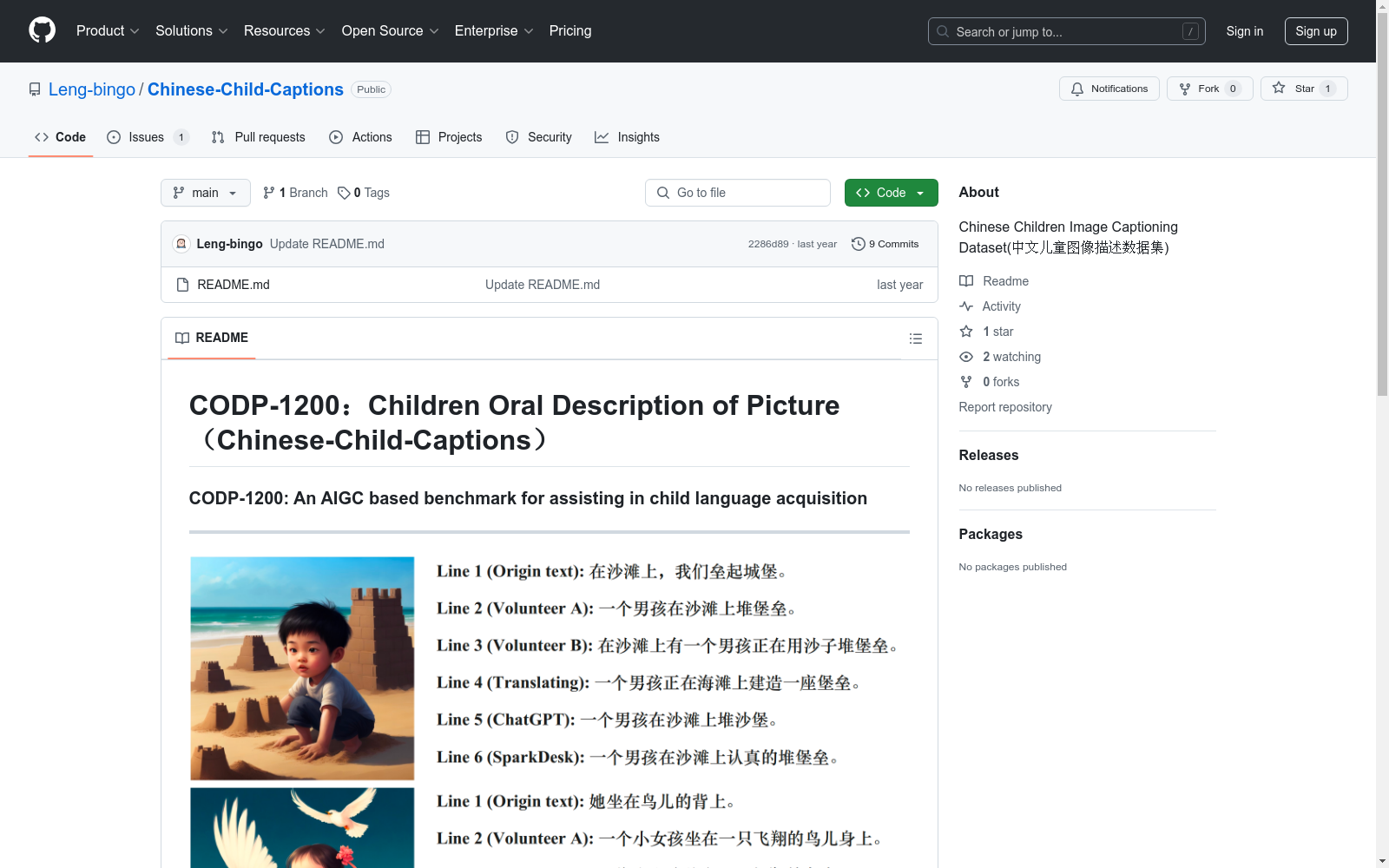
构建方式
CODP-1200数据集的构建基于儿童对图像的描述,旨在为儿童语言习得提供支持。该数据集包含1200张图片,每张图片由五名儿童分别进行中文描述,形成共计3000条描述文本。图片以每两张为一组进行组织,确保数据的多样性和丰富性。数据集的构建过程严格遵循科学方法,确保每一条描述的真实性和有效性。
特点
CODP-1200数据集是目前已知最大的儿童图像描述数据集,具有显著的代表性和广泛的应用前景。其独特之处在于每张图片对应五个不同的中文描述,充分展现了儿童语言的多样性和创造力。数据集的图片和描述文本经过精心筛选和整理,确保了高质量和一致性。此外,数据集的构建基于AIGC技术,为儿童语言习得研究提供了新的视角和工具。
使用方法
CODP-1200数据集的使用方法简便易行,用户可通过提供的百度网盘链接进行下载。数据集适用于儿童语言习得、自然语言处理、图像描述生成等多个研究领域。在使用过程中,建议用户遵循数据集的引用规范,引用相关文献以确保学术诚信。数据集的结构清晰,图片和描述文本的对应关系明确,便于用户进行数据分析和模型训练。
背景与挑战
背景概述
CODP-1200数据集由Leng Guannan等人于2024年创建,旨在为儿童语言习得研究提供一个基于人工智能生成内容(AIGC)的基准。该数据集是目前已知最大的儿童图像描述数据集,包含1200张图片,每张图片对应五个中文描述,共计3000条描述文字。CODP-1200的构建不仅为儿童语言发展研究提供了丰富的语料资源,还为人工智能在儿童教育领域的应用奠定了数据基础。该数据集的研究成果发表在《Displays》期刊上,标志着儿童语言习得与人工智能交叉研究的重要进展。
当前挑战
CODP-1200数据集在解决儿童语言习得问题的过程中面临多重挑战。首先,儿童语言表达的多样性和复杂性使得数据采集和标注过程异常困难,需要确保描述内容的准确性和自然性。其次,构建过程中需克服儿童参与数据采集的伦理和隐私保护问题,确保数据采集过程的合规性和安全性。此外,如何利用AIGC技术生成高质量的儿童语言描述,同时避免生成内容的偏差和错误,也是数据集构建中的一大技术难题。这些挑战不仅考验了研究团队的技术能力,也对儿童语言习得研究提出了更高的要求。
常用场景
经典使用场景
CODP-1200数据集在儿童语言习得研究中扮演了重要角色。该数据集通过提供1200张图片及其对应的中文描述,为研究者提供了一个丰富的资源库,用于分析和理解儿童在描述图像时的语言表达模式。这一数据集特别适用于开发基于人工智能的儿童语言学习辅助工具,帮助儿童通过图像描述练习提升语言能力。
衍生相关工作
基于CODP-1200数据集,研究者们已经开展了一系列相关研究,包括儿童语言模型训练、图像描述生成算法优化等。这些研究不仅推动了人工智能在儿童教育领域的应用,还为儿童语言习得研究提供了新的视角和方法。CODP-1200数据集的发布,极大地促进了相关领域的学术交流和技术进步。
数据集最近研究
最新研究方向
在儿童语言习得领域,CODP-1200数据集作为目前已知最大的儿童图像描述数据集,为研究者提供了丰富的资源。该数据集包含1200张图片,每张图片对应五个中文描述,共计3000条描述文字。这些数据不仅为儿童语言习得研究提供了宝贵的素材,还为基于生成式人工智能(AIGC)的辅助学习工具开发奠定了基础。近年来,随着AIGC技术的快速发展,CODP-1200数据集在儿童语言教育中的应用前景备受关注。研究者们正积极探索如何利用该数据集开发智能化的语言学习系统,以提升儿童的语言表达和理解能力。此外,该数据集还为跨学科研究提供了新的视角,推动了心理学、教育学与计算机科学的深度融合。CODP-1200数据集的发布,标志着儿童语言习得研究迈入了一个新的阶段,具有重要的学术价值和实际应用意义。
以上内容由遇见数据集搜集并总结生成


